







 在使用PySpark处理JSON数据时,一位开发者遇到了Windows环境下资源模块不可用的问题。通过回退到PySpark 2.3.2版本,成功解决了在Jupyter Notebook中运行代码时出现的错误。
在使用PySpark处理JSON数据时,一位开发者遇到了Windows环境下资源模块不可用的问题。通过回退到PySpark 2.3.2版本,成功解决了在Jupyter Notebook中运行代码时出现的错误。
最近在本地装了一个pyspark,在运行的过程中,总会遇到这样的报错。这是jupter notebook的cmd窗口。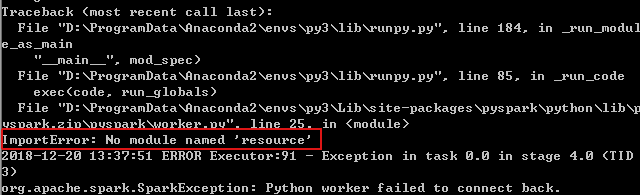
以下是我运行的一段代码
stringJSONRDD = sc.parallelize(("""
{ "id": "123",
"name": "Katie",
"age": 19,
"eyeColor": "brown"
}""",
"""{
"id": "234",
"name": "Michael",
"age": 22,
"eyeColor": "green"
}""",
"""{
"id": "345",
"name": "Simone",
"age": 23,
"eyeColor": "blue"
}""")
)
swimmersJSON = spark.read.json(stringJSONRDD)
我就开始好奇哪里bug了,原来发现在我这个版本的spark中确实是引用了resource
在Stack Overflow上,我找到了答案
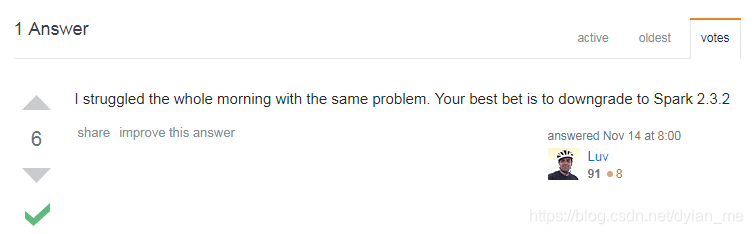
pyspark版本太高,其中的resource模块在windows上是不可用的,退回到2.3.2就可以了。

















 4808
4808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









