







 本文讲解了使用Pandas进行数据连接与修补的方法,包括concat函数的行与列连接、join参数的选择、数据修补的combine_first方法及update函数的使用。
本文讲解了使用Pandas进行数据连接与修补的方法,包括concat函数的行与列连接、join参数的选择、数据修补的combine_first方法及update函数的使用。
上一篇博文讲了怎样通过merge 和 join 合并数据,这一篇讲一下数据的连接与修补方法
(1)连接–concat
分为按行连接和按列连接,默认为按行连接
生成Series数组
s1 = pd.Series([1,2,3])
s2 = pd.Series([2,3,4])
s3 = pd.Series([1,2,3],index = ['a','c','h'])
s4 = pd.Series([2,3,4],index = ['b','e','d'])
print(s1)
print('--------')
print(s2)
print('--------')
print(s3)
print('--------')
print(s4)
输出结果:

按行连接
print(pd.concat([s1,s2]))
print(pd.concat([s3,s4]).sort_index())
输出结果:

按列连接
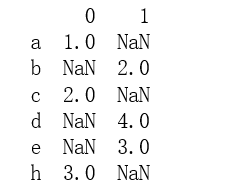
print(pd.concat([s3,s4], axis=1))
输出结果:
(2)连接方式–join,join_axes
通过join参数来选择连接时是选并集还是补集,通过join_axes参数来选择连接的index
创建Series
s5 = pd.Series([1,2,3],index = ['a','b','c'])
s6 = pd.Series([2,3,4],index = ['b','c','d'])
指定连接方式
print(pd.concat([s5,s6], axis= 1))
print(pd.concat([s5,s6], axis= 1, join='inner'))
print(pd.concat([s5,s6], axis= 1, join_axes=[['a','b','d']]))
输出结果:

(3)覆盖列名
连接之后我们可以给数据指定新的key序列名,默认是没有的
sre = pd.concat([s5,s6], keys = ['one','two'])
print(sre,type(sre))
print(sre.index)
输出结果:

axis=1的时候覆盖列名
sre = pd.concat([s5,s6], axis=1, keys = ['one','two'])
print(sre,type(sre))
输出结果:

(4)数据修补
做数据分析的时候我们经常需要做一些数据修补工作,pandas里面通过pd.combine_first( ) 实现
创建含空值的Dataframe
df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],[np.nan, 7., np.nan]])
df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]],index=[1, 2])
print(df1)
print(df2)
输出结果:

数据修补,根据index值,df1里面的空值用df2修补
print(df1.combine_first(df2))
输出结果:

更新df1,直接用df2覆盖df1,在相同index的位置
df1.update(df2)
print(df1)
输出结果:

今天就到这里啦~
我是一位211高校在读的本科生,是个耿直GIRL,对数据分析比较感兴趣,去年拿到了数学建模国家一等奖,今年参加了美赛还没结果,参加比赛选的题型都是大数据型,用过Excel,Spss,Lingo,MATLAB做数据分析,现在觉得Python比较高效,做数据可视化也非常方便,每天都在坚持学习,对Python数据分析和数据可视化有兴趣的可以关注我哦,每天都会更新的,跟我一起进步呀


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









