







前面的博客写了Pandas中文本数据的处理方法,这篇博客来写一下数据的合并方法,做数据分析的话这部分还是蛮重要的,建议好好看一下
Pandas具有全功能的,高性能内存中的连接操作,与SQL等数据库非常的相似
(1)merge合并
创建几个Dataframe
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df3 = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df4 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
输出结果:

通过一个参考键合并数据,默认取交集
print(pd.merge(df1, df2, on='key'))
输出结果:

通过多个参考键合并数据,默认取交集
print(pd.merge(df3, df4, on=['key1','key2']))
输出结果:

(2)不同的合并方式
数据合并方法有取交集,取并集等,我们主要是通过‘how’参数来控制
print(pd.merge(df3, df4,on=['key1','key2'], how = 'inner'))
print('------')
# inner:默认,取交集
print(pd.merge(df3, df4, on=['key1','key2'], how = 'outer'))
print('------')
# outer:取并集,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'left'))
print('------')
# left:按照df3为参考合并,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'right'))
# right:按照df4为参考合并,数据缺失范围NaN
输出结果:

(3)单独设置左键与右键
当参考键不是一个列时,我们可以单独设置左参考键与右参考键,主要通过left_on,left_right,left_index和right_index来设置
创建两个Dataframe
df1 = pd.DataFrame({'lkey':list('bbacaab'),
'data1':range(7)})
df2 = pd.DataFrame({'rkey':list('abd'),
'date2':range(3)})
print(df1)
print('-----------')
print(df2)
输出结果:

合并df1,df2,且,df1以‘lkey’为参考键,df2以‘rkey’为参考键
print(pd.merge(df1, df2, left_on='lkey', right_on='rkey'))
输出结果:

创建两个新的Dataframe
df1 = pd.DataFrame({'key':list('abcdfeg'),
'data1':range(7)})
df2 = pd.DataFrame({'date2':range(100,105)},
index = list('abcde'))
print(df1)
print('--------')
print(df2)
输出结果:

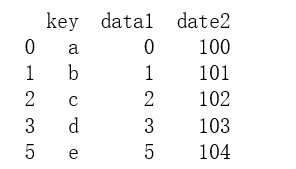
合并df1和df2且,df1以‘key’为参考键,df2以index为参考键,这里用过right_index 参数来设置
print(pd.merge(df1, df2, left_on='key', right_index=True))
输出结果:
(4)参数:sort
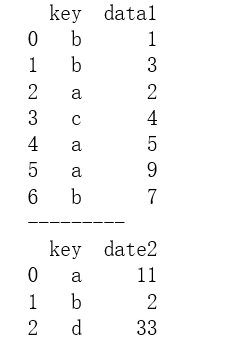
sort为按照字典顺序通过参考键对合并后的Dataframe结果进行排序,默认为False
df1 = pd.DataFrame({'key':list('bbacaab'),
'data1':[1,3,2,4,5,9,7]})
df2 = pd.DataFrame({'key':list('abd'),
'date2':[11,2,33]})
print(df1)
print('---------')
print(df2)
输出结果:
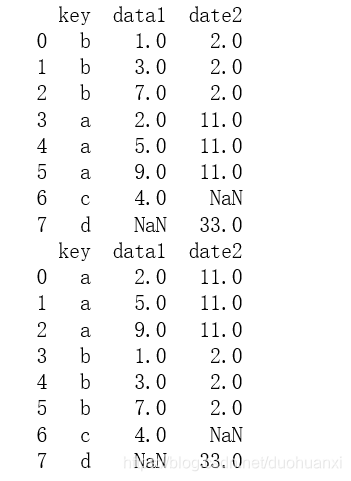
连接df1与df2
x1 = pd.merge(df1,df2, on = 'key', how = 'outer')
x2 = pd.merge(df1,df2, on = 'key', sort=True, how = 'outer')
print(x1)
print(x2)
输出结果:
将sort参数设置为False会大幅提高程序的运行效率,但是设置为True会更方便我们的处理
(5)直接通过索引连接
我们也可以通过pd.join( ) 函数直接通过索引链接Dataframe
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
print(left)
print(right)
输出结果:

通过join( ) 链接
print(left.join(right))
print(left.join(right, how='outer'))
输出结果:

今天就到这里啦~
我是一位211高校在读的本科生,是个耿直GIRL,对数据分析比较感兴趣,去年拿到了数学建模国家一等奖,今年参加了美赛还没结果,参加比赛选的题型都是大数据型,用过Excel,Spss,Lingo,MATLAB做数据分析,现在觉得Python比较高效,做数据可视化也非常方便,每天都在坚持学习,对Python数据分析和数据可视化有兴趣的可以关注我哦,每天都会更新的,跟我一起进步呀


















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









