









 本文介绍如何使用Python对商铺数据集进行读取、清洗和初步分析,包括处理缺失数据、转换字段格式及拆分复合字段。
本文介绍如何使用Python对商铺数据集进行读取、清洗和初步分析,包括处理缺失数据、转换字段格式及拆分复合字段。
前面几篇我们介绍了关于Python的一些基础知识,从今天开始我们开始学习怎样通过Python进行数据分析,今天我们通过前面的学习对商铺数据集进行简单的整理分析。
先来看一下数据格式:
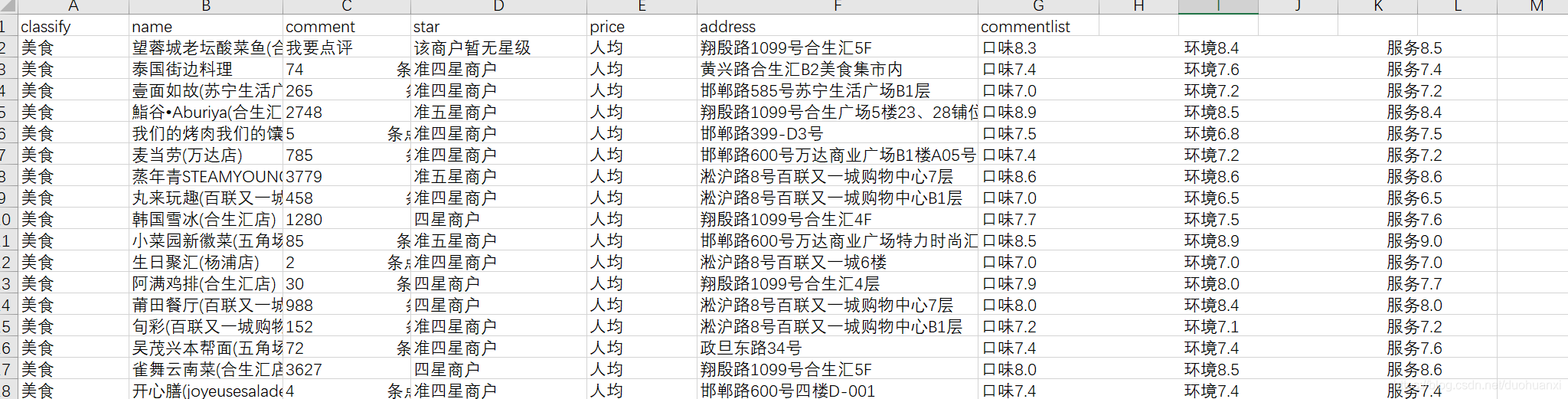
这个数据是大众点评的数据,里面包括了店铺名称,地址,口味评分,环境评分,服务评分等信息,对这个数据集我们希望可以达到以下目的:
(1)成功读取‘商铺数据.csv’文件
(2)解析数据,存储成字典格式
(3)数据清洗:coment,price两个字段清洗为数字格式、删除字段缺失的数据、commenrlist拆分成三个字段,并且清洗成数字
现在我们通过Python来达到以上目的。
(1)读取数据
path=r'C:\Users\XXX\Desktop\商铺数据.csv'#工作路径
f_r=open(path,'r',encoding='utf8')#读取商铺数据
for i in f_r.readlines()[:100]:#查看前一百行数据
print(i.split(',')[-1])#通过‘,’将数据集中最后一列即comentlist列拆分
f_r.seek(0)#将光标定位到0字符,这一部很重要,每次读取数据后光标自动定位到文件最后输出结果:

(2)数据清洗
这一部分我们分别对coment和price字段分别清洗,通过观察原始数据我们发现,对于comment数据列,当数据缺少 字符‘条’的时候,很大的概率是空数据或缺失数据,所以对于comment清洗时,我们采用以下方法:
def fcm(s):#定义清洗函数
if '条' in s:#查找缺失的数据
return(int(s[0]))
else:
return('缺失数据')
for i in f_r.readlines()[:10]:#查看前十行数据
cm=fcm(i.split(',')[2])#数据清洗
print(cm)
f_r.seek(0)#光标定位到0字符输出结果:

对price字段清洗的时候,我们发现当数据缺少字符‘¥’时,该数据为空数据或缺失数据,所以对price字段清洗是,我们采用以下方法:
def fpr(s):#定义清洗函数
if '¥' in s:#查找缺失的数据
return(int(s.split('¥')[-1]))
else:
return('缺失数据')
for i in f_r.readlines()[:10]:#查看前十行数据
pr=fpr(i.split(',')[4])
print(pr)
f_r.seek(0)#光标定位到0字符输出结果:

(3)拆分commenrlist字段
数据拆分时我们仍然使用split()函数,代码如下:
def fcf(s):#定义拆分函数
if len(s)==3:
quality=float(s[0][2:])
enviroment=float(s[1][2:])
service=float(s[2][2:])
return([quality,enviroment,service])
else:
return('缺失数据')
for i in f_r.readlines()[:10]:
cf=fcf(i.split(',')[-1].split(' '))#嵌套拆分
print(cf)
f_r.seek(0)输出结果:

(4)得到最终表格数据
datalst=[]#创建列表
f_r.seek(0)#光标定位到0字符
n=0#设置计数
for i in f_r.readlines()[1:20]:#加载前20行数据
data=i.split(',')#通过‘,’将表格拆分为若干列
classfy=data[0]#美食列
name=data[1]#商铺名称
com_count=fcm(data[2])#点评数量
star=data[3]#星级
price=fpr(data[4])#人均消费
add=data[5]#商铺地址
qua=fcf(data[-1].split(' '))[0]#口味评分
env=fcf(data[-1].split(' '))[1]#环境评分
service=fcf(data[-1].split(' '))[2]#服务评分
if '缺失数据' not in [com_count,price,qua]:
n+=1
data_lst2=[['classfy',classfy],
['name',name],
['com_count',com_count],
['star',star],
['price',price],
['add',add],
['qua',qua],
['env',env],
['service',service]]
datalst.append(dict(data_lst2))
print('成功读取%i条数据'%n)
print(dict(data_lst2))#转为字典格式
else:
continue
f_r.close()
print('完成')
print('总共加载%i条数据'%n)输出结果:

因为还没有学numpy和pandas等数据分析模块,所以我们做的比较简陋,等后面学了这些模块后会更简单
今天的分享就到这里吧,开始学这些基础的东西都是比较枯燥的,但是这些基础的东西学不好的话后面做那些炫酷的图表就比较困难哦,有问题可以私信我呀,看到都会回的,没回就是在写作业啦~
本人是一位211高校在读的本科生,对数据分析比较感兴趣,去年拿到了数学建模国家一等奖,今年参加了美赛还没结果,参加比赛选的题型都是大数据型,用过Excel,Spss,Lingo,MATLAB做数据分析,现在觉得Python比较高效,做数据可视化也非常方便,每天都在坚持学习,对Python数据分析和数据可视化有兴趣的可以关注我哦,每天都会更新的,跟我一起进步呀



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









