



据 IDC 报告,全球 78% 的数据是非结构化数据,预计到 2028 年将增长至 10.5ZB,然而这些数据中大量信息仍处于“沉睡”状态,既未被利用,还带来了庞大的存储与治理成本。
在数据、工具与组织机制之间实现深度耦合,已不再是战略性选择题,而是决定企业能否迈入智能时代的“生存级”必答题。
正如 IDC 全球数据研究项目经理 Adam Wright 所言:“企业必须加速投资先进的数据管理策略,以更高效地存储、处理,并释放这一多样化且不断演化的数据生态系统的潜力”。
文档解析:通往 AGI 之路上的“隐形瓶颈”
关于 AGI 的讨论甚嚣尘上,从 RLHF 到 RLVR,大模型在复杂任务上展现出惊人潜力。然而,在通往 AGI 的道路上,一个被低估但至关重要的环节,却常常成为瓶颈——那就是文档解析。
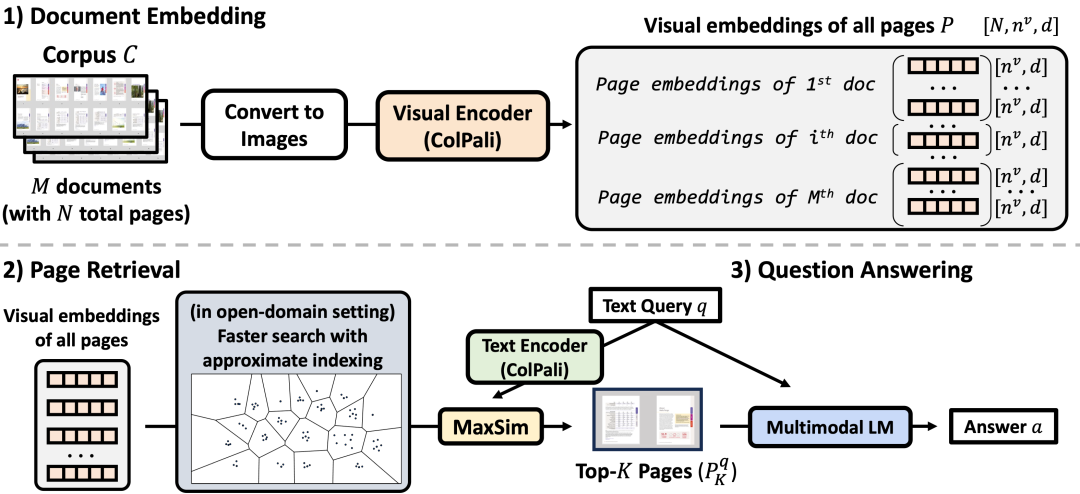
现实中的文档(比如 PDF、扫描图像)往往不是规整的,它们有多栏排版、复杂表格、图文混排、跨页元素等。目前市面上有开源和专有的解决方案,但很少能真正实现准确性、可扩展性和成本效益的理想结合。
当 LLM 需要从海量非结构化文档中获取信息、进行推理时,传统解析方案的局限性便暴露无遗:
数据异构性与噪声:庞杂且异构的数据源(PDF、图片、扫描件等)中,如何精准提炼出对业务具有指导意义的有效信号?
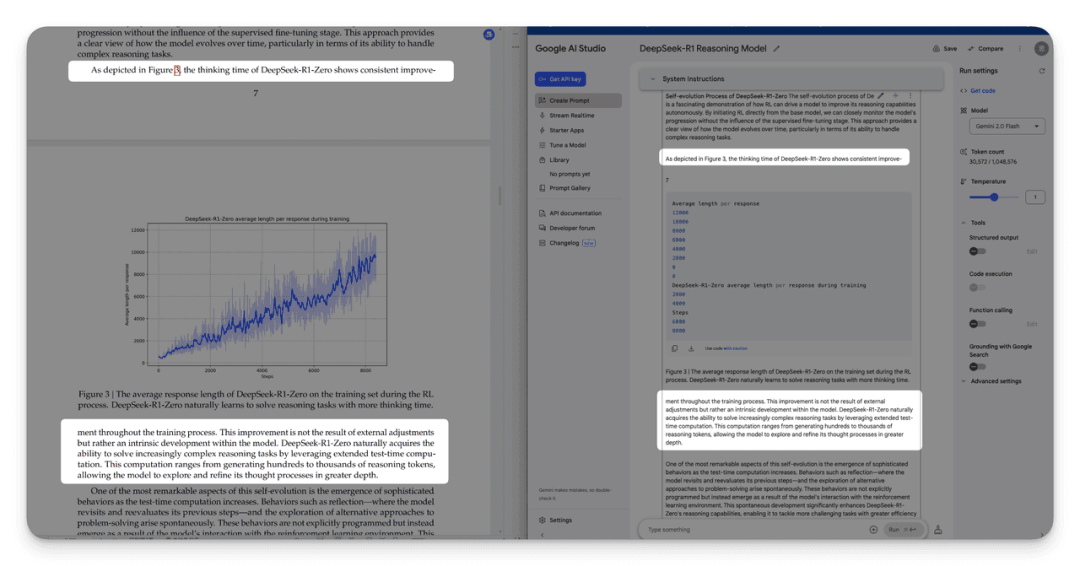
Google Gemini 识别的跨页段落未正确合并
结构化挑战:以 PDF 为例,将其拆解为干净、结构化、机器可读的语义文本块,仍是构建高质量 RAG 系统的一大技术瓶颈。
信息定位缺失:传统工具无法提供准确的文本边界框信息,导致难以精准定位提取出的每段文本片段在原始文档中的来源,使得 RAG 工作流中 LLM 生成内容的验证变得困难。
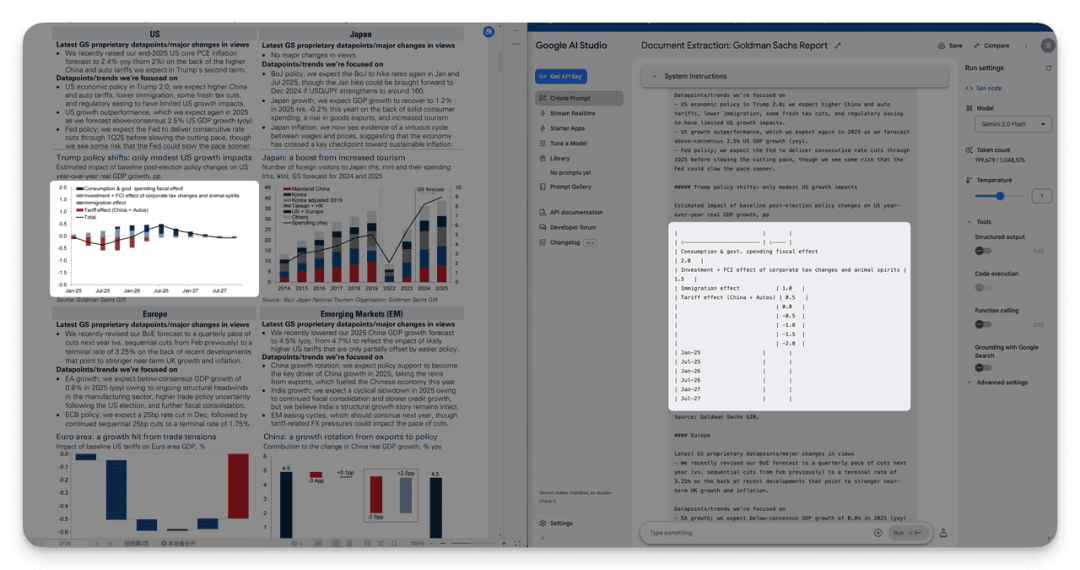
图表解析错误(例如,将范围值解释为固定数字)
在文档解析的所有步骤中,表格识别和提取是最具挑战性的。复杂的布局、非常规的格式以及不一致的数据质量使得可靠的提取变得困难。
我们团队在实践中尝试了超过十家国内外主流文档解析产品,发现了 EasyDoc 这个宝藏文档解析利器!传统文档解析,无论是基于规则的 OCR,还是简单的文本提取,都如同“盲人摸象”,只能触及文档的局部,却无法洞察其深层语义。
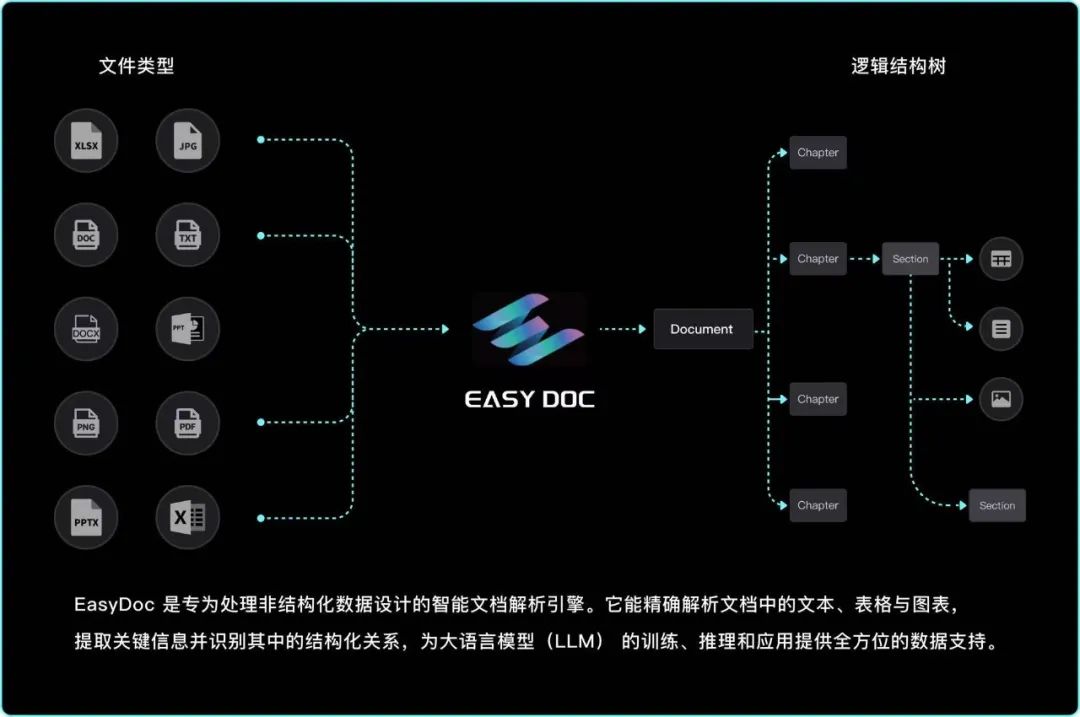
EasyDoc:让非结构化数据“开口说话”,全面赋能 AI 应用
EasyDoc 是由 EasyLink(上海容易链智能科技有限公司)自主研发的文档解析服务,基于视觉语义大模型,专为破解图表、表格等复杂非结构化内容的解析难题而生。
在深入调研与大量实践中,EasyDoc 在文档解析核心痛点上的表现令人惊艳。特别是面向构建高质量 RAG 系统和 AI Agent 应用的开发者,EasyDoc 提供了一套更强大、更精准、更智能的破局方案。
✅ 1. 功能完整,优势明显
-
图表+ 图片理解双驱动
EasyDoc 能深入解析柱状图、饼图等图表及图像中的结构与语义,极大提升多模态理解和问答能力。
对金融、法律、医疗等高度依赖结构化数据的行业尤其关键,助力确立“智能标准”地位。
✅ 2. 技术突破,重塑解析体验
-
自动追踪与跨页合并
专业算法支持多栏排版与跨页内容的智能整合,准确还原上下文结构,处理多源复杂文档游刃有余。
-
表格与标题高精识别
精准识别表格结构和标题元素,提升后续结构化建模与信息抽取准确度,彻底告别“垃圾进,垃圾出”。
-
段落识别与语义分块
超越传统按行切分方式,自动生成语义连贯的知识块,优化 LLM 输入质量,助力智能推理。
-
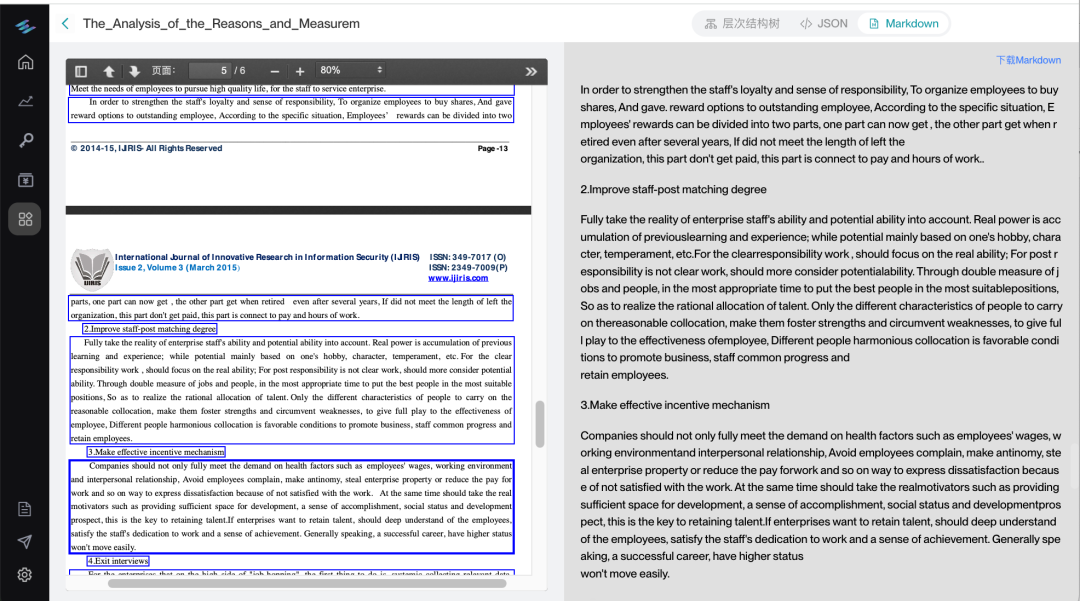
文本边界框与上下文映射
每段数据配有原文页码与坐标,实现内容可溯源,显著简化 RAG 系统中的事实核查与验证流程。
-
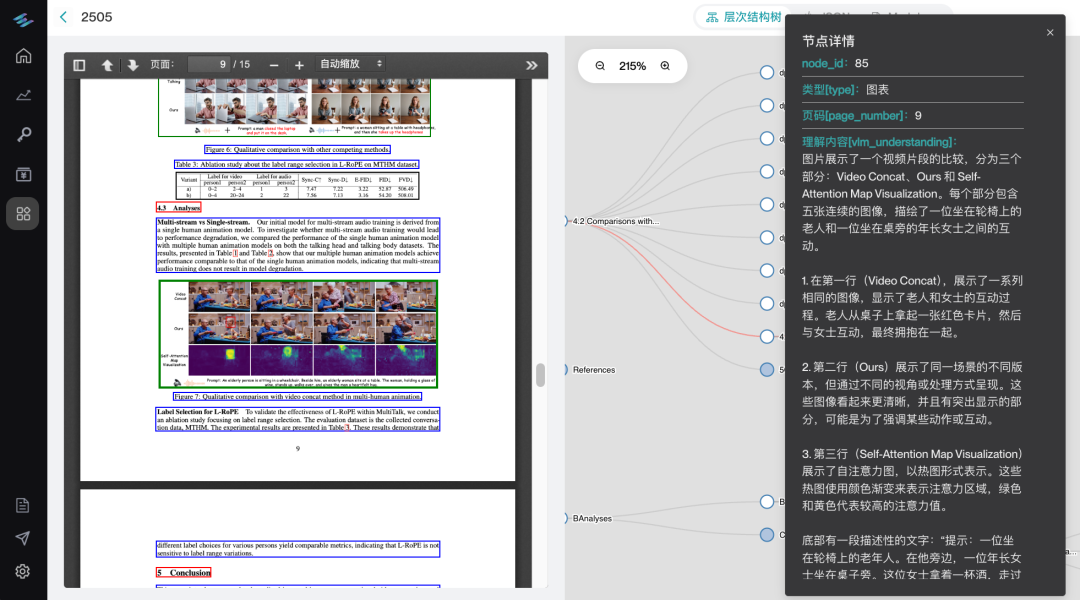
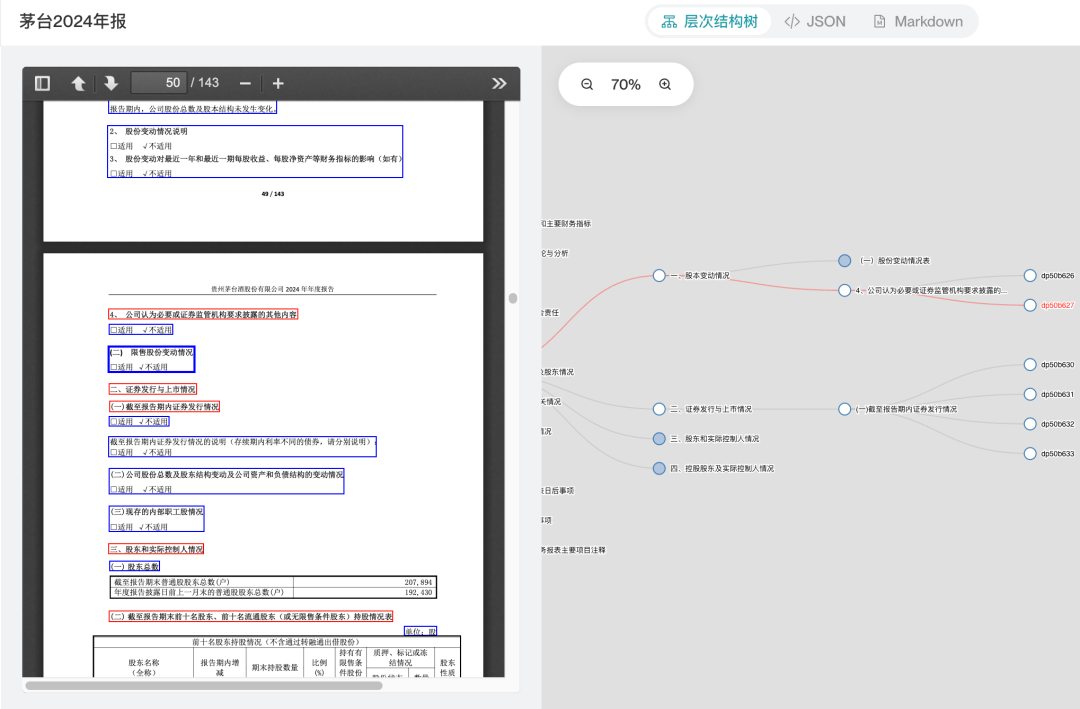
文档结构树精准构建
结构分析准确率高达 90%,清晰展现层级关系,为 LLM 提供更明确、更有语义上下文的理解路径。
听说未来 EasyDoc 将陆续发布 Benchmark 评测数据,值得持续关注。
现在注册即享 80 元体验金,可灵活试用 Lite / Pro / Premium 多版本能力;
最新上线的在线解析功能也让非技术用户轻松上手,立即体验文档解析工具的魅力!
社群二维码



















 2685
2685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









