




我是丁师兄,专注于智能驾驶方向大模型落地,公众号:丁师兄大模型。
大模型1v1学习,已帮助多名同学上岸国内外大厂
上个月初,一位刚进训练营的 211 硕士悄悄告诉我他雄赳赳气昂昂去面试大模型岗位,本以为胜券在握,却在常见的稀疏注意力机制上栽了跟头。那瞬间的尴尬,说不出什么滋味。
到底这小小的机制有何奥秘?一起走进这场面试 “小意外”,探寻大模型岗位背后的挑战与故事。
01面试官心理分析
这道面试题在面试中考察频率还是比较高。面试官问这个问题,主要就是想看两点:
第一,你知不知道常见的稀疏注意力机制有哪些。
第二,讲一下它们各自的核心思想。
02面试题解析
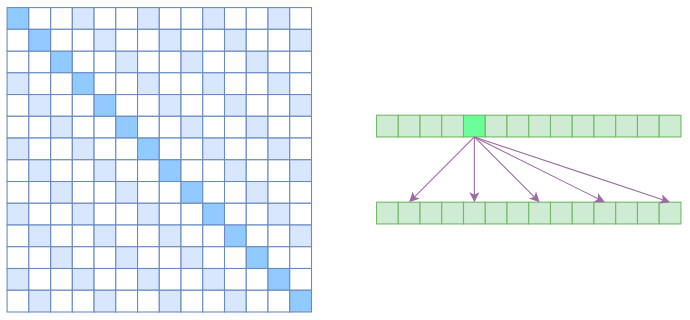
第一个你应该答出来的,就是 Atrous Self Attention,也就是"空洞自注意力",它借用了卷积运算中空洞的概念,计算注意力的时候是"跳着"来的。
来看这张图,我们把空洞参数设置为 k,(k=3),所以实际上每个元素只跟 n/k 个元素算相关性。
这样一来,理想情况下运行效率和显存占用都变成了 O(n²/k),也就是说,复杂度能够直接降低到原来的 1/k。
第二种是是 Local Self Attention,也就是局部自注意力。
其实自注意力机制在 CV 领域统称为“Non Local”,也就是局部感受野,而显然 Local Self Attention 是要放弃全局关联,重新引入局部
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2805
2805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









