



泛型程序设计
所谓泛型程序设计,就是编写不依赖于具体数据类型的程序。C++中,模板是泛型程序设计的主要工具。泛型程序设计的主要思想是将算法从特定的数据结构中抽象出来,使算法成为通用的、可以作用于各种不同的数据结构。这样就不必为每种容器都编写一套同样的算法,当容器类模板修改扩充时也不必重写大量算法函数。这种以函数模板形式实现的通用算法与各种通用容器结合,提高了软件的复用性。
STL
STL(标准模板库)是一个用于支持C++泛型编程的模板库。使用STL的一个模板时所提供的类型参数既可以是C++标准库中已有的类型,也可以是自定义的类型0只 要这些类型是所要求概念的模型,因此,STL是一个开放的体系。STL有四个基本组件:
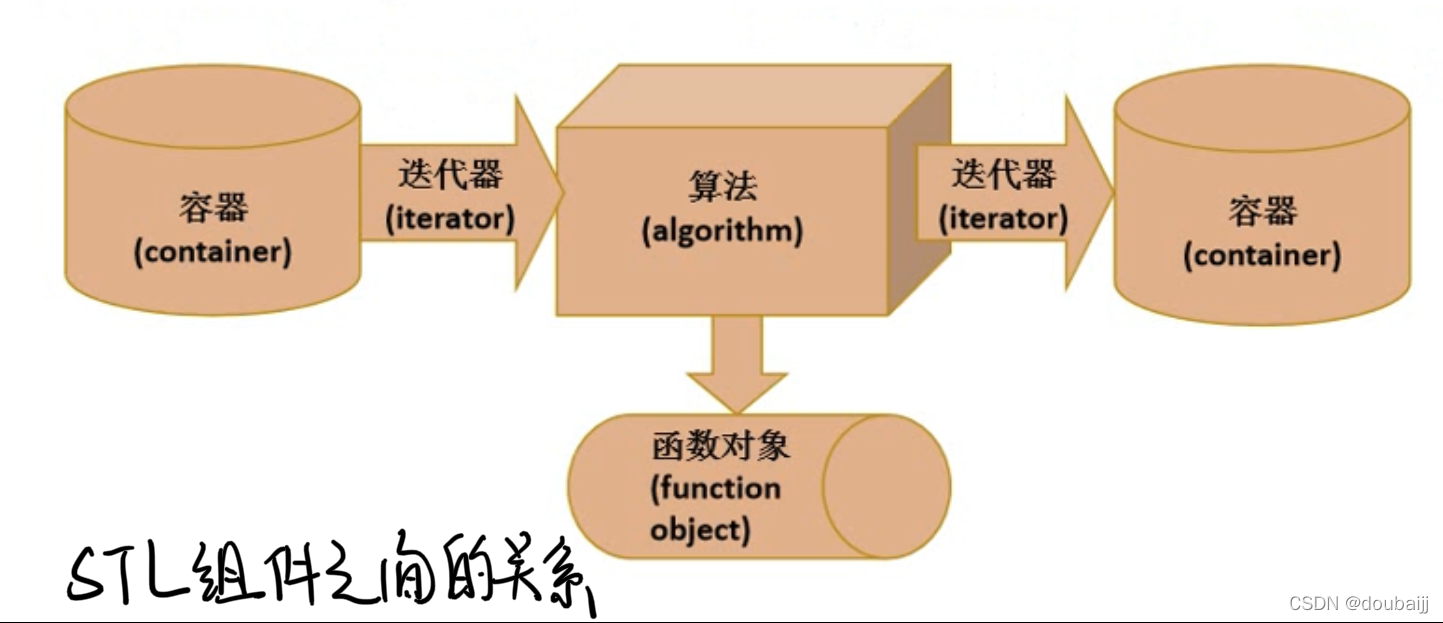
下面是两个简单的函数实现(取反、平方):
void transInv(int a[], int b[],int nNum)
{
for(int i = 0; i < nNum; i++)
{
b[i] = -a[i];
}
}
void transSqr(int a[], int b[],int nNum)
{
for(int i = 0; i < nNum; i++)
{
b[i] = a[i] * a[i];
}
}
但是这种形式的代码复用性非常差:传入的参数不是泛型,也没有容器,更没有给要复用的函数打包。
要提高代码的复用性,让我们来慢慢升级一下:
//升级一:这是可以传入泛型参数的模板方式的调用
template<typename T>
void transInvT(T a[], T b[],int nNum)
{
for(int i = 0; i < nNum; i++)
{
b[i] = -a[i];
}
}
//升级二:这是可以传入泛型参数的模板方式的调用,并且输出到vector,而且不需要那个nNum
template<typename inputIter, typename outputIter>
void transInvT2(inputIter begInput, inputIter endInput,
outputIter begOutput)
{
for(; begInput != endInput; begInput++, begOutput++)
{
*begOutput = -(*begInput);
}
}
这上面其实只是我们之前学习到的模板函数
test函数:
const int N = 5;
int a[N] = {1, 2, 3, 4, 5};
outputCont("a", cout, a, a+N);
int b[N];
transInv(a, b, N);
outputCont("Inv a", cout, b, b+N);
transSqr(a, b, N);
outputCont("Sqr a", cout, b, b+N);
//升级一:模板函数
transInvT(a, b, N);
outputCont("Inv a T", cout, b, b+N);
//升级二:输出到vector的模板函数
vector<double> vb(N);
transInvT2(a, a+N, b);
outputCont("Inv a T2", cout, b, b+N);
transInvT2(a, a+N, vb.begin());
outputCont("Inv a T2 Vec", cout, vb.begin(), vb.end());
输出:
a:1 2 3 4 5
Inv a:-1 -2 -3 -4 -5
Sqr a:1 4 9 16 25
Inv a T:-1 -2 -3 -4 -5
Inv a T2:-1 -2 -3 -4 -5
Inv a T2 Vec:-1 -2 -3 -4 -5
但如果我们用到了STL模式来实现我们的程序,那我们的代码就会有非常好的复用性:
//升级三:在升级二的基础上,把数学函数打包,这时只要替换打包好的数学函数
//取反
template<typename T>
T InvT(T a)
{
return -a;
}
//图像二值化的阈值
template<typename T>
class MyThreshold{
public:
//阈值初始化
MyThreshold(int n=128): _nThreshold(n){};
int operator()(T val)
{
return val<_nThreshold?0:1;
}
private:
//阈值
int _nThreshold;
};
template<typename inputIter, typename outputIter, typename MyOperator>
void transInvT3(inputIter begInput, inputIter endInput,
outputIter begOutput, MyOperator op)
{
for(; begInput != endInput; begInput++, begOutput++)
{
*begOutput = op(*begInput);
}
}
test函数:
//升级三:把数学函数打包
transInvT3(a, a+N, vb.begin(),InvT<int>);
outputCont("Inv a T3 by iter", cout, vb.begin(), vb.end());
transInvT3(a, a+N, vb.begin(),MyThreshold<int>(2));
outputCont("Inv a T3 by threshold", cout, vb.begin(), vb.end());
输出:
Inv a T3 by iter:-1 -2 -3 -4 -5
Inv a T3 by threshold:0 1 1 1 1
可以看到我们只需要写op代表的数学函数即可,代码的复用性得到了极大的提高,这就是STL模式代码的优点。我们可以通过sort算法的应用来体会SLT模式中算法和函数的关系,其中的”函数“可以是模板函数也可以是模板类:
自己写的compare函数和compare类(重写出来的operator要是双目运算符、返回类型要是bool):
//自己写的比较模板函数 降序
template<typename T>
bool mycomp(T a, T b)
{
return a > b;
}
//自己写的compare类
template<typename T>
class MyCompare
{
public:
MyCompare(int n=0):choose_key(n){}
bool operator()(T a, T b)
{
switch (choose_key) {
case 0:
return a == b;
break;
case 1:
//降序
return a > b;
break;
case 2:
//升序
return a < b;
break;
}
}
private:
int choose_key;
};
test函数:
const int N = 5;
int a[N] = {1, 2, 3, 6, 5};
outputCont("a", cout, a, a+N);
//通过一个sort来体会SLT模式中算法和函数的关系
sort(a, a+N);
//自己写到compare函数 变成降序排列
sort(a, a+N, mycomp<int>);
//调用STL库里的compare类 实现降序排列
sort(a, a+N, greater<int>());
//自己写的compare类 实现降序排列
sort(a, a+N, MyCompare<int>(1));
outputCont("a sorted", cout, a, a+N);
输出:
a:1 2 3 6 5
a sorted:6 5 3 2 1
容器: set
map和set这些关联式容器的插入删除、搜索效率比用其他序列容器高很多,set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。结构图可能如下:
A
/ \
B C
/ \ / \
D E F G
set中常用的方法:
begin() ,返回set容器的第一个元素
end() ,返回set容器的最后一个元素
clear() ,删除set容器中的所有的元素
empty() ,判断set容器是否为空
max_size() ,返回set容器可能包含的元素最大个数
size() ,返回当前set容器中的元素个数
rbegin ,返回的值和end()相同
rend() ,返回的值和rbegin()相同
insert() 插入元素
erase() 删除一段元素
set的查询需要用迭代的方式实现,set会根据键值自动排序:
个体学生类:
//学生类
class studentInfo
{
public:
int _strNo; // 学号
string _strName; // 姓名
// 构造函数
studentInfo(int strNo, string strName){
_strNo = strNo;
_strName =strName;
}
// 重载输出运算符
friend ostream& operator<<(ostream& os, const studentInfo& info)
{
os<<endl<<info._strNo<<" "<<info._strName;
return os;
}
// 重载比较运算符
friend bool operator<(const studentInfo& info1, const studentInfo& info2)
{
return info1._strNo<info2._strNo;
}
};
TestSet函数:
输出:
students vector:
1 why
2 fdy
6 zt
5 zjw
student set:
1 why
2 fdy
5 zjw
6 zt
看吧,对比vector容器 ,set会自动排序。
用set存储学生信息,并进行增删改查操作:
//对集合的增删改查
template <class T>
class students
{
public:
//做一个学生信息的set
set<studentInfo> stuSet;
//记录set中的元素
int stuNum = 0;
// 构造函数
template <class t>
students(t stud){
for(auto it:stud){
stuSet.insert(it);
stuNum ++;
}
}
// 增加一个学生
void addAStudent(T stu){
stuSet.insert(stu);
stuNum ++;
}
// 批量增加一批学生
template <class t>
bool addStudents(t stu){
for(auto it:stu){
stuSet.insert(it);
stuNum ++;
}
return true;
}
// 根据学号删除
bool delByNo(int SNo){
for(auto it:stuSet){
if(it._strNo == SNo){
stuSet.erase(it);
stuNum --;
return true;
}
}
return true;
}
// 根据学号查找
string searchNameByNO(int No){
for(auto it:stuSet){
if(it._strNo == No){
return it._strName;
}
}
return "Not Found";
}
// 根据学号修改姓名
void updateByNo(int No, string afterName){
for(auto it:stuSet){
if(it._strNo==No){
stuSet.erase(it);
//要跳出循环,因为erase会破坏二叉树的结构
break;
}
}
stuSet.insert(studentInfo(No, afterName));
}
};
Test Students():
void TestStudents()
{
vector<studentInfo> stuvec1;
stuvec1.push_back(studentInfo(001, "why"));
stuvec1.push_back(studentInfo(002, "fdy"));
stuvec1.push_back(studentInfo(006, "zt"));
stuvec1.push_back(studentInfo(005, "zjw"));
vector<studentInfo> stuvec2;
stuvec2.push_back(studentInfo(003, "hhl"));
stuvec2.push_back(studentInfo(004, "qpt"));
students<studentInfo> stuSet(stuvec1);
outputCont("student Set:\n", cout, stuSet.stuSet.begin(), stuSet.stuSet.end());
// 增
stuSet.addStudents(stuvec2);
outputCont("addStudents(stuvec2) student Set\n", cout, stuSet.stuSet.begin(), stuSet.stuSet.end());
stuSet.addAStudent(studentInfo(8, "lll"));
outputCont("addAStudent student Set\n", cout, stuSet.stuSet.begin(), stuSet.stuSet.end());
// 删
stuSet.delByNo(8);
outputCont("delByNo(8) student Set\n", cout, stuSet.stuSet.begin(), stuSet.stuSet.end());
// 改
stuSet.updateByNo(6, "ztt");
outputCont("updateByNo student Set\n", cout, stuSet.stuSet.begin(), stuSet.stuSet.end());
// 查
cout<<"\nsearchNameByNO(1):"<<stuSet.searchNameByNO(1)<<endl;
outputCont("student Set\n", cout, stuSet.stuSet.begin(), stuSet.stuSet.end());
}
输出:
student Set:
:
1 why
2 fdy
5 zjw
6 zt
addStudents(stuvec2) student Set
:
1 why
2 fdy
3 hhl
4 qpt
5 zjw
6 zt
addAStudent student Set
:
1 why
2 fdy
3 hhl
4 qpt
5 zjw
6 zt
8 lll
delByNo(8) student Set
:
1 why
2 fdy
3 hhl
4 qpt
5 zjw
6 zt
updateByNo student Set
:
1 why
2 fdy
3 hhl
4 qpt
5 zjw
6 ztt
searchNameByNO(1):why
student Set
:
1 why
2 fdy
3 hhl
4 qpt
5 zjw
6 ztt
容器: map
Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据 处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。
map是一类关联式容器。它的特点是增加和删除节点对迭代器的影响很小,除了那个操作节点,对其他的节点都没有什么影响。对于迭代器来说,可以修改实值,而不能修改key。
基于map的性质,我们可以用map来做键值对快速查找:
void TestMap()
{
map<int,double> stumap1;
stumap1[001] = 100;
stumap1[002] = 100;
stumap1[006] = 99;
for(map<int,double>::iterator it = stumap1.begin();
it!=stumap1.end(); it++)
{
cout<<"sno:"<<it->first<<"\t"<<"score:"<<it->second<<endl;
}
}
输出:
sno:1 score:100
sno:2 score:100
sno:6 score:99
输入一个字符串,用map统计每个字符出现的次数并输出字符及对应的次数:
主要用到的函数——find函数:它是来定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器,如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器。
//输入一个字符串,用map统计每个字符出现的次数并输出字符及对应的次数
void countStr_Char(string str){
//char是我们要统计的字符 int是字符出现的次数
map<char, int> count;
for(float i = 0;i<str.length();i++){
// 利用map的find函数来判断这个字符是否出现过
//find函数:如果map中没有要查找的数据,它返回的迭代器等于end函数
if(count.find(str[i])==count.end()){
//第一次出现,次数赋值为1
count[str[i]] = 1;
}
// 字符.次数++
else{count[str[i]]++;}
}
for(auto i:count){
cout<<i.first<<": "<<i.second<<" ";
}
cout<<endl;
}
main.cpp:
string str;
while (1) {
cin>>str;
countStr_Char(str);
}
输出:
asdsd
a: 1 d: 2 s: 2
dasds
a: 1 d: 2 s: 2
fdgfb
b: 1 d: 1 f: 2 g: 1
qqqqqqqqqqq
q: 11
weihanyan
a: 2 e: 1 h: 1 i: 1 n: 2 w: 1 y: 1
总结
今天我们了解了一些STL,根据STL模式编写了代码,体会到了STL模式的便利,提高了代码的复用性,代码易读性强,STL集成了优秀的算法,熟悉使用可以提高开发效率,精通STL后,可以自己用模板去设计实现自己的算法和数据结构。

















 3044
3044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









