



1.题目链接:
2.题目描述:
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
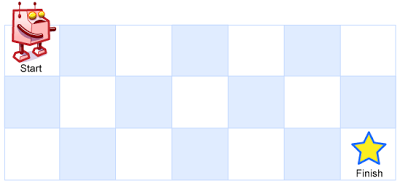
输入:m = 3, n = 7
输出:28
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
1. 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右
3. 向下 -> 向右 -> 向下
3. 解法(动态规划):
算法思路:
1. 状态表示:
对于这种「路径类」的问题,我们的状态表示一般有两种形式:
| i. | 从 [i, j] 位置出发,巴拉巴拉; |
ii. 从起始位置出发,到达 [i, j] 位置,巴拉巴拉。这里选择第二种定义状态表示的方式:
dp[i][j] 表示:走到 [i, j] 位置处,一共有多少种方式。
2. 状态转移方程:
简单分析一下。如果 dp[i][j] 表示到达 [i, j] 位置的方法数,那么到达 [i, j] 位置之前的一小步,有两种情况:
| i. | 从 [i, j] 位置的上方([i - 1, j] 的位置)向下走一步,转移到 [i, j] 位置; |
ii. 从 [i, j] 位置的左方([i, j - 1] 的位置)向右走一步,转移到 [i, j] 位置。由于我们要求的是有多少种方法,因此状态转移方程就呼之欲出了:dp[i][j] = dp[i - 1]
| [j] + dp[i][j - 1] 。 |
3. 初始化:
可以在最前面加上一个「辅助结点」,帮助我们初始化。使用这种技巧要注意两个点:
i. 辅助结点里面的值要「保证后续填表是正确的」;
ii. 「下标的映射关系」。
在本题中,「添加一行」,并且「添加一列」后,只需将 dp[0][1] 的位置初始化为 1 即可。
4. 填表顺序:
根据「状态转移方程」的推导来看,填表的顺序就是「从上往下」填每一行,在填写每一行的时候「从左往右」。
5. 返回值:
根据「状态表示」,我们要返回 dp[m][n] 的值。
Java算法代码:
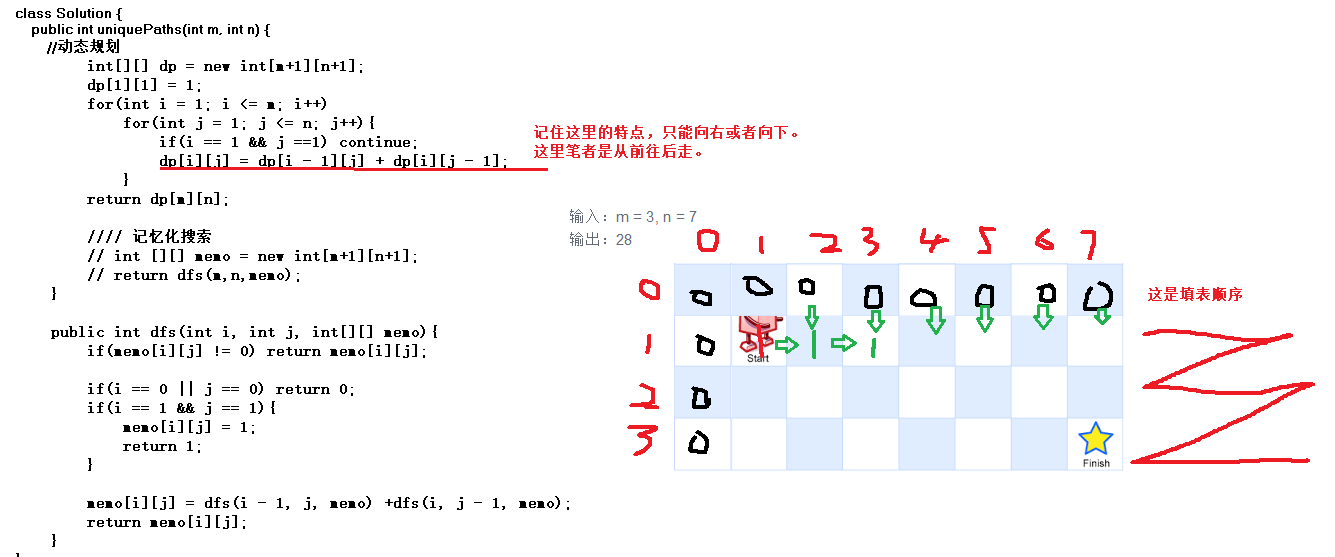
class Solution {
public int uniquePaths(int m, int n) {
//动态规划
int[][] dp = new int[m+1][n+1];
dp[1][1] = 1;
for(int i = 1; i <= m; i++)
for(int j = 1; j <= n; j++){
if(i == 1 && j ==1) continue;
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
return dp[m][n];
//// 记忆化搜索
// int [][] memo = new int[m+1][n+1];
// return dfs(m,n,memo);
}
public int dfs(int i, int j, int[][] memo){
if(memo[i][j] != 0) return memo[i][j];
if(i == 0 || j == 0) return 0;
if(i == 1 && j == 1){
memo[i][j] = 1;
return 1;
}
memo[i][j] = dfs(i - 1, j, memo) +dfs(i, j - 1, memo);
return memo[i][j];
}
}运行结果:
动态规划:这道题笔者并不是第一次做,已经好几次了,也是很好想的。
这里是从头到尾巴。看看dfs这里是从尾巴到头。

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









