






需求:
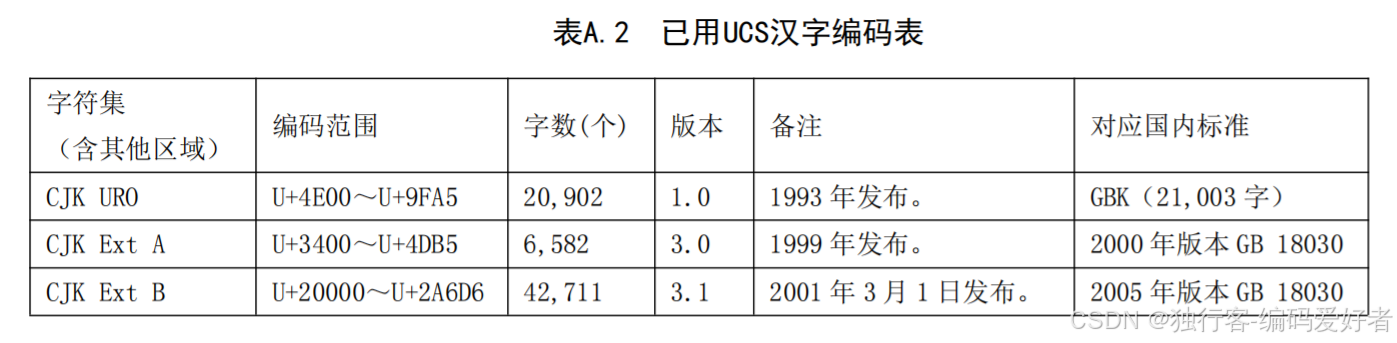
需要判断输入字符是否是一个汉字,因为汉字都有唯一的Unicode码点,因此使用Unicode 码点判断是否汉字,这里用四字节汉字作为一个案例进行演示,这个字在扩展B区,即"U+20000~U+2A6D6":
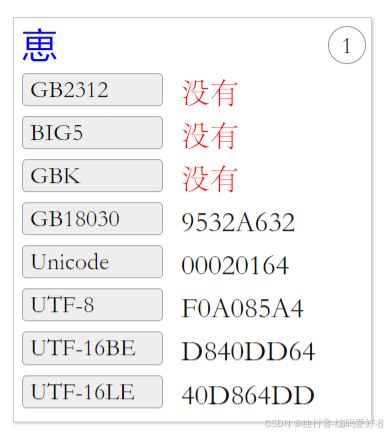
备注:这里的Unicode 编码 20164是十六进制编码,即判断 20164 是否是在“20000~2A6D6”之间,因为此字是四字节汉字,java在进行处理时会有一些问题,因为java在存储汉字时,使用UTF-16编码代码单元来存储汉字,如果码点值小于65535(十进制),则用一个代码单元存储,如果是大于65535 则使用两个代码单元存储。因此在循环时需要使用码点数进行遍历,而不能根据字符串长度。
代码样例:
import java.util.regex.Pattern;
/**
* @Description TODO
* @date 2024/10/28 9:47
* @Version 1.0
* @Author gezongyang
*/
public class TestCharset {
public static void main(String[] args) {
String testString = "𠅤我";
//根据码点数遍历字符串
for(int index=0; index < testString.codePoints().count(); index++) {
int codePoint = testString.codePointAt(index);
String codeStr = Integer.toHexString(codePoint);
System.out.println("十进制码点:" + codePoint);
System.out.println("十六进制码点:" + codeStr);
System.out.println(Pattern.matches("[\u20000-\u2A6D6]*", codeStr));
}
}
}返回值:
十进制码点:131428
十六进制码点:20164
true
十进制码点:56676
十六进制码点:dd64
true


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











