







5.1 解析CSV文件
CSV文件内容:
Details,Month,Amount
Mid Bonus,June,"$,2000"
,January,"""zippo"""
Total Bonuses,"","$5000"语法:
grammar csv;
prog: file+;
file : hdr row+;
hdr: row;
row: field (',' field)* '\r'? '\n'; //一列由逗号分隔且由换行符终止的字段
field //field允许两个逗号之间出现任意的文本、字符串、或者什么也没有
: TEXT
| STRING
|
;
TEXT: ~[,\n\r"]+; //TEXT类型的词法符号是下一个逗号或者换行符之前的任意字符序列
STRING: '"' ('""'|~'"')* '"'; //两个双引号是对双引号的转义描述:为了方便应用程序对标题进行处理,所以对标题进行单独匹配,为了允许被双引号包围的字符串中出现双引号,CSV格式通常使用两个双引号来转义。这就是STRING规则的子规则(''''''|'''')*存在的原因。我们不能使用通配符来构造非贪婪循环(''''''|.)*?,因为它一旦遇到在字符串开始之后的第一个",便会终止匹配过程。类似"x""y"的输入就会被匹配成两个字符串,而非单个包含""的字符串。
语法分析树:

5.2 解析JSON
{
"antlr.org": {
"owners":[],
"live" : true,
"speed" : le100
"menus" : ["File","Help\nMenu"]
}
}1)JSON 的语法规则
一个JSON 文件可以是一个对象,或者是一个若干个值组成的数组。从语法上看,这不过是一个选择模式,因此,我们可以用下列规则来表达:
json: object
| array
;
下一步将json 规则引用的各个子规则进行分解。对于对象,JSON语法是这样规定的:
一个对象是一组无序的键值对集合。一个对象以一个左花括号({)开始,且以一个右花括号(}) 结束。每个键后跟一个冒号(:),键值对之间由逗号分隔(,)。
JSON官方规定对象中的键必须是字符串语法规则:
object : '{' STRING ':' value (',' STRING ':' value)* '}' | ... ;数组语法描述:
数组是一组值的有序集合。一个数组由一个左方括号开始([),由一个右方括号(])结束。其中的值由逗号(,)分隔语法规则:
array
: '[' value (',' value)* ']'
| '[' ']' //空数组
;值语法描述:
一个值可以是一个双引号包围的字符串、一个数字、true/false、null、一个对象、或者一个数组。这些结构中可能发生嵌套。语法规则:
value
: STRING
| NUMBER
| object //递归调用
| array //递归调用
| 'true' //关键字
| 'false'
| 'null'
;2) 词法规则
字符串词法描述:
一个字符串就是一个由零个或多个Unicode字符组成的序列,它由双引号包围,其中的字符使用反斜杠转义。单个字符由长度为1的字符串来表示。
字符串应该匹配任意除双引号和反斜杠之外的字符,可以通过反向序列 ~["\\]来满足这个要求(~: 表示非)
例如:STRING词法定义:
STRING: '"' (ESC | ~["\\])* '"';ESC规则描述:
匹配Unicode序列或者预定义的转义字符ESC词法定义:
fragment ESC : '\\' (["\\/bfnrt] | UNICODE);
fragment UNICODE: 'u' HEX HEX HEX HEX;
fragment HEX: [0-9a-fA-F];数字词法描述:
不允许使用八进制和十六进制格式,并且不应当匹配除0之外的以0开头的数字数字词法定义:
NUMBER
: '-'? INT '.' INT EXP? //1.35 1.35E-9 0.3 -4.5
| '-'? INT EXP //1e10 -3e4
| '-'? INT //-3 45
;
fragment INT: '0' | [1-9] [0-9]*; //除0外的数字不允许以0开始
fragment EXP: [Ee] [+\-]? INT; //\-是对-的转义,因为[...]中-用于表达“范围” 语义空白字符词法描述:
在任意两个词法符号之间,可以存在任意多的空白字符,任意两个词法符号之间,可以存在任意多的空白字符空白字符词法定义:
WS : [' '| '\t' | '\n' | '\r']+ -> skip;JSON解析实例:
grammar JSON;
json: object
| array
;
object
: '{' pair (',' pair)* '}'
| '{' '}' //空对象
;
array
: '[' value (',' value)* ']'
| '[' ']' //空数组
;
pair: STRING ':' value;
value
: STRING
| NUMBER
| object //递归调用
| array //递归调用
| 'true' //关键字
| 'false'
| 'null'
;
STRING: '"' (ESC | ~["\\])* '"';
fragment ESC : '\\' (["\\/bfnrt] | UNICODE);
fragment UNICODE: 'u' HEX HEX HEX HEX;
fragment HEX: [0-9a-fA-F];
NUMBER
: '-'? INT '.' INT EXP? //1.35 1.35E-9 0.3 -4.5
| '-'? INT EXP //1e10 -3e4
| '-'? INT //-3 45
;
fragment INT: '0' | [1-9] [0-9]*; //除0外的数字不允许以0开始
fragment EXP: [Ee] [+\-]? INT; //\-是对-的转义,因为[...]中-用于表达“范围” 语义
WS : [' '| '\t' | '\n' | '\r']+ -> skip;语法树:
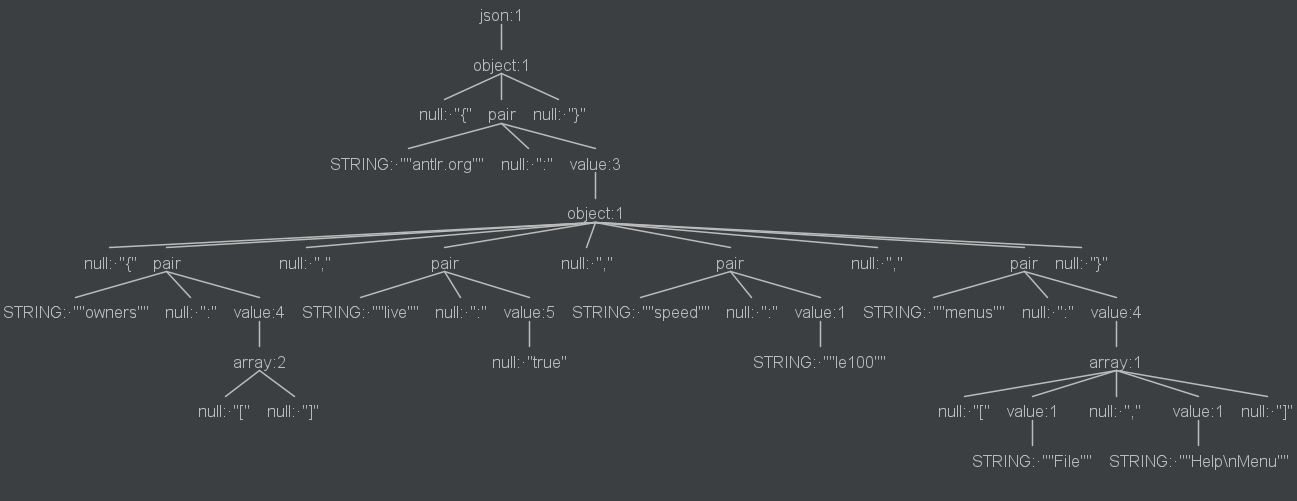
5.3 解析DOT语言
DOT是一门声明式编程语言,主要用于描述网络图、树或者状态机之类地图形(DOT是声明式语言地原因是,我们描述地是图形及图形间地连接是什么,而非构造图形地过程)。它是一种应用广泛地图形工具,尤其是在你的程序需要生成图形时。例如,ANTLR的-atn选项就使用DOT来产生可视化的状态机。
为了能快速熟悉这门语言,假设我们需要将一个程序的四个函数间的调用关系可视化。我们可以手工画出来,或者使用下面的DOT代码来指定它们之间的关系(这些DOT代码可以手写或者编写一个源代码分析工具自动生成):
t.dot
digraph G {
rankdir=LR;
main [shap=box];
main -> f -> g; //main 调用f,f调用g
f -> f [style=dotted]; //f 是递归的
f -> h; //f 调用了h
}结果图:
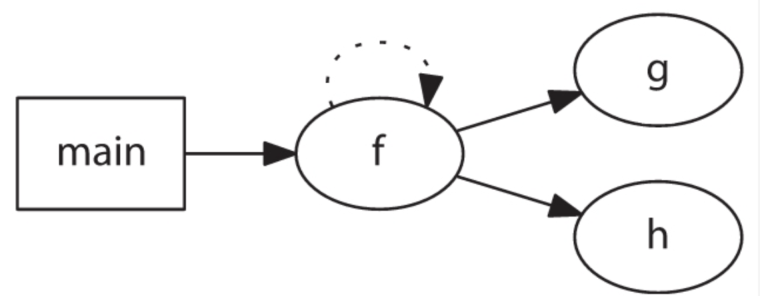
幸运的是,DOT语法指南中包含了几乎可以直接使用的句法规则,我们所需的仅仅是将它们翻译为ANTLR语法。不幸的是,我们需要自行编写词法规则。
1) DOT语言的语法规则
下面是将DOT语言参考文档文档翻译为ANTLR标记的结果:
DOT.g4
grammar DOT;
graph : STRICT? (GRAPH | DIGGRAPH) id? '{' stmt list '}';
stmt_list : (stmt ';'?)*;
stmt : node_stmt
| edge_stmt
| attr_stmt
| id '=' id
| subgraph
;
attr_stmt : (GRAPH | NODE | EDGE) attr_list;
attr_list : ('[' a_list? ']')+;
a_list : (id ('=' id)? ','?)+;
edge_stmt : (node_id | subgraph) edgeRHS attr_list?;
edgeRHS : (edgeop (node_id | subgraph))+;
edgeop : '->' | '--';
node_stmt : node_id attr_list? ;
node_id : id port?;
port : ':' id (':' id)? ;
subgraph : (SUBGRAPH id?) ? '{' stmt_list '}';
id : ID
| STRING
| HTML_STRING
| NUMBER
;我们所做的唯一修改的是port规则。参考文档中给出的规则如下:
port : ':' ID [ ':' compass_pt ]
| ':' compass_pt
;
compass_pt : (n | ne | e | se | s | sw | w | nw); 如果方位点(compass point) 是一个关键字,即不能作为合法的标识符,那么上述规则就能够被正常使用。
注意,合法的方位点的值并非关键字,因此这些字符串可被用于任何常规标识符能够出现的地方。
这意味着我们必须接受类似n->sw这样的极端情况,其中n和sw都不是关键字,而是标识符。参考文档接着指出:"...反之,语法分析器接受任意标识符"。这句话的含义不是非常清楚,似乎是语法分析器允许任意标识符作为方位点。如果这种猜测成立的话,我们在语法中就完全无须担心方位点的问题,我们可以用id替换掉参考文档中的compass_pt规则。
port: ':' id (':' id)? ;为了验证,使用DOT语言查看器验证假设。经验证,下列图定义能被正确识别。
digraph G {n -> sw;}至此,我们拥有了全部的语法规则
2)DOT语言的词法规则
由于DOT语言参考指南没有给出正式的词法规则,我们就需要根据其中的描述生成。不妨从最简单的关键字开始。
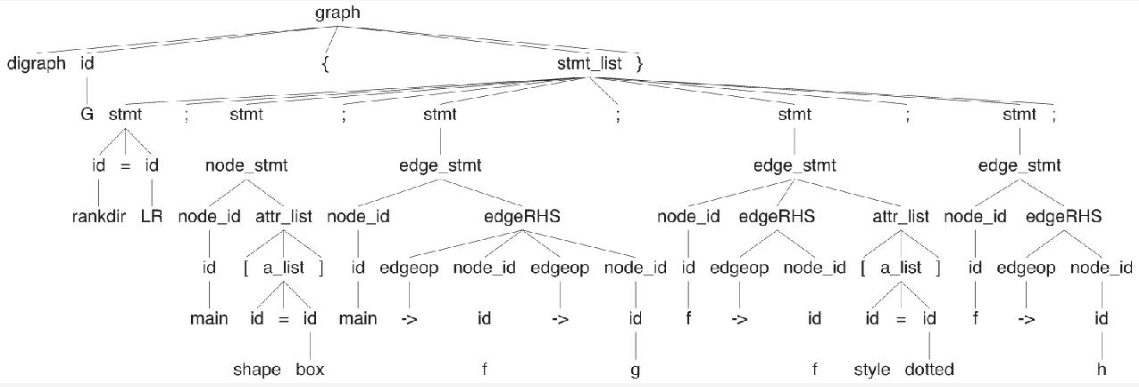
参考文档指出,"关键字 node、edge、graph、digraph、subgraph,以及strict是不区分大小写的"。如果它们区分大小写,我们就可以在语法中简单地使用类似'node'的字符串常量。为了能够识别nOdE这样的变体,我们需要在关键字的词法规则中为每个字符分别指定大小写的形式。
DOT.g4
STRICT : [Ss][Tt][Rr][Ii][Cc][Tt];
GRAPH : [Gg][Rr][Aa][Pp][Hh];
DIGRAPH : [Dd][Ii][Gg][Rr][Aa][Pp][Hh];
NODE : [Nn][Oo][Dd][Ee];
EDGE : [Ee][Dd][Gg][Ee];
SUBGRAPH : [Ss][Uu][Bb][Gg][Rr][Aa][Pp][Hh];DOT语言中的标识符和其他编程语言相似。
任意由字母表中的字符([a-zA-Z\200-\377])、下划线('_')或数字([0-9])组成的,不以数字开头的字符串。
八进制的数字范围\200-\377用十六进制来表示是80到ff,因此我们的ID规则如下:
DOT.g4
ID : LETTER (LETTER|DIGIT)*;
fragment LETTER : [a-zA-Z\u0080-\u00FF_];我们定义了一个辅助规则DIGIT来匹配数字。参考文档指出,数字遵循下列正则表达式:
[-]?(.[0-9] + [0-9] + (.[0-9]*)? )使用DIGIT替换其中的[0-9],我们就得到了用ANTLR标记编写的、代表DOT语言中的数字的规则,如下:
DOT.g4
NUMBER : '-' ? ('-'? ('.' DIGIT+ | DIGIT+ ('.' DIGIT*)?));
fragment DIGIT : [0-9];DOT语言中的字符串定义较为基础。
任意的由双引号包围的字符序列("..."),可能包括转义后的双引号\"。
我们使用点通配符来匹配字符串中的任意字符,直到遇见最后的双引号为止。额外地,我们将转义后地双引号作为子规则循环中的一个备选分支。
DOT.g4
STRING : '"' ('\\"' | .)*? '"';DOT语言中还包含一种名为HTML字符串的元素,据我所知,它和字符串非常相似,唯一的差异在于它使用尖括号而不是双引号。参考文档中使用<...>来表示这种元素,描述如下:
在HTML字符串中,尖括号必须成对出现,其中可以包含未转义的换行符。除此之外,HTML字符串的内容必须是合法的XML,这就要求某些特殊字符("、&、<以及>)需要被转义,以便嵌入XML标签的属性或者文本中。
上面的描述告诉了我们需要完成的工作,但是没有回答这一问题:我们是否可以在HTML注释中包含>。另外,它似乎暗示我们需要将标签序列放入尖括号中,类似<<i>hi<i/>>。经DOT查看器试验,我们的猜测是正确的。从试验的结果看,DOT语言能够接受一对尖括号中的任意文本,只要这对尖括号是配对的。因此,HTML注释中的>不会像XML解析器那样的处理方式忽略,即HTML注释中的>不会像XML解析器那样的处理方式忽略,即HTML字符串<foo<! --ksjdf>-->>会被当作字符串"foo<! --ksjdf>-->"处理。
我们可以使用ANTLR结构'<'.*?'>'来匹配两个尖括号之间的任意文本。不过,这个规则不允许其中出现嵌套的尖括号,因为它会把第一个>和第一个<配对,而不是我们期望的最近的<。下列规则能够达到预期效果:
DOT.g4
//在HTML 字符串中,尖括号必须成对出现,其中可以包含未转义的换行符
HTML_STRING : '<' (TAG|~[<>])* '>';
fragment TAG : '<' .*? '>';其中的HTML_STRING规则允许TAG元素出现在配对的尖括号之间,这样就实现了一层的嵌套。~[<>]负责类似"<";的XML字符实体。它匹配除左右尖括号外的任何字符。在这里,我们不能使用通配符和非贪婪匹配循环,这是因为,若循环中的通配符能够匹配<foo,"(TAG|.) *?" 就能匹配类似<<foo>>的无效输入。即,如果使用了通配符,HTML_STRING无须调用匹配标签元素的TAG规则就能完成匹配,也就无法得到我们期望的结果。
5.4 解析Cymbol语言
为Cymbol语言编写语法,以此来展示类C语言的解析过程。Cymbol是一门简单的、非面向对象的编程语言,外观类似不带结构体的C语言。如果你想要自己创造一门新的编程语言的话,Cymbol的语法可以作为它的原型。
当设计一门新的语言时,我们通过设计新语言的范例代码起步,从范例代码中提取语法。下面一段带有全局变量和递归函数声明的程序就是Cymbol代码:
t.cymbol
int g =9;
int fact(int x) { //求阶乘的函数
if x == 0 then return 1;
return x * fact(x-1);
}语法分析树如下图所示:
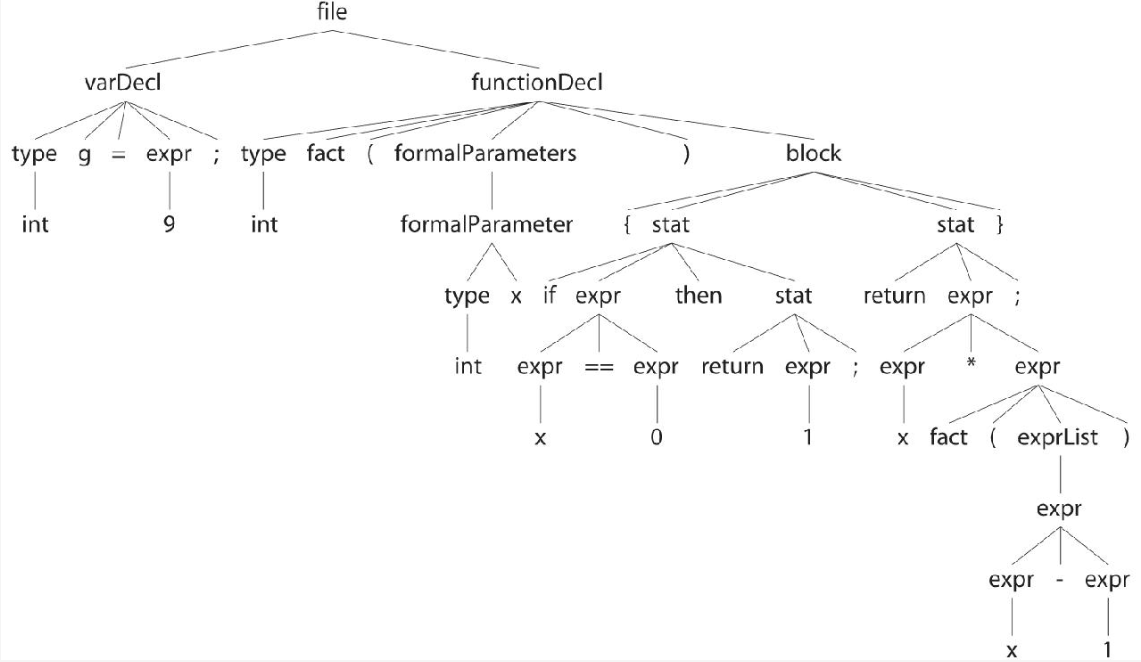
从最粗的粒度观察Cymbol程序,我们可以发现它由一系列全局变量和函数声明组成。
grammar Cymbol;
file: (functionDecl | varDecl)+;同所有的类C语言一样,变量声明由一个类型开始,随后是一个标识符,最后是一个可选的初始化语句。
Cymbol.g4
varDecl
: type ID ('=' expr)? ';'
;
type: 'float' | 'int' | 'void'; //用户定义的类型函数声明也基本上相同:类型后面跟着函数名,随后是被括号包围的参数列表,最后是函数体。Cymbol.g4
functionDecl
: type ID '(' formalParameters? ')' block
;
formalParameters
: formalParameter (',' formalParameter)*
;
formalParameter
: type ID
; 一个函数体是由花括号包围的一组语句。让我们先构造六种语句:嵌套的代码块、变量声明、if语句、return语句、赋值语句,以及函数调用。
Cymbol.g4
block: '{' stat* '}' ;
stat: block
| varDecl
| 'if' expr 'then' stat ('else' stat)?
| 'return' expr? ';'
| expr '=' expr ';'
| expr ';'
;Cymbol 语言的最后一个主要部分是表达式语法。因为Cymbol实际上仅仅是其他语言的原型或者基础,因此没有必要包含非常多的运算符。假设我们的表达式包括一元取反、布尔非、乘法、加法、减法、函数调用、数组索引、等同性判断、变量、整数以及括号表达式。
Cymbol.g4
expr : ID '(' exprList? ')' #Call
| expr '[' expr ']' #Index
| '-' expr #Negate
| '!' expr #Not
| expr '*' expr #Mult
| expr ('+' | '-') expr #AddSub
| expr '==' expr #Equal
| ID #Var
| INT #Int
| '(' expr ')' # Parens
;
exprList : expr (',' expr)*; 其中的重点是我们通常将备选分支按照从高到低的优先级进行排序。为了说明运算符优先级的应用,我们来查看一下"-x+y;"和"-a[i]"对应的语法分析树,它们的起始规则都是stat规则。
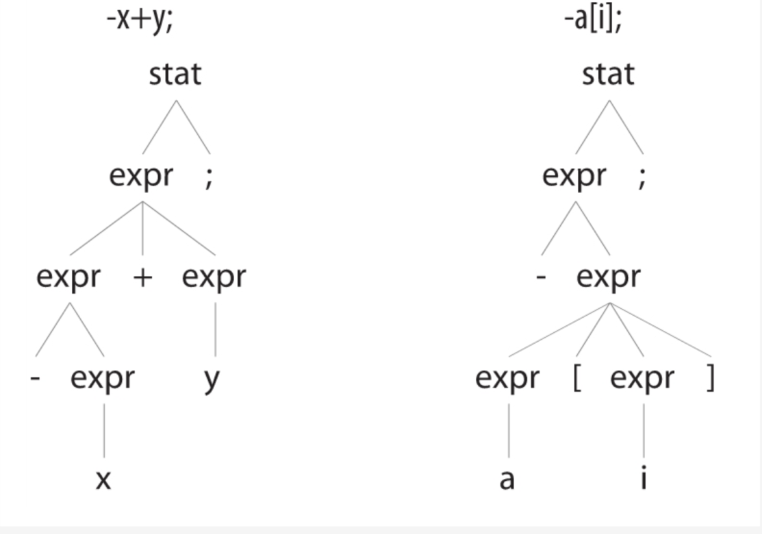
左侧的语法分析树显示了一元取反运算符和x紧密地结合在一起,因为它比加法的优先级更高。这是由于取反表达式的备选分支在加法表达式之前。另一方面,由于取反表达式的备选分支在数组索引表达式之后,取反运算符的优先级比数组索引运算符低。右侧的语法分析树显示,取反运算符被应用在a[i]之上,而非标识符a。


















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











