 深度学习模型内存优化:性能提升分析
深度学习模型内存优化:性能提升分析








 超级会员免费看
超级会员免费看
 评估了移除动态内存操作对模型性能的影响,通过对比编译及运行前后,发现推理延时从875ms降低到742ms,性能提升约15%,证明优化效果显著。
评估了移除动态内存操作对模型性能的影响,通过对比编译及运行前后,发现推理延时从875ms降低到742ms,性能提升约15%,证明优化效果显著。
本节评估一下,通过删除字符串拼接操作和移除所有内存的动态申请操作之后,对于模型的性能提升。
评估下性能
在相同的环境下,分别运行 3rd_preload 和 4th_no_malloc 下的 compile.sh 脚本进行代码编译,然后运行编译后生成的可执行文件 ./resnet。
可以分别获取到权值预加载前后的性能指标。
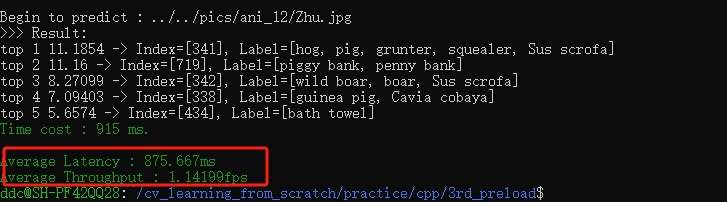
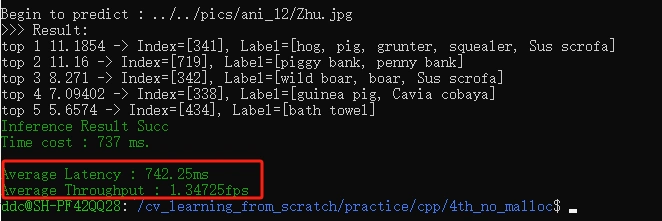
可以看到性能提升非常明显:优化前平均推理延时为 875ms,优化后为 742 ms,性能提升了大概 15%,还是很不错的。
注意:不同电脑机器不同环境下测出来的性能会有差异,大家只需要比对性能提升的相对值即可。


















 2129
2129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











