




文章目录
综合
面试官:谈谈你对Mysql数据库读写分离的了解,并且有哪些注意事项?
约束、key、索引
MySQL——约束(constraint)详解
MySQL(五) MySQL中的索引详讲
【原创】MySQL(Innodb)索引的原理
多个单列索引和联合索引的区别详解
MySQL 覆盖索引详解
mysql 外键(foreign key)的详解和实例
MySQL外键约束_ON DELETE CASCADE/ON UPDATE CASCADE
B+树看这一篇就够了(B+树查找、插入、删除全上)
作为a阶节点,其实指的就是某个节点维护了a个key,并且有几个指向子节点的指针。在 MySQL 中,InnoDB 存储引擎的数据底层存储通常是按照主键来排列的,这种存储方式称为聚簇索引。那么为什么不要在中间节点存储指向数据的指针,一个原因是将原本用来存指向数据的指针的空间用来多存几个key好不好,这样树就会矮胖。
为什么 MySQL 使用 B+ 树
理解I/O:随机和顺序
比如提取id介于4-9的值,对于B+树,只要找到了根据索引定位到了id=4这一条数据,那么磁盘顺序往下查找即可找到4-9的数据;但对于B树,需要先根据索引定位id=4在磁盘上的位置,然后再根据索引定位id=5在磁盘上的位置,以此类推。
MySQL自增主键id不连续的原因
联合索引在B+树上的存储结构及数据查找方式
数据库数据类型
MySQL常见的数据类型(八)
MySQL之char、varchar和text的设计
1、 char长度固定, 即每条数据占用等长字节空间;适合用在身份证号码、手机号码等定。
2、 varchar可变长度,可以设置最大长度;适合用在长度可变的属性,但数量上限确定的情况下;
3、 text不设置长度, 当不知道属性的最大长度时,适合用text。比如地址;
「MYSQL」MYSQL中的int(11)到底代表什么意思?
时间
Mysql的timestamp(时间戳)详解以及2038问题的解决方案
MySQL 日期类型函数及使用
mysql TIMESTAMP 不能为NULL,但是datetime可以为null
是否为null要参照另一个配置;
数据定义语言DDL
mysql在B数据库下创建一个与A数据库中一样的表
MySQL表的四种分区类型
MySQL HASH分区
MySQL KEY分区
MySQL存储引擎之Myisam和Innodb总结性梳理
【原创】杂谈自增主键用完了怎么办
mysql 5.6 在线 DDL
old_alter_table=0,不启用旧的copy the table 的模式来进行ddl操作;
最后一个例子似乎少了个session,表明的是select没问题,但是update会被block
数据查询语言DQL
LEFT JOIN 和JOIN 多表连接
SQL的各种连接Join详解
oin是先笛卡尔积,然后再筛选,所以如果on条件里出现了or并且两个条件都满足,那么这条就会重复
left join 连表时,on后多条件无效问题
ON 条件(“A LEFT JOIN B ON 条件表达式”中的ON)用来决定如何从 B 表中检索数据行。如果 B 表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为 NULL 的数据
select * from A left join B on A.id=B.id and A.user='zzz'的含义是,如果B表中存在一条数据,满足A.id=B.id的同时,对应A表的这个user数据等于zzz,那么就是一个成功的join,否则就会生成一行null作为B表的数据
查询mysql 中某字段为空值的数据
浅析MySQL中exists与in的使用 (写的非常好)
关于SQL中Union和Join的用法
Union不适用与表中存在完全相同的两列的情况,因为这样会删除重复的表;
MySQL 的CASE WHEN 语句使用说明
MYSQL–表分区、查看分区
mysql 行转列 列转行
SETSQL_SAFE_UPDATES=0
mysql中实现类似于oralce中row_number()的方法
MySQL里的found_row()与row_count()的解释及用法
使用MySQL子查询选择第n个最高纪录
MYSQL常用内置函数详解说明
MySQL 字段的说明和备注信息
sql虚构一个常量字段的查询
FROM_UNIXTIME 格式化MYSQL时间戳函数
SQL 随机抽取样本
MySQL之CONCAT()的用法
MySQL group_concat()函数
MySQL Prepared语句
#多变量情况
PREPARE stmt1 FROM 'SELECT productCode, productName
FROM products
WHERE productCode = ? or productCode = ?';
SET @pc1 = 'S10_1678';
SET @pc2 = 'S10_1949';
EXECUTE stmt1 USING @pc1,@pc2;
DEALLOCATE PREPARE stmt1;
MySQL 5.7新特性之Generated Column
Oracle生成不重复字符串 sys_guid()与Mysql生成唯一值
Mysql 默认生成分布式主键UUID
mysql 默认值除了timestamp不支持其他函数,不允许 default uuid()格式,只能通过触发器实现
数据操纵语言DML
mysql在表的某一位置增加一列、删除一列、修改列名
如何让mysql的自动递增的字段重新从1开始呢?
mySql中删除(truncate,delete,drop)的用法
Mysql on duplicate key update用法及优缺点
数据控制语言DCL
MySQL存储过程中declare和set定义变量的区别
MySQL存储过程参数
存储过程在启动时无法访问OUT参数的初始值。
存储过程
MySQL数据库存储过程
调整分隔符DELIMITER //是以为在终端操作的,存储过程中不可避免要输入;,而如果不修改分隔符的话,当终端看见;,终端就会认为到头了。
设置
(转)解决mysqldump: Got error: 1290以及secure-file-priv option简解
Windows下更改MySQL数据库的存储位置
如何重启MySQL,正确启动MySQL
【MySQL】MySQL的配置文件的区别和说明
/etc/mysql/my.cnf->/etc/alternatives/my.cnf -> /etc/mysql/mysql.cnf
tmd我是整不明白这么连接一下有啥用,而/etc/mysql/mysql.cnf引用了两个文件夹下面的配置
其中d结尾的代表的是服务配置,linux都这样,例如mysqld
sql_mode
variables
【MySQL】explicit_defaults_for_timestamp 参数详解
配置文件
mysql配置文件优化
别忘了在使用mysql之前就决定好要不要拆分表空间;
权限管理
MySQL创建用户与授权
Mysql用户管理
Mysql 用户权限管理
mysql.user存放用户账户信息以及全局级别(所有数据库)权限,决定了来自哪些主机的哪些用户可以访问数据库实例,如果有全局权限则意味着对所有数据库都有此权限
而mysql.db表:存放具体某个数据库级别的权限,决定了来自哪些主机的哪些用户可以访问此数据库
例如,select * from mysql.user;
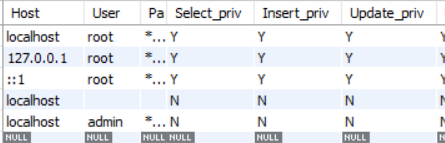
前三行是root用户,拥有全部权限,第三行是匿名用户,第四行是我新建的admin用户,该表中表明该用户全局权限为空
此时来执行select * from mysql.db;,结果如下
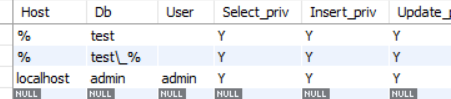
第三行表明,来自localhost的admin用户对数据库admin有着全部权限,而前两行表明,来自任何地方的匿名用户(其实实际意义为任何用户),都可以访问test数据库,以及以名称test_开头的数据库
再来执行show grants for admin@'localhost';
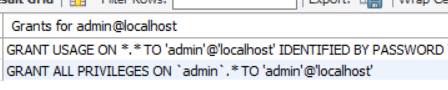
可以看到结果是与db对应的,经过实验表明,grant select on db.* to a_user@会影响db表并进而影响show grants的值,当然还有其他的权限表,应该大差不差。
MySQL : Access denied for user ‘’@‘localhost’ to database 'mysql’问题看点。
%’并不包括localhost
mysql全局权限账户%登录不上
如果一个用户在user表里只有admin@%,那么在本地登录的时候,是无法登录到localhost的,只能不输密码当做一个匿名用户登录
Mysql 1044错误代码:Access denied for user ‘’@'localhost’的解决方案
上面这边博客实际上是通过删除匿名用户来解决问题,并不推荐。
新建用户,并指定其只能访问某个数据库
首先创建用户CREATE USER 'admin'@'localhost' IDENTIFIED BY 'xxxx';,此时用户的权限是空的,什么库都访问不了
然后赋予admin这个db的权限,grant all privileges on admin.* to 'admin'@'localhost';
然后刷新权限flush privileges;
如果要赋予某个db的select权限,可以使用grant select on root_own.* to 'admin'@'localhost' ,这会同时更新mysql.db库,新增一行;收回权限revoke select on root_own.* from 'admin'@'localhost';的时候,也会更新mysql.db库,删除一行。
主从复制
带你了解 MySQL Binlog 不为人知的秘密
MySql 主从复制及配置实现
MySQL 主从复制原理不再难
MySQL主从配置详解
MySQL主从复制-从库如何切换主库
Mysql解决主从慢同步问题(上)
Mysql解决主从慢同步问题(下)
好文章!主从复制默认是单线程的,但可以手动开启多线程从库执行binlog,这需要master开启组提交事务。
事务
ACID
事务ACID理解
隔离性是怎么实现的呢?看起来不会出现下面这种情况:事务写到了一半,然后断电了,发现结果是写了一半时候的状态;
如何理解数据库事务中的一致性的概念?
从一个正确的状态到另一个正确的状态,事务提交前后的状态保持一致
MySQL嵌套事务的讨论
mysql不支持嵌套事务,换句话说,同一个连接,最多只能同时拥有一个事务。
隔离级别
数据库事务隔离级别-- 脏读、幻读、不可重复读(清晰解释)
幻读请看后面的博客
MySQL隔离级别
隔离级别之可重复读级别解读
进行实验之前,要先准备两个会话,因为同一个连接不能同时拥有多个事务

- 上述实验里,a3的结果与a1一样,这说明没有发生“不可重复读”,如果此时的隔离级别是“读提交”,那么a3的结果就是事务B提交后的结果;
- a4的结果表示,事务A读取到了事务B对数据的更新结果;你会问这是可重复读啊,前后结果应该相同才对啊。这是因为a4之前,事务A进行了update操作,进行了所谓当前读的操作。类似地,在事务A里也不可执行
insert into users(id,name,age) values(3,'zbz',18);操作,因为这也会导致幻读。这才是幻读,就是本事务里看到的明明存在,但是就是执行不了。 - a5尝试对事务B删除的数据进行更新,发现此时数据库此数据已经被删除了,所以事务A发现怎么更新第二条数据都无法实现(影响的row的数目为0),这也是一种幻读,读取到了本不存在的数据。a6同理。
- 所以幻读和不可重复读的区别在于:可重复读,那么只要没提交(且不带锁读),那同一个事务里前后读到的结果就是一模一样的(不可重复读就是反过来);但幻读的意思是说,即使你读到了一模一样的数据,这个数据也可能是不存在的,像幻影一样。
关于幻读,可重复读的真实用例是什么?
read-do的过程中,do的时候失败了;例如读取数据的时候明明没有id为3的数据,但就是插入不进id为3的新数据(即第一个read没读取到本存在的数据);又例如,读取数据的时候明明有id为3的数据,但对其进行更新就是总失败(即第一个read读到了本不存在的数据)。
第一次select是读取,第二次的 insert 其实也属于隐式的读取,只不过是在 mysql 的机制中读取的,插入数据也是要先读取一下有没有主键冲突才能决定是否执行插入。
串行隔离的时候,读取也会加上锁
【mysql】mysql修改事务隔离级别(session和global)
锁
通过各种简单案例,让你彻底搞懂 MySQL 中的锁机制与 MVCC
drop table `users`;
CREATE TABLE `users`
(
id int auto_increment,
c1 int,
c2 int,
c3 int,
PRIMARY KEY (`id`),
unique index idx_t_c1 (`c1`),
index idx_t_c2 (c2)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
TRUNCATE users;
INSERT INTO users (C1, C2, C3)
VALUES (1, 1, 1),(2,1,1),(3,2,2),(4,2,2),
(0,0,0),(5,5,5),(10,10,10),(15,15,15),(20,20,20),(25,25,25);;
SELECT *
FROM users;
SELECT @@tx_isolation;
start transaction;
SELECT * FROM users WHERE id = 1 FOR UPDATE;
SELECT * FROM users WHERE c1 = 1 FOR UPDATE;
SELECT * FROM users WHERE c2 = 1 FOR UPDATE;
commit;
行锁都是挂在索引上的,并且行锁的最细粒度就是行,无论这个行锁是通过哪个index加上的,举例来说,对于如下数据,c2只是普通索引,如果事务1执行了SELECT * FROM users WHERE c2 = 2 FOR UPDATE;,事务2再执行SELECT * FROM users WHERE id = 1 FOR UPDATE;也会阻塞掉;
| id | c2 |
|---|---|
| 1 | 2 |
| 2 | 2 |
可以看到,锁都是与索引直接挂钩的;加锁也都是基于索引来为某一行加上锁的。
而间隙锁的间隙是如何确定的?答:表中所有数据的间隙都是一个合规的间隙,例如针对c3列的间隙包含(-无穷,0)/(0,1)/(1,2)/(2,5)/(5,10)等等。
MySQL锁释放时机(事务)
读懂上面的之后,读下面的一组文章更好,因为下面的文章里有一些概念讲的比较简略
MySQL学习笔记2——事务的隔离级别、幻读
幻读的例子我觉得有点= =偏颇,这只是当前读导致的,看个意思就行,不过其他部分写的恩很好,不算是幻读,幻读是没读到存在的或者读到了不存在的数据;
解决幻读这一部分举的这几个例子实际上执行不下去的(因为session B会block住的),只是说假设能执行下去,会有什么问题。这一块实际上是为了讲解,在对d=5加锁操作时,即使对d=5的全部行加上了锁,也会造成问题的;
所以mysql引入了间隙锁,在这个栗子里,如果事务A使用了select * from users where d=5 for update ;,生成了7个间隙锁,间隙锁的作用对于间隙(1,5),即无法操作d取值在(1,5)范围内的行,也无法新增d取值在(1,5)的行,也就是说另一个事务的下面的sql都会被block住;
update users set c3=100 where c3=5;
insert into users (C1, C2, C3) values (12,12,12);
所以最终结果就是将整表锁住;所以说基于非索引字段来加锁,这样是非常不好的;
MySQL学习笔记4——锁
案例绝了;描述一下。
问题:这实际上就是幻读造成的数据不一致;
解决1:文中没说,我想的,其实串行或者加for update就好了,事务1里,A关注B的时候select for update一下然后insert,即使此时事务2需要做B关注A并且读取AB关系的时候没读到A关注B,此时事务2如果再做insert操作,会触发死锁,导致事务失败,这也是一个好现象,维护了一致性;至于事务2为什么会死锁呢?因为select for update会加间隙锁,防止insert。
后面就列举了mysql加锁的一些规则,比如是如何根据索引的值来加上next-key锁的,又是怎样退化成行锁或者间隙锁的。这个建议看下面的知乎回答。不过要知道加锁的基本单位是 next-key lock 以及是直接基于索引来加锁,以及基于索引来优化所加的锁。
MySQL 是怎么加行级锁的?为什么一会是 next-key 锁,一会是间隙锁,一会又是记录锁?
为什么有这么复杂的加锁逻辑?首先要明白两点:
- 加锁的目标:在确保数据一致性的前提下,尽可能少锁一些行,同时能够快速确认锁的范围。
- 加锁的方式:所有的锁都是基于index的,并且是基于已存在的数据的,一个不存在的数据无法加上锁。所以才会出现间隙锁这么个东西,比如数据里有id=1和id=5两条数据,当我select where id=4,因为不存在数据,我需要锁住1~5的区间不能插入任何数据。
- 正确理解间隙锁:一个非唯一键的age_idx上的间隙锁(21,22],表现上来看确实是无法插入任何age=(21,22]的数据,但是在实现上,其实是非聚簇索引树的两个叶子节点(存储主键key)中间无法插入任何数据。如下所示,实际上是(age=21,id=5)和[age=22,id=10]之间不允许插入任何叶子节点,那哪些叶子按理会会插入到这里呢?比如(age=21,id=6)。进一步说,对于这个非唯一索引上的key,我是有可能加入(age=22,id=199)这么个值得,因为间隙锁只包到了(age=22,id=10),也因此,我还需要再加上一个(22,39)的间隙锁才能保证所有age=22的数据不会被插入。而唯一性索引就不会有这个问题,因为诶不可能再出现一个age=22的数。
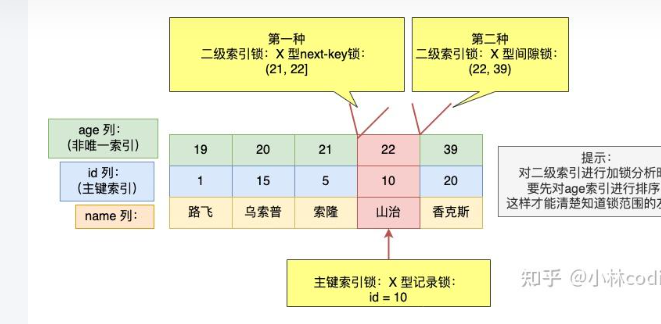
MySQL学习笔记5——事务一致性视图、MVCC
写的可好了,
解释:“ row trx_id的不同情况”里的情况3,数组指的是本事务(记为事务A)启动时,看到的正在运行的事务;
- 如果某个数据的
row trx_id在数组之中,代表着在事务A启动的时候,更新这个数据的事务也在运行之中,那么这个数据不可见; - 那什么情况会造成某个数据的
row trx_id不在数组之中呢?很简单,比如mysql库建表以来的第一个事务(假设id为1)过了十年还没提交,但后来的事务都提交了,那么对于事务A来说这个低水位就是1,但trx_id=2的事务已经完成了,如果那么这个row trx_id=2不在数组里,说明此时这个row trx_id=2相关的事务一定已经执行完了,该数据可见;
文章里有一句话:更新数据都是先读后写的,而这个读,只能读当前的值,称为“当前读”(current read)。意思是每一条update语句都会分成两步,第一步先去读取要update的行;然后进行update,所以就可以理解究竟是什么造成了幻读:select的时候,数据的(修改)row txid满足可以被检索到的条件,并且(删除)row txid也大于本事务id,所以可以读到,但是update的时候需要的是当前读,当前读的话,就tmd读不到;
2025年4月25日:针对这句话有点新想法,我觉得他说的不对,更新数据并不是“先读后写”,而只是因为这个sql刚好是set k=k+1需要将现有的值读出来,而之所以读出来的k是2,这是因为update操作肯定只能在当前数据上操作,也就是说update的操作本身就是基于最新的数据进行操作的。不过这也确实造成了幻读,因为select默认是快照读,而update只能是当前写,所以就会出现,明明A线程select where age=1能看到数据,如果此时有个B线程做了update set age=6 where age=5,A线程update where age=5;就是update不到
——————————————
总结一下:
- mvcc解决了不可重复读的问题,而无法解决幻读问题,因为幻读本身就是实际情况和我所看到的不一样,之所以不一样,恰恰就是因为mvcc导致的多版本问题和当前读写导致的冲突。
- 导致幻读的根本原因是并发,解决并发靠的是锁,mvcc解决不了并发问题。。
全面深入理解MySQL自增锁
深入剖析 MySQL 自增锁
为什么statement的binlog主从同步不能开启交叉模式,不是因为从库是并发执行主库的statement的,而是因为主库可以并发执行一些sql,因为自增锁本身就只是自旋锁,如果AB两个线程并发执行insert,不一定哪个线程的sql会获得锁,而从库在执行statement的时候不可能知道到底是A先执行还是B先执行,,可能固定写好的就是先A后B,那么就导致主键不一致了。
设计
树结构
干货:在关系型数据库中优雅地存储树形结构
怎样在 MySQL 表中存储树形结构数据? - 知乎
在MySQL中存储树状结构
优化
【好文】MySQL索引原理及慢查询优化
第一条sql 原本做的事情是将BC表join起来,然后与A进行查询;问题就在BC表
join在一起非常大,优化方案就是ABjoin,然后ACjoin,结果去重就好了
MySQL explain 应用详解(吐血整理🤩)
长达 1.7 万字的 explain 关键字指南!
分页
深入浅出 MySQL 优先队列(你一定会踩到的order by limit 问题)
MySQL深度分页的问题及优化方案:千万级数据量如何快速分页
日志
慢查日志
undo日志
MySQL · 最佳实践 · 在线收缩UNDO Tablespace
binlog
mysql 基于binlog恢复
数据库故障恢复机制的前世今生
ARIES算法保障了数据库的故障恢复,核心就是同时使用redo log和undo log,康神,Redo-Undo Logging的落盘顺序为redo+undo log 落盘 + commit标记落盘。 data刷盘随意是吧?允许在commit标记前是吧?如果data page刷早了还没commit,同时crash了通过undo 进行修正对吧?对
庖丁解InnoDB之REDO LOG
庖丁解InnoDB之Undo LOG
关于Innodb undo log的刷新时机?
MySQL中的Undo Log严格的讲不是Log,而是数据,因此他的管理和落盘都跟数据是一样的:
- Undo的磁盘结构并不是顺序的,而是像数据一样按Page管理Undo写入时,也像数据一样产生对应的Redo Log
- Undo的Page也像数据一样缓存在Buffer Pool中,跟数据Page一起做LRU换入换出,以及刷脏。
- Undo Page的刷脏也像数据一样要等到对应的Redo Log 落盘之后
上面几篇文章都相当硬核,查到这几篇文章都只是源于一个疑惑:redo log和bin log都有buffer,还为此新增了两阶段提交,那undo log呢?
要结合mvcc理解一下,mvcc中,数据库需要记住某个数据的修改之前是什么样的,假如说一条数据目前在buffer pool里,我们可以通过undo log,可以反向执行一步、两步,从而知道他被第一次修改之前的结果、被第二次修改之前的结果。所以逻辑上讲,这个undo log起到的作用本身就是“数据”的作用,并且这个undo log是和这条数据强绑定的。如果一个数据需要从buffer pool里刷出去,那么这条数据对应的undo log也需要被刷回到硬盘上。
Innodb这种事实上是undo 通过undo段生成undo page,undo page跟数据一起被当做修改写redo log, redo log通过多个mtr落盘。重启时先回放redo,从redo构造undo page再undo掉回滚的事务。
因为undo log本身相当于记录了数据的历史版本,所以相当于“写入历史版本数据”这么个操作,而在innodb中,这么个操作被看做update、insert操作一样,需要写入redo log,相当于redo log里不仅记录了真实的数据库操作,还记录了生成undo log的操作。
另外,因为未完成的事务对应的数据可能并不在buffer pool,因此,如果这类事务执行一半挂掉了,可以根据redolog中的undo log进行数据恢复。
其他
MySQL执行外部sql脚本文件的命令
MYSQL优化 Analyze Table
Mysql面试
开发如下脚本,然后执行sh dump_db.sh 'select * from tb' > result.txt
#/bin/bash
if [ $# -ne 1 ];then
echo "Usage: bash run_sql_dump.sh sql [ > result.txt]"
exit
fi
sql=$1
mysql -h127.0.0.1 -P3306 -udev -proot my_db --default-character-set=utf8 -e "$sql"
故障修复
MySQL根据离线binlog快速“闪回”
就是新建了一堆库,然后用binlog重跑了一次;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









