




一、 LORA 与 LORA 微调简介
LORA(Low-Rank Adaptation) 是一种高效的参数高效微调方法,其核心思想是通过在预训练模型的权重矩阵中引入低秩适配矩阵(低秩分解矩阵 A 和 B),仅对这部分新增参数进行训练,从而大幅减少计算和显存开销。与传统全参数微调相比,LORA 通过冻结原始模型参数,仅更新适配层参数,实现了轻量化训练。
在涉及到矩阵相乘的模块,在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)。
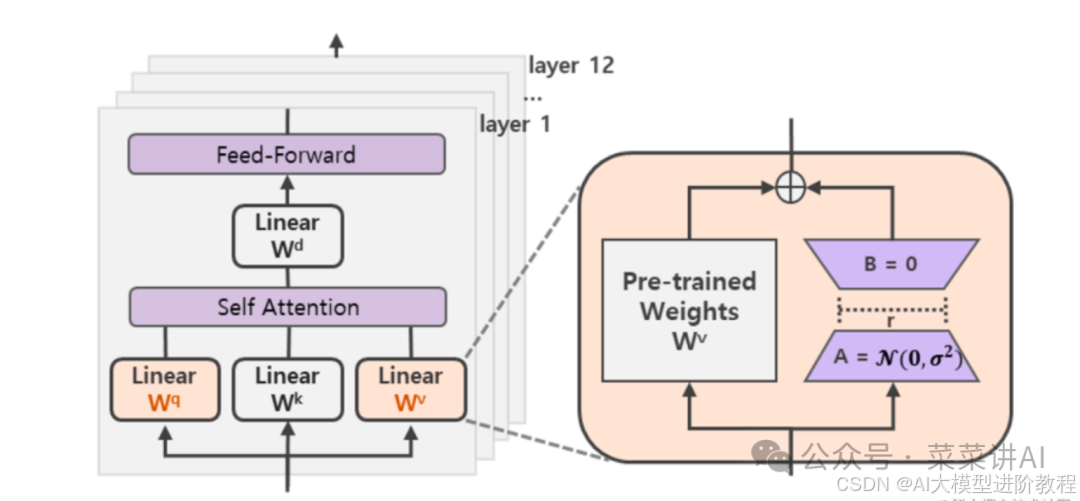
LORA 微调 的具体实现是通过 peft(Parameter-Efficient Fine-Tuning)库,结合 transformers 框架完成。例如,在 DeepSeek-7B 模型中,LORA 可针对注意力机制的关键层(如 q_proj、v_proj)进行适配,保留模型通用能力的同时,快速适应特定任务需求。
二、LORA 微调的优势与特点
资源占用低
通过仅训练低秩矩阵(如秩 r=8),显存需求可降低 5-10 倍。例如,DeepSeek-7B 在 4bits 量化后,显存占用仅需约 6GB,支持消费级显卡(如 RTX 3090)训练。
训练速度快
参数更新量减少 90% 以上,训练速度显著提升。实验显示,1200 条数据的微调可在 5 分钟内完成。
灵活适配场景
支持动态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2343
2343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









