



 本文探讨了MySQL主从复制的不同模式,包括完全异步、完全同步和半异步,以及如何通过自适应哈希索引提高非聚集索引性能。深入解析了索引结构、页大小、B+树存储和双写缓冲机制,以提升数据库性能和可靠性。
本文探讨了MySQL主从复制的不同模式,包括完全异步、完全同步和半异步,以及如何通过自适应哈希索引提高非聚集索引性能。深入解析了索引结构、页大小、B+树存储和双写缓冲机制,以提升数据库性能和可靠性。
mysql 主从复制,完全异步,完全同步(客户端提交事务后,从库都立刻同步,并完成事务返回),半异步是,至少同步一个从库同步成功即可,但是也有主体挂了的问题。
MySQL架构图解_oneslide-优快云博客_mysql架构
explain sql关键字 MySQL Explain详解 - 杰克思勒(Jacksile) - 博客园
id:选择标识符 selsct 的id
select_type:表示查询的类型。
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型 ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
mysql 的page大小是16k(默认),两层 16*16 就能放很多索引
一个叶子节点有多少字节可以存放指向下一节点的指针,取决于主键的类型,比如bigint是8字节,而指针又占用6字节,所以指针可以指向1170个非叶子节点: 16384 / (8+6)= 1170 个非叶子节点
同理,指向叶子节点的个数也可以是1170个,那么3层高的一颗B+树可以存储:
第一层指向1170个非叶子节点,第二层再指向1170个叶子节点,1170 * 1170 = 1368900 个叶子节点
那么假设一条记录1KB大小,那么一页16KB就可以存储16行,那么 16行 * 1368900 个叶子节点 = 21902400 行。
MySQL聚集索引和非聚集索引 - 昕友软件开发 - 博客园
聚集索引是 数据是按索引排序聚集在一起的,例如id ,非聚集就是又索引下的数据是分散的
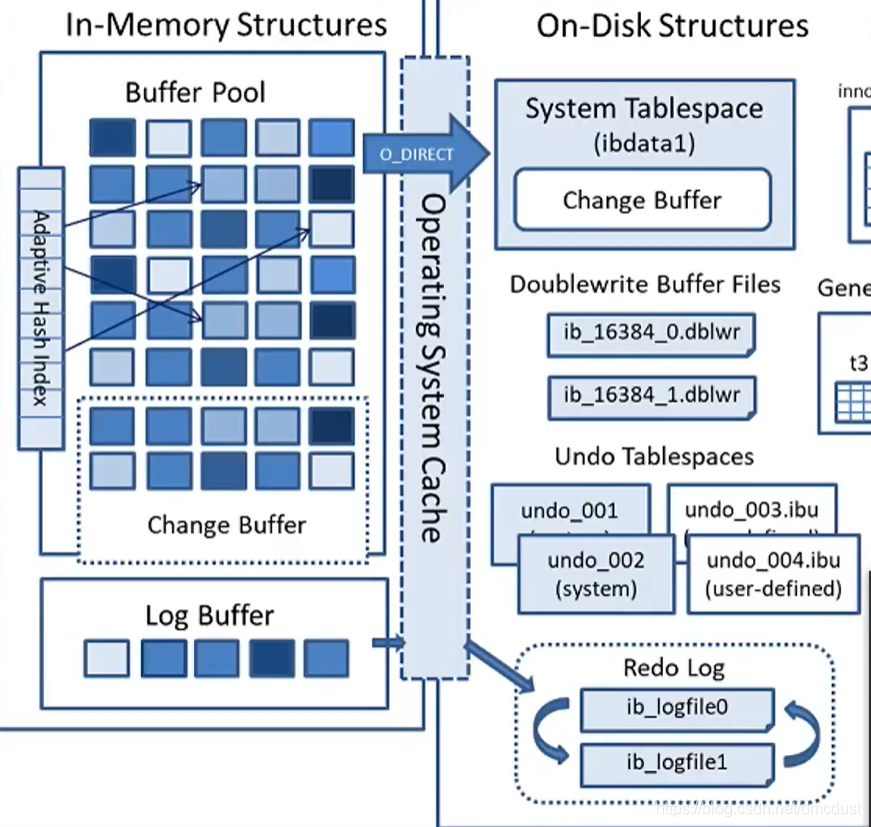
baffer pool
flush 链表 标记带刷新,到硬盘的,
free 链表 标记空闲的缓存页,可以从加载磁盘中加载
lru 链表
冷区:3 查询间隔超过1秒 ,会被更新到热区,如果是全表拉取,数据页,会很快被读操作,会判断为不常用。
热区:5
redo log 写 和log buffer ,多个循环写
原子性( Atomicity )、一致性( Consistency )、隔离性( Isolation )和持续性( Durability )。
读未提交,读已提交,可重复读,可串行化。
MVCC:每个事务有自己的 id ,拿到数据快照,redolog 和 undolog 会根据事务id 记录变化,考指针穿起来
MVCC使得数据库读不会对数据加锁,select不会加锁,提高了数据库的并发处理能力
doublewrite buffer
change buffer
三大特性
插入缓存
插入缓存:插入缓冲,并不是缓存的一部分,而是物理页,对于非聚集索引的插入或更新操作,不是每一次直接插入索引页.而是先判断插入的非聚集索引页是否在缓冲池中.如果在,则直接插入, 如果不再,则先放入一个插入缓冲区中.然后再以一定的频率执行插入缓冲和非聚集索引页子节点的合并操作. 例子就是批量做更好
使用条件:非聚集索引,非唯一
为什么对于非聚集索引(非唯一)的插入和更新有效?
还是用还书的例子来说,还一本书A到图书馆,管理员要判断一下这本书是不是唯一的,他在柜台上是看不到的,必须爬到指定位置去确认,这个过程其实已经产生了一次IO操作,相当于没有节省任何操作。所以这个buffer只能处理非唯一的插入,不要求判断是否唯一。聚集索引就不用说了,它肯定是唯一的,mysql现在还只能通过主键聚集。
自适应索引
索引的资源消耗点
1、树的高度,顺序访问索引的数据页,索引就是在列上建立的,数据量非常小,在内存中;
2、数据之间跳着访问
1、索引往表上跳,可能需要访问表的数据页很多;
2、通过索引访问表,主键列和索引的有序度出现严重的不一致时,可能就会产生大量物理读;
资源消耗最厉害:通过索引访问多行,需要从表中取多行数据,如果无序的话,来回跳着找,跳着访问,物理读会很严
自适应索引:Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升,hash索引直接到数据页.
由于innodb不支持hash索引,但是在某些情况下hash索引的效率很高
特点:1、无序,没有树高 2、降低对二级索引树的频繁访问资源 ,索引树高<=4,访问索引:访问树、根节点、叶子节点 3、自适应
缺陷: 1、hash自适应索引会占用innodb buffer pool; 2、自适应hash索引只适合搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的; 3、极端情况下,自适应hash索引才有比较大的意义,可以降低逻辑读 .
两次写(doublewrite):如果说插入缓冲是为了提高写性能的话,那么两次写是为了提高可靠性,牺牲了一点点写性能。
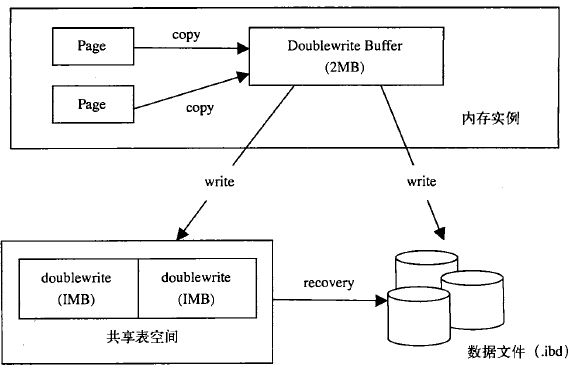
两次写需要额外添加两个部分:
1)内存中的两次写缓冲(doublewrite buffer),大小为2MB
2)磁盘上共享表空间中连续的128页,大小也为2MB
其原理是这样的:
1)当刷新缓冲池脏页时,并不直接写到数据文件中,而是先拷贝至内存中的两次写缓冲区。
2)接着从两次写缓冲区分两次写入磁盘共享表空间中,每次写入1MB
3)待第2步完成后,再将两次写缓冲区写入数据文件
这样就可以解决上文提到的部分写失效的问题,因为在磁盘共享表空间中已有数据页副本拷贝,如果数据库在页写入数据文件的过程中宕机,在实例恢复时,可以从共享表空间中找到该页副本,将其拷贝覆盖原有的数据页,再应用重做日志即可。

















 174万+
174万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









