




随机森林(Random Forest)是机器学习中最强大且应用广泛的算法之一,它结合了多个决策树的预测能力,在分类和回归任务中都表现出色。本文将深入解析随机森林的工作原理,解释其背后的集成学习数学依据,并提供完整的 Python 实现示例。
集成学习:随机森林的理论基础
随机森林属于集成学习(Ensemble Learning)的一种,其核心思想是 "三个臭皮匠赛过诸葛亮"—— 通过组合多个弱学习器(通常是决策树)的预测结果,获得比单个强学习器更好的性能。
集成学习的数学依据
假设有n个独立的分类器,每个分类器的错误率为p(\(p < 0.5\),即分类器性能略好于随机猜测)。根据大数定律,当使用简单多数投票时,集成分类器的错误率P可以用二项分布表示:
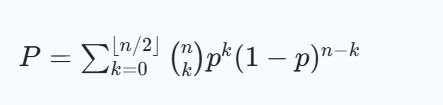
随着n增大,这个错误率会指数级下降并趋近于 0。这就是集成学习能够提高性能的理论基础。
随机森林的两大随机性
随机森林通过引入两种随机性来保证基学习器之间的独立性:
- 样本随机性:每个决策树都基于训练集的 bootstrap 抽样(有放回抽样)构建,每个决策树不会学习到全部数据,因为部分数据不具有代表性,会影响测试结果,为了取核心关键数据,每个决策树都不会完全训练。
- 特征随机性:每个决策树在分裂节点时,仅从随机选择的特征子集里挑选最优分裂特征
这两种随机性使得森林中的决策树具有足够的多样性,从而保证了集成效果。
随机森林的工作流程
随机森林的构建过程可以概括为以下步骤:
- 从原始训练集中通过 bootstrap 抽样生成k个不同的子集
- 为每个子集构建一棵决策树:
- 树的每个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1542
1542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









