



一、PCA是什么?
主成分分析(Principal Component Analysis,PCA)是机器学习中最常用的降维技术之一,它通过线性变换将高维数据投影到低维空间,同时保留数据的最重要特征。PCA由卡尔·皮尔逊于1901年发明,如今广泛应用于数据可视化、特征提取和噪声过滤等领域。
二、PCA的数学原理
1.1 向量与内积
PCA的核心建立在向量运算基础上。给定两个n维向量:
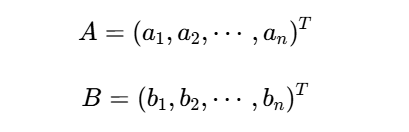
它们的内积定义为:
A⋅B=a1b1+a2b2+⋯+anbn=∣A∣∣B∣cos(θ)
其中θ是两向量夹角,|A|表示向量模长:
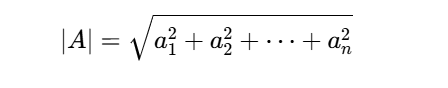
几何意义:当|B|=1时,A·B表示A在B方向上的投影长度。
1.2 基与基变换
在n维空间中,基是一组线性无关的向量,任何向量都可表示为基的线性组合。标准正交基满足:
- 每个基向量模长为1
- 任意两个不同基向量正交(内积为0)
基变换公式:设旧基为e1,e2,...,en,新基为p1,p2,...,pn,向量v在新基下的坐标为:
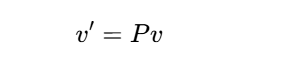
其中P的行向量由新基向量组成。
2.1 优化目标
给定m个n维数据点X=[x1,x2,...,xm],PCA寻找k维(k<n)子空间,使得:
1.最大方差准则:投影后数据方差最大化
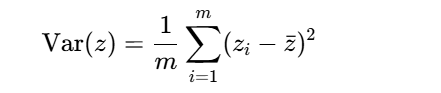
2.最小重构误差:重构数据与原数据误差最小化
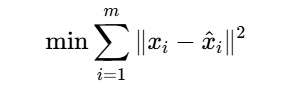
这两个目标实际上是等价的。
2.2 协方差矩阵
数据经过中心化处理后(均值为0),协方差矩阵为:
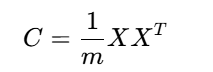
其元素Cij表示第i维和第j维特征的协方差:
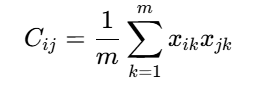
2.3 特征值分解
PCA的关键是对协方差矩阵C进行特征值分解:
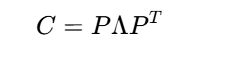
其中:
-
Λ是对角矩阵,对角元素λ₁ ≥ λ₂ ≥ ... ≥ λₙ为特征值
-
P的列向量是对应的特征向量,构成新的正交基
方差解释:第i个主成分的方差等于λᵢ,总方差为∑i=1nλi
2.4 降维过程
选择前k个最大特征值对应的特征向量组成投影矩阵Pk,降维数据:
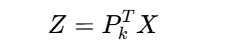
重构数据:
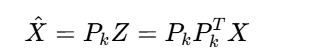
3. PCA算法步骤
3.1 理论步骤
- 数据标准化:每维特征减去均值
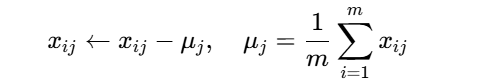
2.计算协方差矩阵:
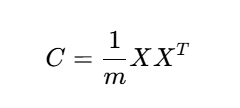
3.特征值分解:
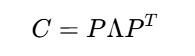
4.选择主成分:按特征值从大到小排序,选择前k个
5.数据投影:
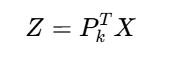
3.2 数值稳定性考虑
实际计算中,常使用奇异值分解(SVD)代替特征值分解:
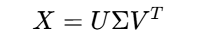
此时:
右奇异矩阵V的列向量即为主成分方向
奇异值σᵢ与特征值关系:λi=σi2/m
三、PCA代码
1. PCA的Python实现
1.1 数据准备
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 数据标准化
X_centered = X - X.mean(axis=0)
1.2 使用scikit-learn实现PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print("解释方差比:", pca.explained_variance_ratio_)
print("累计解释方差:", np.cumsum(pca.explained_variance_ratio_))
2.项目实战
. 项目概述
本项目使用PCA(主成分分析)对鸢尾花数据集进行降维处理,然后使用逻辑回归进行分类,并比较降维前后的分类效果。
2. 代码实现与分析
2.1 数据准备与PCA降维
from sklearn.decomposition import PCA
import pandas as pd
# 数据读取
data = pd.read_excel(".\hua.xlsx")
# 数据划分
X = data.iloc[:,:-1] # 特征
y = data.iloc[:,-1] # 标签
# PCA实例化与训练
pca = PCA(n_components=0.90) # 保留90%的方差
pca.fit(X) # 训练PCA模型
# 输出PCA结果
print('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)
# 数据降维
new_x = pca.transform(X)
print('PCA降维后数据:')
print(new_x)
2.2 数据分割与模型训练
from sklearn.model_selection import train_test_split
# 数据分割
x_train, x_test, y_train, y_test = train_test_split(
new_x, y, test_size=0.2, random_state=0)
# 逻辑回归模型
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(x_train, y_train)
# 预测
train_pred = classifier.predict(x_train)
test_pred = classifier.predict(x_test)
print("训练集预测结果:", train_pred)
print("测试集预测结果:", test_pred)
2.3 评估指标
from sklearn.metrics import classification_report
# 训练集评估
print("训练集分类报告:")
print(classification_report(y_train, train_pred))
# 测试集评估
print("测试集分类报告:")
print(classification_report(y_test, test_pred))
3. PCA原理回顾
PCA(主成分分析)是一种常用的降维方法,其核心思想是通过线性变换将高维数据投影到低维空间,同时保留尽可能多的原始数据信息。
3.1 PCA关键步骤
1.数据标准化:将每个特征减去其均值
2.计算协方差矩阵:反映特征间的相关性
3.特征值分解:获取特征值和特征向量
4.选择主成分:按特征值大小排序,选择前k个
5.数据转换:将原始数据投影到主成分空间
3.2 数学原理
PCA的核心数学操作是协方差矩阵的特征分解:
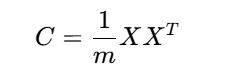
通过找到矩阵P使得:
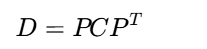
是一个对角矩阵,且对角元素按从大到小排列。
4. 结果分析与比较
4.1 降维前后模型性能比较
我们可以比较使用PCA降维前后模型的性能差异:
# 不降维的模型
x_train_raw, x_test_raw, y_train_raw, y_test_raw = train_test_split(
X, y, test_size=0.2, random_state=0)
classifier_raw = LogisticRegression()
classifier_raw.fit(x_train_raw, y_train_raw)
raw_train_pred = classifier_raw.predict(x_train_raw)
raw_test_pred = classifier_raw.predict(x_test_raw)
print("原始数据训练集分类报告:")
print(classification_report(y_train_raw, raw_train_pred))
print("原始数据测试集分类报告:")
print(classification_report(y_test_raw, raw_test_pred))
4.2 分析结论
- 降维效果:PCA可以有效减少特征维度,同时保留大部分信息
-
模型性能:对于不同数据集,PCA可能提高或降低模型性能
-
大数据集:PCA可以提高计算效率,可能提升性能
-
小数据集:PCA可能丢失重要信息,降低性能
-
-
实际应用:需要根据具体数据集和任务需求决定是否使用PCA

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









