




信用卡交易数据有个特点——欺诈交易(Class=1)极少,通常只占 0.1% 左右。
用极度不平衡的数据直接训练模型,会出现一个尴尬局面:
-
模型只要把所有人都预测成“正常(Class=0)”,准确率就能高达 99.9%。
-
但我们要抓的“欺诈”却全军覆没——这在金融场景里是不能接受的。
一、评价模型:
1.混淆矩阵 :
在完成模型训练与参数调优之后,仅凭整体准确率(accuracy)难以充分刻画分类器在高度不平衡数据上的真实表现。尤其在欺诈检测等高风险业务场景中,更为关键的是对“欺诈样本被正确识别”以及“正常样本被误报”两类错误的定量刻画。混淆矩阵(confusion matrix)通过将预测结果与实际标签进行交叉汇总,为上述问题提供了直观、可解释的诊断框架。
混淆矩阵基本形式:
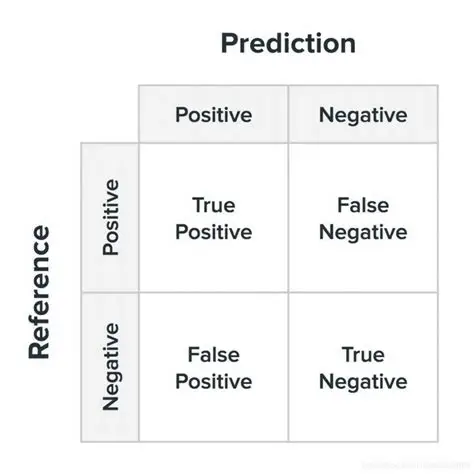
-
TP(真正例):模型正确识别出的欺诈交易数量。
-
FN(假负例):实际为欺诈却被模型误判为正常的交易数量。
-
FP(假正例):实际为正常却被模型误判为欺诈的交易数量。
-
TN(真负例):模型正确识别出的正常交易数量。
Accuracy(准确率):
accuracy = (TP+TN)/(TP+TN+FP+FN)
Precision(精确率):
precisio = TP/(TP+FP)
Recall(召回率):
recall = TP/(TP+FN)
银行真正重视的数据(真实值=1的召回率),宁可错杀绝不放过。
F1-score(F1值):
F1 = 2*(precision*recall)/(precision+recall)
一种综合数据,不注重召回率时,f1就会更为重要。
2.正则化惩罚:
正则化惩罚(Regularization Penalty)是机器学习中用于防止模型过拟合(Overfitting)的核心技术之一,通过在损失函数中引入额外的约束项,限制模型参数的复杂度,从而提升泛化能力
均方差损
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









