 树中合法括号子串问题的算法求解
树中合法括号子串问题的算法求解




题面
题目背景
本题中合法括号串的定义如下:
()是合法括号串。- 如果
A是合法括号串,则(A)是合法括号串。 - 如果
A,B是合法括号串,则AB是合法括号串。
本题中子串与不同的子串的定义如下:
- 字符串
S的子串是S中连续的任意个字符组成的字符串。S的子串可用起始位置 lll 与终止位置 rrr 来表示,记为 S(l,r)S (l, r)S(l,r)(1≤l≤r≤∣S∣1 \leq l \leq r \leq |S |1≤l≤r≤∣S∣,∣S∣|S |∣S∣ 表示 S 的长度)。 S的两个子串视作不同当且仅当它们在S中的位置不同,即 lll 不同或 rrr 不同。
题目描述
一个大小为 nnn 的树包含 nnn 个结点和 n−1n - 1n−1 条边,每条边连接两个结点,且任意两个结点间有且仅有一条简单路径互相可达。
小 Q 是一个充满好奇心的小朋友,有一天他在上学的路上碰见了一个大小为 nnn 的树,树上结点从 1∼n1 \sim n1∼n 编号,111 号结点为树的根。除 111 号结点外,每个结点有一个父亲结点,uuu(2≤u≤n2 \leq u \leq n2≤u≤n)号结点的父亲为 fuf_ufu(1≤fu<u1 ≤ f_u < u1≤fu<u)号结点。
小 Q 发现这个树的每个结点上恰有一个括号,可能是( 或)。小 Q 定义 sis_isi 为:将根结点到 iii 号结点的简单路径上的括号,按结点经过顺序依次排列组成的字符串。
显然 sis_isi 是个括号串,但不一定是合法括号串,因此现在小 Q 想对所有的 iii(1≤i≤n1\leq i\leq n1≤i≤n)求出,sis_isi 中有多少个互不相同的子串是合法括号串。
这个问题难倒了小 Q,他只好向你求助。设 sis_isi 共有 kik_iki 个不同子串是合法括号串, 你只需要告诉小 Q 所有 i×kii \times k_ii×ki 的异或和,即:
(1×k1) xor (2×k2) xor (3×k3) xor ⋯ xor (n×kn) (1 \times k_1)\ \text{xor}\ (2 \times k_2)\ \text{xor}\ (3 \times k_3)\ \text{xor}\ \cdots\ \text{xor}\ (n \times k_n) (1×k1) xor (2×k2) xor (3×k3) xor ⋯ xor (n×kn)
其中 xorxorxor 是位异或运算。
输入格式
第一行一个整数 nnn,表示树的大小。
第二行一个长为 nnn 的由( 与) 组成的括号串,第 iii 个括号表示 iii 号结点上的括号。
第三行包含 n−1n − 1n−1 个整数,第 iii(1≤i<n1 \leq i \lt n1≤i<n)个整数表示 i+1i + 1i+1 号结点的父亲编号 fi+1f_{i+1}fi+1。
输出格式
仅一行一个整数表示答案。
样例 #1
样例输入 #1
5
(()()
1 1 2 2
样例输出 #1
6
提示
【样例解释1】
树的形态如下图:
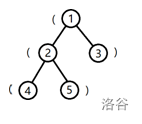
将根到 1 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (,子串是合法括号串的个数为 000。
将根到 2 号结点的字符串为 ((,子串是合法括号串的个数为 000。
将根到 3 号结点的字符串为 (),子串是合法括号串的个数为 111。
将根到 4 号结点的字符串为 (((,子串是合法括号串的个数为 000。
将根到 5 号结点的字符串为 ((),子串是合法括号串的个数为 111。
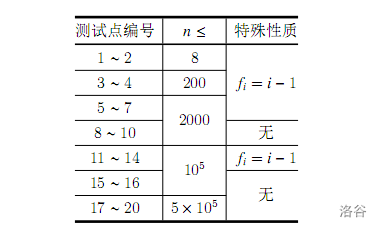
【数据范围】
第一轮尝试 最淳朴的暴力 53pts
暴力求每一个字符串的子串个数,显然遍历结点有 O(N)O(N)O(N) ,遍历子串 O(N2)O(N^2)O(N2) ,单次查询 O(N)O(N)O(N) ,共 O(N4)O(N^4)O(N4) ,预期最差能过 1∼41\sim 41∼4 号测试点(N≤200N\leq 200N≤200)
test1.cpp
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int N=5e5+10;
int n;
int h[N],e[N<<1],ne[N<<1],idx;
int res;
string str;
void add(int a,int b)
{
e[idx]=b;
ne[idx]=h[a];
h[a]=idx;
idx++;
}
bool check(string s,int a,int b)
{
int cnt=0;
a--;
b--;
for(int i=a;i<=b;i++)
{
if(s[i]=='(')
cnt++;
else
{
if(cnt)
cnt--;
else
return false;
}
}
return cnt==0;
}
int count(string s)
{
int cnt=0;
for(int len=2;len<=s.size();len++)
for(int i=1;i+len-1<=s.size();i++)
if(check(s,i,i+len-1))
cnt++;
return cnt;
}
void dfs(int fa,int u,string s)
{
s+=str[u-1];
res^=u*count(s);
for(int i=h[u];i!=-1;i=ne[i])
if(e[i]!=fa)
dfs(u,e[i],s);
return;
}
int main()
{
memset(h,-1,sizeof(h));
cin>>n>>str;
for(int i=2;i<=n;i++)
{
int a;
cin>>a;
add(a,i);
add(i,a);
}
dfs(0,1,"");
cout<<res<<endl;
return 0;
}
但是因为数据没顶满,所以 ACACAC on #1 #2 #3 #4 #8 #9 #10,35 ptsptspts
第二轮尝试 特殊数据 70pts
分析数据的特殊性质,fi=i−1f_i=i-1fi=i−1 等价于整棵树退化为链,问题转化为对于 iii,求前 iii 位字符串的合法子串数。
观察到 N≤5∗105N\leq 5*10^5N≤5∗105,单次查询大概率为 O(1)O(1)O(1) 或 O(logn)O(logn)O(logn) 。显然从前往后遍历,很像线性 dpdpdp 的逻辑,于是定义 dpidp_idpi 为以 iii 结尾的合法子串的数量,则所求的结果 resires_iresi 恰好为 dp1∼idp_{1\sim i}dp1∼i 的前缀和。并手动计算几组数据,看不同情况对于 dpidp_idpi 的贡献。
数据 111(独立合法括号):())()( dp=[0,1,0,0,1,0]dp=[0,1,0,0,1,0]dp=[0,1,0,0,1,0] res=[0,1,1,1,2,2]res=[0,1,1,1,2,2]res=[0,1,1,1,2,2]
发现对于一个独立存在的合法括号串,对 dpidp_idpi 的贡献为 111,这个很好找,只需要一个栈就可以。
数据 222(嵌套不相邻):(())(((())) dp=[0,0,1,1,0,0,0,0,1,1,1]dp=[0,0,1,1,0,0,0,0,1,1,1]dp=[0,0,1,1,0,0,0,0,1,1,1] res=[0,,0,1,2,2,2,2,2,3,4,5]res=[0,,0,1,2,2,2,2,2,3,4,5]res=[0,,0,1,2,2,2,2,2,3,4,5]
显然对于嵌套的括号,栈判断且贡献为 111 仍成立,因为嵌套合法括号串在固定最后一个字符后无法拆分
数据 333(相邻不嵌套):()())()()() dp=[0,1,0,2,0,0,1,0,2,0,3]dp=[0,1,0,2,0,0,1,0,2,0,3]dp=[0,1,0,2,0,0,1,0,2,0,3] res=[0,1,1,3,3,3,4,4,6,6,9]res=[0,1,1,3,3,3,4,4,6,6,9]res=[0,1,1,3,3,3,4,4,6,6,9]
发现这次有一个后括号产生了大于 111 的贡献,且第 iii 个的贡献为 dpi−2+1(i≥3)dp_{i-2}+1(i\geq 3)dpi−2+1(i≥3)
数据 444(嵌套且相邻):()(()))() dp[0,1,0,0,1,2,0,0,1]dp[0,1,0,0,1,2,0,0,1]dp[0,1,0,0,1,2,0,0,1] res=[0,1,1,1,2,4,4,4,5]res=[0,1,1,1,2,4,4,4,5]res=[0,1,1,1,2,4,4,4,5]
观察到此时上面的贡献计算公式不管用,但究其本质是一样的,即贡献为当前匹配的无相邻组合的合法括号串的前一位的贡献 +1+1+1。
以本组数据举例,根据上述定义为当前匹配的无相邻组合的合法括号串的前一位,计算 pre=[0,1,2,3,3,2,6,6]pre=[0,1,2,3,3,2,6,6]pre=[0,1,2,3,3,2,6,6] 。
定义 checki=Truecheck_i=Truechecki=True表示 iii 是否匹配,若 iii 匹配,与其匹配的字符是第 kik_iki 个,则得出递推式 prei={i−1checki=Falseprekichecki=True pre_i=\left\{ \begin{array}{rcl} i-1 & & {check_i=False}\\ pre_{k_i} & & {check_i=True}\\ \end{array} \right. prei={i−1prekichecki=Falsechecki=True
显然只要存栈的时候存的是编号,那么 kik_iki 就可以直接得到。
代码呼之欲出,但是记得在暴力的基础上加特判,保留暴力分。同时上面过不了大数据所以没有开的 long longlong\ longlong long也要开了
test2.cpp
#include<iostream>
#include<algorithm>
#include<cstring>
#include<stack>
using namespace std;
const int N=5e5+10;
int n;
int h[N],e[N<<1],ne[N<<1],idx;
int pre[N],dp[N];
long long ans[N];
long long res;
bool flag=1;
string str;
void add(int a,int b)
{
e[idx]=b;
ne[idx]=h[a];
h[a]=idx;
idx++;
}
bool check(string s,int a,int b)
{
int cnt=0;
a--;
b--;
for(int i=a;i<=b;i++)
{
if(s[i]=='(')
cnt++;
else
{
if(cnt)
cnt--;
else
return false;
}
}
return cnt==0;
}
int count(string s)
{
int cnt=0;
for(int len=2;len<=s.size();len++)
for(int i=1;i+len-1<=s.size();i++)
if(check(s,i,i+len-1))
cnt++;
return cnt;
}
void dfs(int fa,int u,string s)
{
s+=str[u-1];
res^=u*count(s);
for(int i=h[u];i!=-1;i=ne[i])
if(e[i]!=fa)
dfs(u,e[i],s);
return;
}
void DP()
{
stack<int> s;
for(int i=1;i<=n;i++)
{
pre[i]=i-1;
if(str[i-1]==')'&&!s.empty())
{
int t=s.top();
s.pop();
dp[i]=dp[pre[t]]+1;
}
else if(str[i-1]=='(')
s.push(i);
ans[i]=ans[i-1]+dp[i];
res^=i*ans[i];
}
return;
}
int main()
{
memset(h,-1,sizeof(h));
cin>>n>>str;
for(int i=2;i<=n;i++)
{
int a;
cin>>a;
if(a!=i-1)
flag=0;
add(a,i);
add(i,a);
}
if(!flag)
dfs(0,1,"");
else
DP();
cout<<res<<endl;
return 0;
}
结果就是 TLETLETLE on #15-#20,即10510^5105 以上的普通数据。
冲击满分 100pts
注意到刚刚的链上计算可以同样适用于树,于是将顺序遍历改为dfsdfsdfs,并且递归后恢复栈即可。
test3.cpp
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int N=5e5+10;
int n;
int h[N],e[N<<1],ne[N<<1],idx;
int pre[N],dp[N],s[N],top;
long long cnt[N],res;
string str;
void add(int a,int b)
{
e[idx]=b;
ne[idx]=h[a];
h[a]=idx;
idx++;
return;
}
void dfs(int u,int fa)
{
pre[u]=fa;
if(str[u-1]=='(')
{
s[++top]=u;
cnt[u]=cnt[fa]+dp[u];
for(int i=h[u];i!=-1;i=ne[i])
{
int j=e[i];
if(j!=fa)
dfs(j,u);
}
top--;
}
else if(top>0&&str[u-1]==')')
{
int t=s[top];
top--;
dp[u]=dp[pre[t]]+1;
cnt[u]=cnt[fa]+dp[u];
for(int i=h[u];i!=-1;i=ne[i])
{
int j=e[i];
if(j!=fa)
dfs(j,u);
}
s[++top]=t;
}
else
{
cnt[u]=cnt[fa]+dp[u];
for(int i=h[u];i!=-1;i=ne[i])
{
int j=e[i];
if(j!=fa)
dfs(j,u);
}
}
res^=u*cnt[u];
return;
}
int main()
{
memset(h,-1,sizeof(h));
cin>>n>>str;
for(int i=2;i<=n;i++)
{
int a;
cin>>a;
add(a,i);
add(i,a);
}
dfs(1,0);
cout<<res;
return 0;
}
愉快 ACACAC

















 132
132



 到【灌水乐园】发言
到【灌水乐园】发言








