



 本文深入探讨了Bagging方法的思路,包括其通过自助法生成训练数据集和使用多个基本分类器进行投票的机制。重点介绍了RandomForest算法,它是Bagging与CART决策树的结合,具有速度快、抗过拟合、处理异常值和缺失数据的优势。同时,讨论了RandomForest在分类任务中的高精度和在回归问题上的局限。
本文深入探讨了Bagging方法的思路,包括其通过自助法生成训练数据集和使用多个基本分类器进行投票的机制。重点介绍了RandomForest算法,它是Bagging与CART决策树的结合,具有速度快、抗过拟合、处理异常值和缺失数据的优势。同时,讨论了RandomForest在分类任务中的高精度和在回归问题上的局限。
1.Bagging方法思路
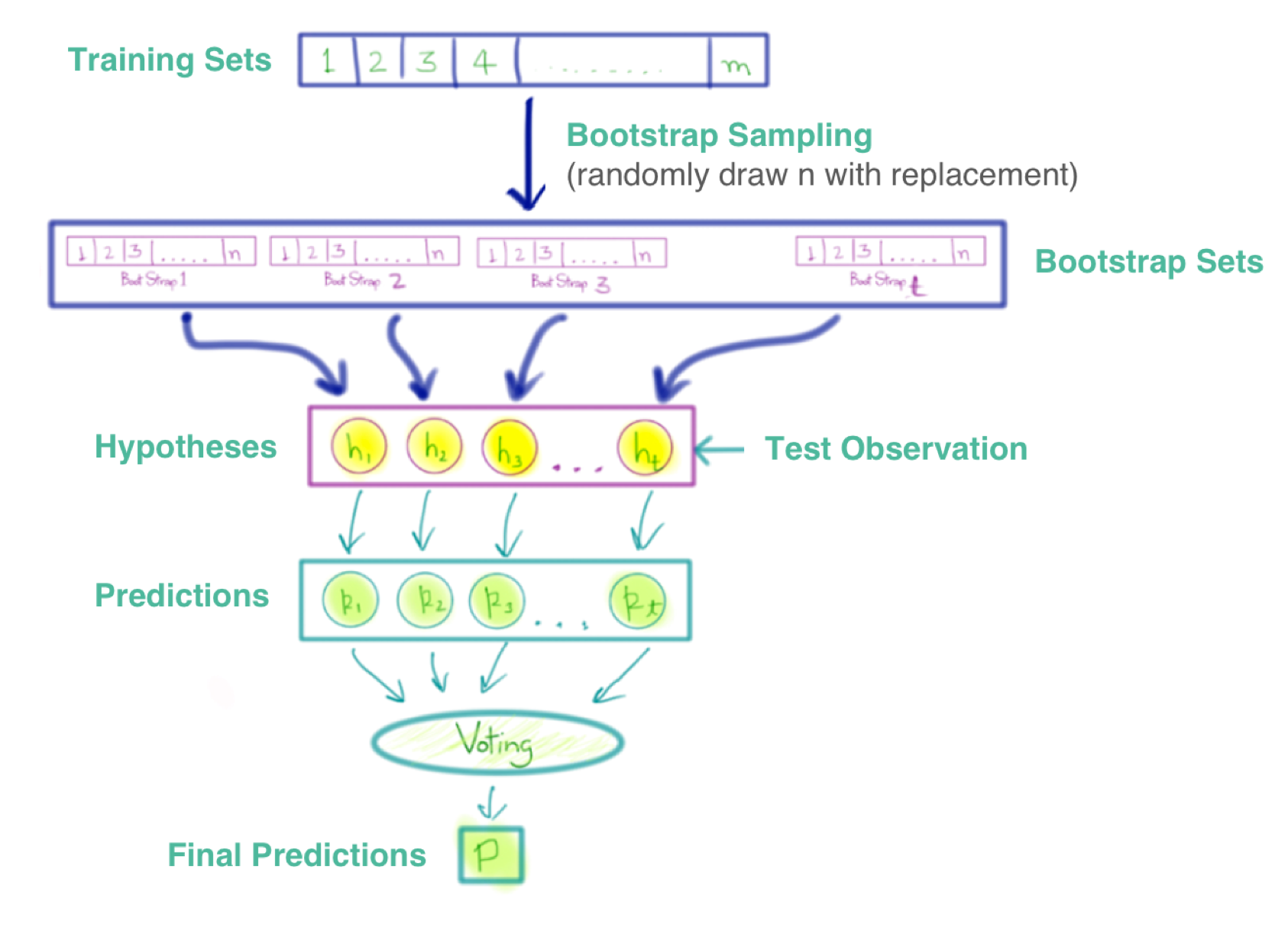
Bagging独立的、并行的生成多个基本分类器,然后通过投票方式决定分类的类别
Bagging使用了自助法确定每个基本分类器的训练数据集,初始样本集中63.2%的数据会被采样到
从Training Sets中每次取1个,放回,再取1个,放回,重复直到取到n个组成Boot Strap1
同理生成 Boot Strap2、Boot Strap3、……、Boot Strap t,组成Bootstrap Sets,Bootstrap Sets中的数据占Training Sets的63.2%
然后由这些Boot Strap生成不同的基本分类器h1、h2、……、ht
使用这些基本分类器对剩余36.8%的数据预测,然后投票决定分类结果
Bagging方法常用的算法是Random Forest
2.Random Forest算法
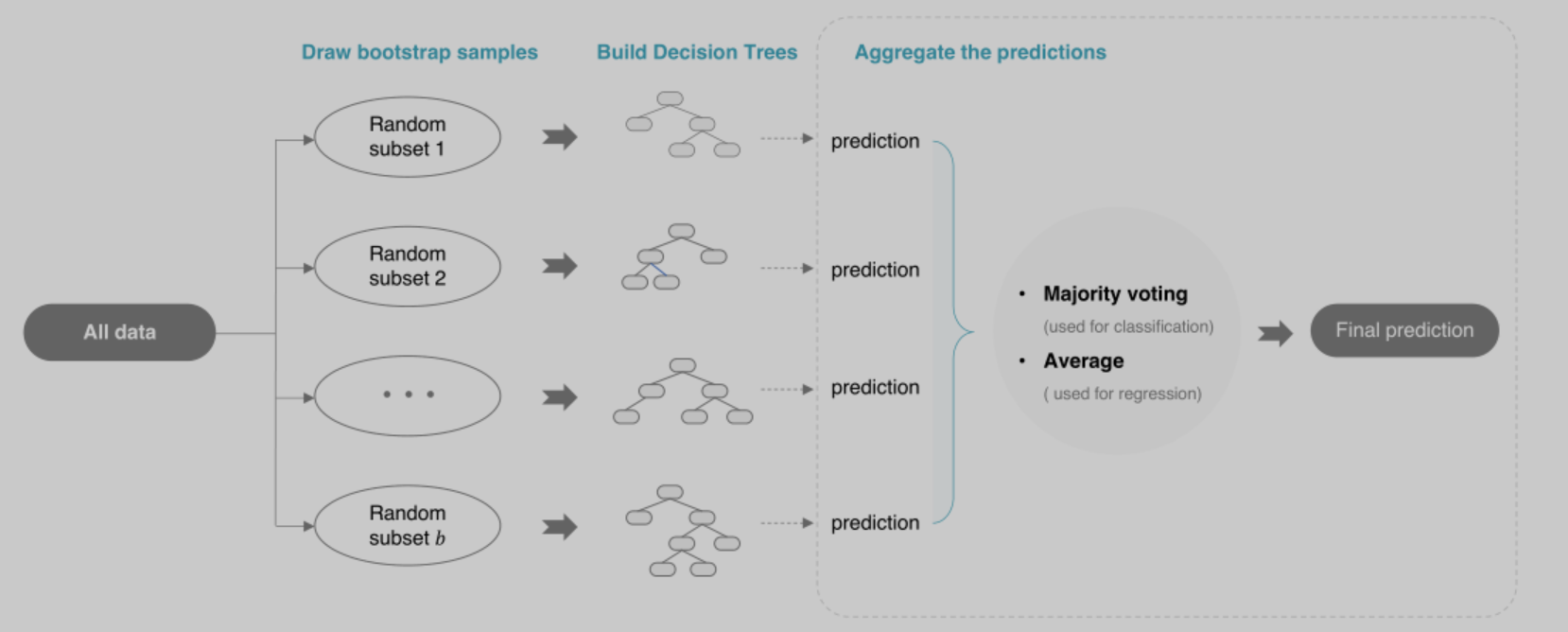
随机森林 = Bagging + 完全生长的CART决策树
算法思想
1)使用自助法进行采样,生成n个训练集
2)利用n个训练集,训练n个决策树,决策树不进行剪枝
- 从d个属性中随机选择k个属性
- 从k个属性里选出最优特征,生成二叉树
参数k控制了随机性的引入程度: 若令k=d,则决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分;一般情况下,推荐值$k=log_2d$
3)n个决策树分别进行预测,然后投票决定最终结果
3.Random Forest的优点
1)RF很少过拟合
2)RF中的决策树是平行生成的,速度快
3)RF对异常值不敏感,能处理缺失数据,并且不会丢失精度
4)RF在分类问题有很高的精度
4.Random Forest的缺点
1)集成大量的决策树可以提高RF的性能,但是会使算法变慢
2)RF在回归问题表现不好
它并不能给出一个连续的输出。当进行回归时,RF不能够做出超越训练集数据范围的预测,这可能导致在某些特定噪声的数据进行建模时出现过度拟合。(PS:随机森林已经被证明在某些噪音较大的分类或者回归问题上会过拟合)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









