




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS
Elasticsearch ES (本章节)
前面我们介绍模板的时候有提到过我们会在ES生成大量的索引,但是我们不能光生成索引,不考虑释放的问题,所以我们 就引入今天的概念:索引生命周期管理 (Index Lifecycle Management, ILM)。
Elasticsearch 的 索引生命周期管理 (Index Lifecycle Management, ILM) 是自动化管理索引生命周期的核心功能,尤其适用于时序数据(如日志、指标)。它通过预定义的策略(Policy)自动控制索引从创建到删除的完整过程,大幅降低运维成本。下面我们用一个监控的案例来解释这个问题。
需求
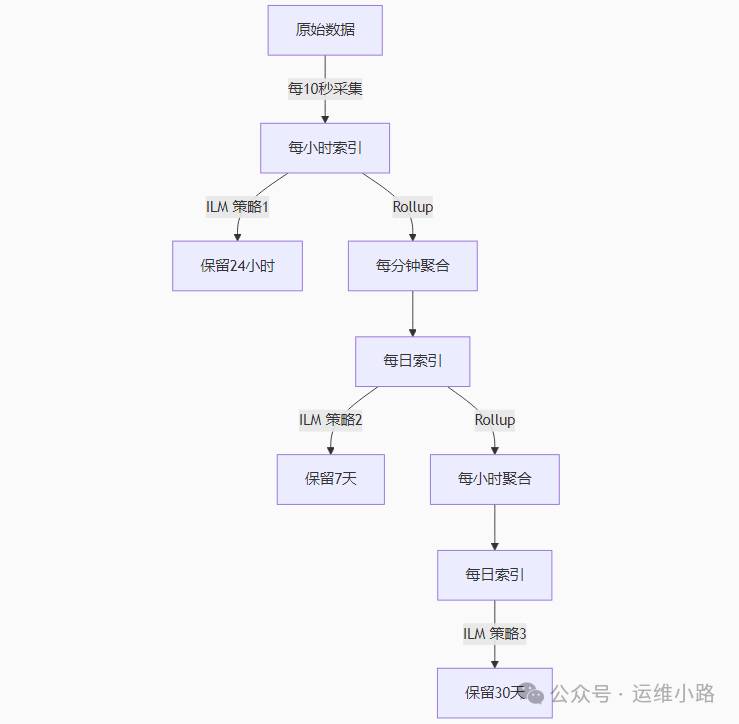
监控数据,最小单位是每10秒采集一次数据,每小时生成一个索引,只能查最近24小时的数据。并且一次最多只能查一个小时的数据。
然后把前面每10秒的数据合并每分钟数据,每天一个索引,可以查询最近七天的数据,一次查询只能查询最近一天的数据。
然后再把前面每分钟的数据合并成每小时的数据,每天一个索引,然后最多可以查一个月的数据,一次最多多查七天数据。
整体架构设计
技术实现
1.原始数据策略(10秒粒度)
索引模式: raw-metrics-<yyyy.MM.dd-HH>
保留时间: 24小时
查询限制: 最多查询1小时数据
# 创建 ILM 策略
PUT _ilm/policy/raw_metrics_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "1h"
},
"set_priority": {
"priority": 100
}
}
},
"delete": {
"min_age": "24h",
"actions": {
"delete": {}
}
}
}
}
}
# 创建索引模板
PUT _index_template/raw_metrics_template
{
"index_patterns": ["raw-metrics-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "raw_metrics_policy"
},
"aliases": {
"raw_metrics": {}
}
}
}
# 创建初始索引
PUT raw-metrics-2024.05.01-00
{
"aliases": {
"raw_metrics_write": {
"is_write_index": true
}
}
}
2. 分钟级聚合策略(1分钟粒度)
索引模式: minute-metrics-<yyyy.MM.dd>
保留时间: 7天
查询限制: 最多查询1天数据
# 创建 Rollup 任务(每分钟聚合)
PUT _rollup/job/minute_metrics_rollup
{
"index_pattern": "raw-metrics-*",
"rollup_index": "minute-metrics-<{now/d}>",
"cron": "0 */5 * * * ?", // 每5分钟运行一次
"groups": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1m"
}
},
"metrics": [
{"field": "cpu", "metrics": ["avg", "max", "min"]},
{"field": "memory", "metrics": ["avg"]}
]
}
# 创建 ILM 策略
PUT _ilm/policy/minute_metrics_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 50
}
}
},
"delete": {
"min_age": "7d",
"actions": {
"delete": {}
}
}
}
}
}
# 创建索引模板
PUT _index_template/minute_metrics_template
{
"index_patterns": ["minute-metrics-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "minute_metrics_policy"
},
"aliases": {
"minute_metrics": {}
}
}
}
3. 小时级聚合策略(1小时粒度)
索引模式: hour-metrics-<yyyy.MM.dd>
保留时间: 30天
查询限制: 最多查询7天数据
# 创建 Rollup 任务(每小时聚合)
PUT _rollup/job/hour_metrics_rollup
{
"index_pattern": "minute-metrics-*",
"rollup_index": "hour-metrics-<{now/d}>",
"cron": "0 0 */1 * * ?", // 每小时运行一次
"groups": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1h"
}
},
"metrics": [
{"field": "cpu.avg", "metrics": ["avg"]},
{"field": "cpu.max", "metrics": ["max"]}
]
}
# 创建 ILM 策略
PUT _ilm/policy/hour_metrics_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 25
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"force_merge": {
"max_num_segments": 1
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
# 创建索引模板
PUT _index_template/hour_metrics_template
{
"index_patterns": ["hour-metrics-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "hour_metrics_policy"
},
"aliases": {
"hour_metrics": {}
}
}
}
当然今天这个只是给大家一个讲解的基本的概念,由于这个实际操作需要比较多的时间,所以这里并没有实际案例,下个小节我们讲通过模拟实际数据来实现今天这个小节的逻辑。
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 4117
4117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









