




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
我们上一章介绍了Docker基本情况,目前在规模较大的容器集群基本都是Kubernetes,但是Kubernetes涉及的东西和概念确实是太多了,而且随着版本迭代功能在还增加,笔者有些功能也确实没用过,所以只能按照我自己的理解来讲解。
前面我们介绍的Kubernetes的监控,虽然没有讲解告警,但是告警产生以后,我们还是需要去核查异常情况,有没有什么方式自动修复我们的问题,他就是我们要讲的Node Problem Detector(NPD)。
Node Problem Detector(NPD)简介
Node Problem Detector(NPD)是Kubernetes社区维护的开源工具,旨在检测节点级别的异常状态(如硬件故障、内核问题、容器运行时错误等),并将问题上报至Kubernetes事件系统或Node Condition,为集群自愈提供依据。其核心功能包括:
问题检测:通过监控系统日志(如journald)、内核日志或自定义插件,识别节点异常。
事件上报:将检测到的问题转化为Kubernetes的NodeCondition或Event,供集群管理员或自动化系统处理。
与自愈系统集成:结合Prometheus、Alertmanager等工具触发告警,或通过自动化脚本重启服务、修复配置。
核心应用场景
-
硬件故障:如CPU/内存/磁盘异常。
-
内核问题:如死锁、文件系统损坏。
-
容器运行时异常:Docker假死、CRI-O崩溃。
-
基础设施服务故障:NTP服务失效、网络插件异常(如Calico/Flannel)。
NPD的安装与配置
helm repo add deliveryhero https://charts.deliveryhero.io/
helm install --generate-name deliveryhero/node-problem-detector检查Pod状态

模拟内核错误并观察事件
# 注入测试日志
sh -c "echo 'kernel: BUG: unable to handle kernel NULL pointer dereference at TESTING' >> /dev/kmsg"
# 查看节点事件
kubectl describe node node01验证自我修复
基础镜像,是因为我们使用Cronjob来检查集群的状态,然后里面必须要包含我们需要使用的基础工具。
FROM 192.168.31.43:5000/centos:7
# 移除旧的 yum 源配置
RUN rm -rf /etc/yum.repos.d/*.repo
# 添加 CentOS 基础源
ADD CentOS-Base.repo /etc/yum.repos.d/
RUN yum clean all
# 添加 EPEL 源
RUN yum install -y epel-release
# 安装 jq和ssh客户端
RUN yum -y install jq
RUN yum -y install openssh-clients
# 添加 kubectl 到 /usr/bin 目录
ADD kubectl /usr/bin/创建一个CronJob,定义检查集群的状态,这里还是复用上面的事件来判断集群异常。
apiVersion: batch/v1
kind: CronJob
metadata:
name: node-auto-reboot
namespace: kube-system
spec:
schedule: "*/5 * * * *" # 每5分钟检查一次
concurrencyPolicy: Forbid # 禁止并发执行
jobTemplate:
spec:
template:
spec:
serviceAccountName: node-repair-sa # 需绑定权限
containers:
- name: repair-script
image: 192.168.31.43:5000/kubectl:latest
command: ["/bin/sh", "-c"]
args:
- |
# 配置SSH
mkdir -p /root/.ssh
cp /etc/ssh-secret/* /root/.ssh/
chmod 600 /root/.ssh/id_ed25519
# 主修复脚本
NODES=$(kubectl get events --field-selector reason=KernelOops -A -o json \
| jq -r '.items[] | select(.lastTimestamp >= "'$(date -d '10 minutes ago' -u +"%Y-%m-%dT%H:%M:%SZ")'") | .source.host' \
| sort -u)
Service=$(kubectl get node node01 -o yaml |grep public |awk '{print $2}')
for NODE in $NODES; do
echo "处理节点: $NODE"
kubectl cordon $NODE
kubectl drain $NODE --force --ignore-daemonsets --delete-emptydir-data
ssh -o StrictHostKeyChecking=no root@$Service "reboot"
sleep 60 # 等待重启
kubectl uncordon $NODE
done
volumeMounts:
- name: ssh-secret
mountPath: "/etc/ssh-secret"
volumes:
- name: ssh-secret
secret:
secretName: npd-ssh-key
restartPolicy: OnFailure# ServiceAccount 和权限绑定
apiVersion: v1
kind: ServiceAccount
metadata:
name: node-repair-sa
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: node-repair-role
rules:
- apiGroups: [""]
resources: ["nodes", "events", "pods"]
verbs: ["get", "list", "watch", "update", "patch", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: node-repair-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: node-repair-role
subjects:
- kind: ServiceAccount
name: node-repair-sa
namespace: kube-system
这里还需要准备一个公钥和私钥,为的目的是可以免密登录到各个节点。每个服务器都需要放置公钥,更详细配置方式可参考:Linux日常运维-SSHD(一)
# 生成密钥(类型 ed25519,更安全)
ssh-keygen -t ed25519 -f npd-ssh-key -N ""复制公钥复制每个服务器的/root/.ssh/authorized_keys文件。
#把私钥变成变成secret
kubectl create secret generic npd-ssh-key \
--namespace=kube-system \
--from-file=id_ed25519=./npd-ssh-key \
--from-file=id_ed25519.pub=./npd-ssh-key.pub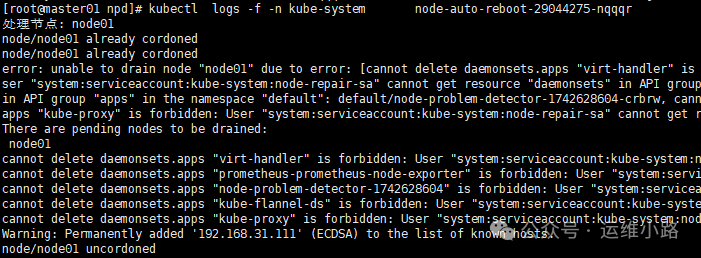
从日志中我们可以看出来先隔离节点,然后驱逐Pod,然后重启,最后再取消隔离。

运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









