







1.下载ollma
Ollama 是一个开源的大型语言模型(LLM)本地化部署框架,旨在简化用户在本地运行和管理大模型的流程。
https://ollama.com/download
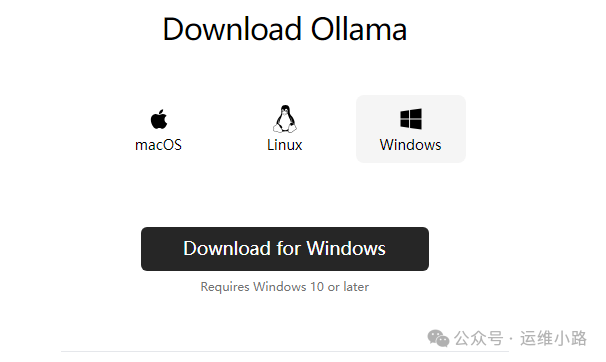
2.安装ollma
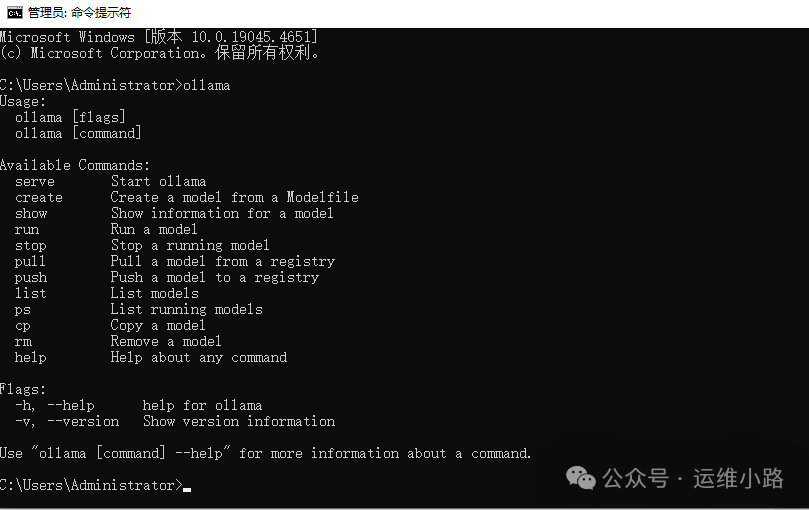
这里安装就和普通软件安装一样,直接双击exe文件即可,安装完成以后打开命令提示符如下图说明安装成功。
3.下载&运行模型
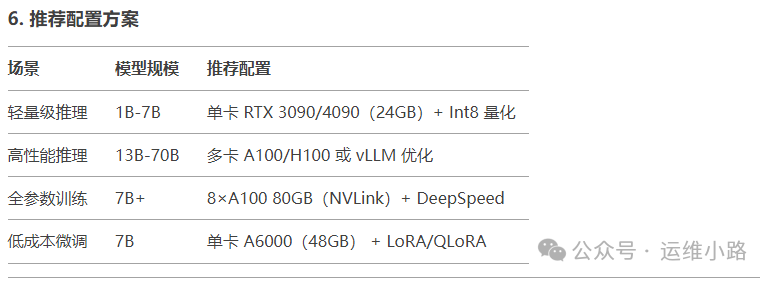
这里有很多模型可选,不同的模型对配置的要求是不一样的,纯cpu或者只是体验功能可以选择1.5b,下图是DeepSeek模型的推荐配置。
本次演示的服务器:CPU:I5 8400;内存:32G,显卡:两个显示器,一个接主板集成显卡,一个接独立显卡(亮机卡)。
https://ollama.com/library/deepseek-r1
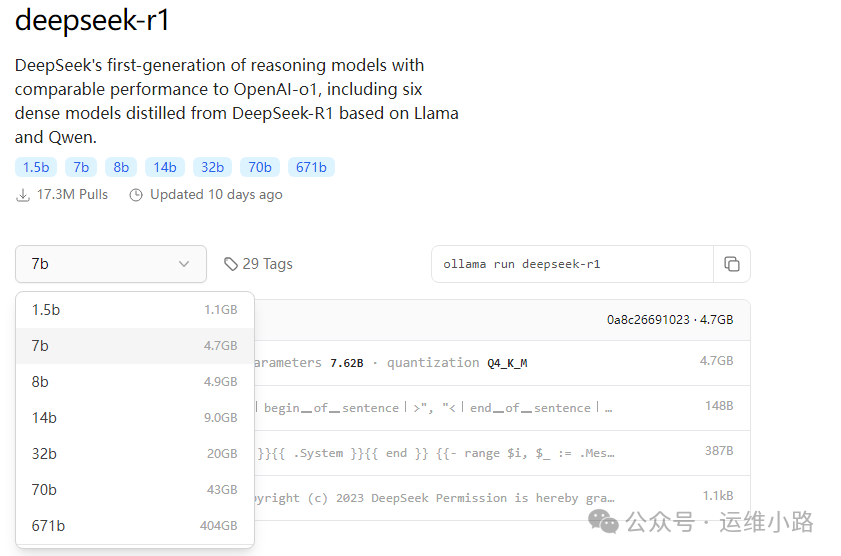

ollama run deepseek-r1:1.5b
执行这个命令以后他会开始下载模型,开始执行很快,后面就会变得很慢,下载完成就会出现下图这样(我这个由于是关掉重新运行的,所以看不到下载界面)。
4.提问
由于没有其他接口来调用这个api,所以这里只能用控制台访问。
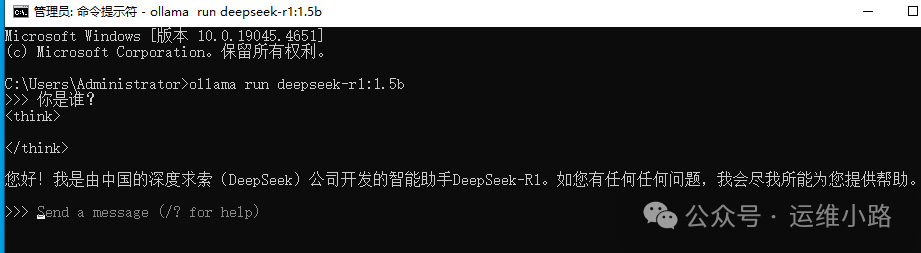
5.接入第三方工具
https://cherry-ai.com/#下载并安装客户端
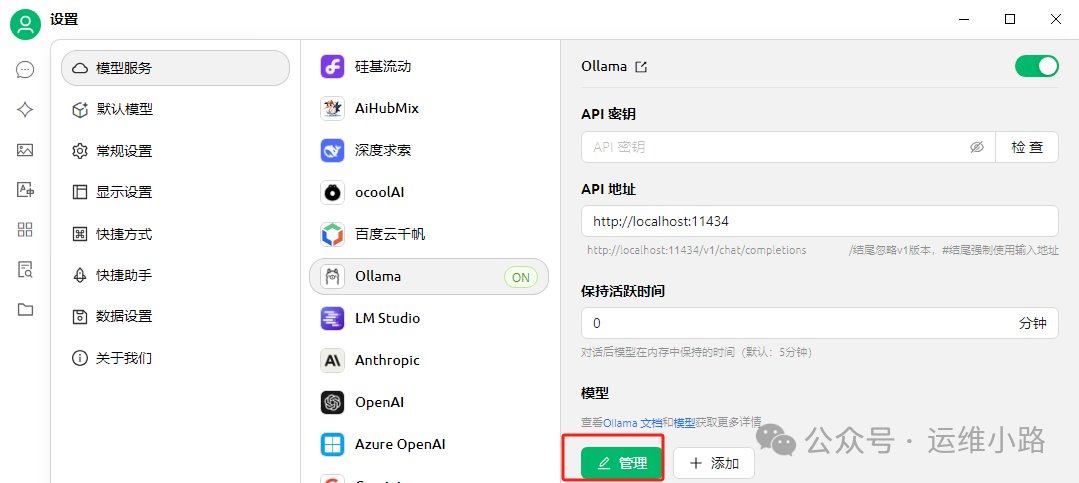
参考下图配置即可并选择管理,然后点击添加你本地的模型(他会自动识别你本地安装过的模型)。
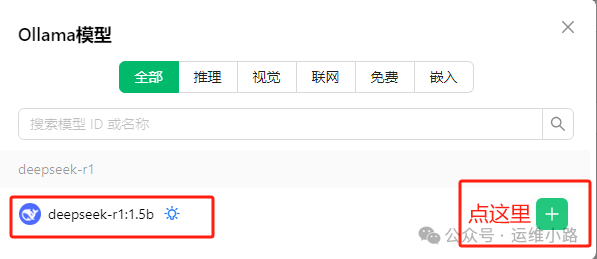
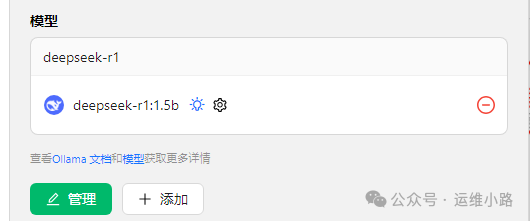
添加成功以后就可以看到本地的模型版本。
6.开始对话
回到工具左上角的对话,就可以进行对话,这里我们可以选择一个比较复杂的逻辑。
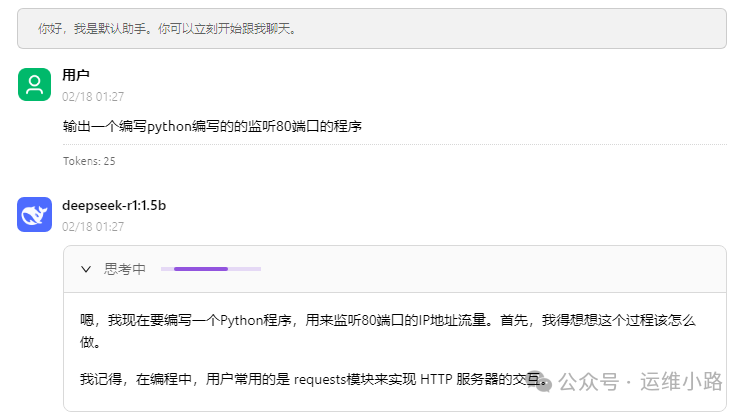
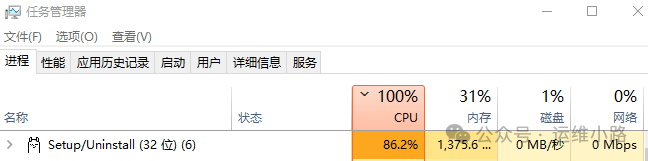
7.资源监控
从这里可以看到在回答我们问题的时候,cpu占用很高,但是内存不是很高。当然我这个选择的低配模型肯定没有高配模型回答的好,但是体验入门是没问题的。
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









