




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ(本章节)
上个小节我们通过生产者代码,向RabbitMQ的交换机发送消息,本小节我们就通过消费者代码去读取队列里面数据,以下代码基于DeepSeek生成。
我们可以和生产者的RabbitMQ配置对比下,看下有什么差距。
import pika
import json
import logging
import signal
import sys
from datetime import datetime
import os
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler(sys.stdout)]
)
logger = logging.getLogger("mq_consumer")
# RabbitMQ 配置
RABBITMQ_HOST = 'localhost'
RABBITMQ_PORT = 5672
RABBITMQ_USER = 'guest'
RABBITMQ_PASS = 'guest'
RABBITMQ_VHOST = '/'
QUEUE_NAME = 'sensor_queue' # 要消费的队列名称
# 文件存储配置
OUTPUT_DIR = 'mq_data' # 输出目录
FILE_PREFIX = 'sensor_data' # 文件前缀
MAX_FILE_SIZE = 10 * 1024 * 1024 # 10MB 最大文件大小
MAX_MESSAGES_PER_FILE = 1000 # 每个文件最大消息数
# 全局变量
running = True
current_file = None
message_count = 0
file_message_count = 0
file_size = 0
def signal_handler(sig, frame):
"""处理Ctrl+C信号,优雅地停止程序"""
global running
logger.info("Received shutdown signal. Stopping consumer...")
running = False
def setup_output_dir():
"""创建输出目录"""
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR)
logger.info(f"Created output directory: {OUTPUT_DIR}")
else:
logger.info(f"Using existing output directory: {OUTPUT_DIR}")
def get_next_filename():
"""生成下一个文件名"""
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
return os.path.join(OUTPUT_DIR, f"{FILE_PREFIX}_{timestamp}.json")
def open_new_file():
"""打开新文件并写入起始标记"""
global current_file, file_message_count, file_size
filename = get_next_filename()
try:
current_file = open(filename, 'a', encoding='utf-8')
current_file.write('[\n') # 开始JSON数组
file_message_count = 0
file_size = 2 # 初始大小([和\n)
logger.info(f"Opened new output file: {filename}")
return True
except Exception as e:
logger.error(f"Failed to open file {filename}: {str(e)}")
return False
def close_current_file():
"""关闭当前文件并写入结束标记"""
global current_file
if current_file and not current_file.closed:
try:
# 移除最后一个逗号(如果有)
if file_message_count > 0:
current_file.seek(current_file.tell() - 2)
current_file.truncate()
current_file.write('\n')
current_file.write(']') # 结束JSON数组
current_file.close()
logger.info(f"Closed output file: {current_file.name}")
except Exception as e:
logger.error(f"Error closing file: {str(e)}")
finally:
current_file = None
def write_message_to_file(message):
"""将消息写入文件"""
global current_file, file_message_count, file_size
# 如果文件未打开或达到限制,创建新文件
if current_file is None or current_file.closed:
if not open_new_file():
return False
# 检查是否需要创建新文件
if (file_message_count >= MAX_MESSAGES_PER_FILE or
file_size >= MAX_FILE_SIZE):
close_current_file()
if not open_new_file():
return False
# 格式化消息
try:
message_json = json.dumps(message, ensure_ascii=False)
# 添加逗号分隔符(除了第一条消息)
if file_message_count > 0:
message_json = ',\n' + message_json
else:
message_json = '\n' + message_json
# 写入文件
current_file.write(message_json)
current_file.flush() # 确保立即写入磁盘
# 更新计数
file_message_count += 1
file_size += len(message_json.encode('utf-8'))
return True
except Exception as e:
logger.error(f"Error writing message to file: {str(e)}")
return False
def setup_rabbitmq_connection():
"""建立RabbitMQ连接"""
try:
credentials = pika.PlainCredentials(RABBITMQ_USER, RABBITMQ_PASS)
parameters = pika.ConnectionParameters(
host=RABBITMQ_HOST,
port=RABBITMQ_PORT,
virtual_host=RABBITMQ_VHOST,
credentials=credentials,
heartbeat=600,
blocked_connection_timeout=300
)
connection = pika.BlockingConnection(parameters)
channel = connection.channel()
# 声明队列(确保存在)
channel.queue_declare(
queue=QUEUE_NAME,
durable=True,
passive=True # 被动检查队列是否存在
)
# 设置QoS(公平分发)
channel.basic_qos(prefetch_count=1)
logger.info(f"Connected to RabbitMQ. Consuming from queue: {QUEUE_NAME}")
return connection, channel
except Exception as e:
logger.error(f"Failed to connect to RabbitMQ: {str(e)}")
return None, None
def message_callback(ch, method, properties, body):
"""消息处理回调函数"""
global message_count
try:
# 解析消息
message = json.loads(body)
message_count += 1
# 添加接收元数据
message['_meta'] = {
'received_at': datetime.utcnow().isoformat() + "Z",
'delivery_tag': method.delivery_tag,
'exchange': method.exchange,
'routing_key': method.routing_key
}
# 写入文件
if write_message_to_file(message):
# 确认消息
ch.basic_ack(delivery_tag=method.delivery_tag)
# 每10条消息打印一次摘要
if message_count % 10 == 0:
logger.info(f"Processed {message_count} messages | "
f"Last sensor: {message.get('sensor_id', 'N/A')} | "
f"File: {current_file.name if current_file else 'N/A'}")
else:
# 写入失败,拒绝消息(重新入队)
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=True)
logger.error(f"Message processing failed. Requeued: {method.delivery_tag}")
except json.JSONDecodeError:
logger.error(f"Invalid JSON message: {body[:100]}...")
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=False)
except Exception as e:
logger.error(f"Error processing message: {str(e)}")
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=False)
def main():
"""主函数,消费消息并保存到文件"""
global running
# 注册信号处理器
signal.signal(signal.SIGINT, signal_handler)
signal.signal(signal.SIGTERM, signal_handler)
# 设置输出目录
setup_output_dir()
# 建立RabbitMQ连接
connection, channel = setup_rabbitmq_connection()
if not channel:
logger.error("Exiting due to connection failure")
return
try:
# 开始消费消息
channel.basic_consume(
queue=QUEUE_NAME,
on_message_callback=message_callback,
auto_ack=False # 手动确认消息
)
logger.info("Starting message consumer")
logger.info(f"Saving messages to directory: {OUTPUT_DIR}")
logger.info("Press Ctrl+C to stop")
# 开始消费循环
while running:
try:
# 处理事件
connection.process_data_events(time_limit=1) # 1秒超时
except pika.exceptions.ConnectionClosedByBroker:
logger.warning("Connection closed by broker. Reconnecting...")
connection, channel = setup_rabbitmq_connection()
if channel:
channel.basic_consume(
queue=QUEUE_NAME,
on_message_callback=message_callback,
auto_ack=False
)
else:
time.sleep(5)
except Exception as e:
logger.error(f"Error in consumer loop: {str(e)}")
time.sleep(1)
except Exception as e:
logger.error(f"Critical error: {str(e)}")
finally:
# 清理资源
close_current_file() # 确保文件正确关闭
if connection and connection.is_open:
try:
connection.close()
logger.info("RabbitMQ connection closed")
except Exception:
pass
logger.info(f"Consumer stopped. Total messages processed: {message_count}")
if __name__ == "__main__":
main()
#消费者日志
2025-06-18 23:52:35,264 - INFO - Created channel=1
2025-06-18 23:52:35,266 - INFO - Connected to RabbitMQ. Consuming from queue: test01
2025-06-18 23:52:35,267 - INFO - Starting message consumer
2025-06-18 23:52:35,267 - INFO - Saving messages to directory: mq_data
2025-06-18 23:52:35,267 - INFO - Press Ctrl+C to stop
2025-06-18 23:52:35,267 - INFO - Opened new output file: mq_data/sensor_data_20250618_235235.json
从下图我们看到消息减少了一半,并且还可以看到消费速度。
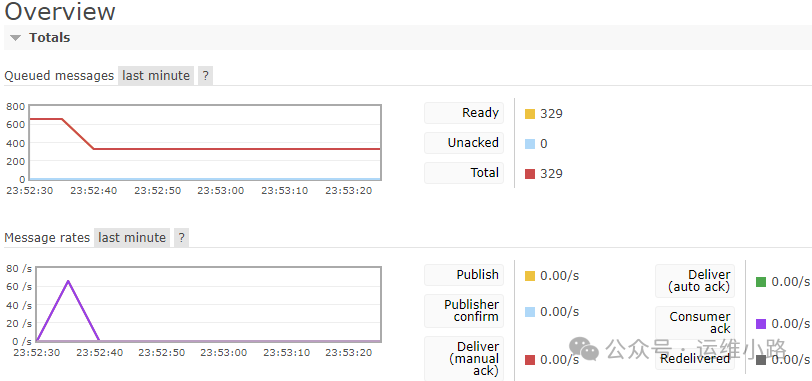
从队列来看,我们我们只配置了一个队列,所以另外一个队列的数据还在。

运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









