







Chapter 4 Dynamic Programming
目录
4.1 Policy Evaluation (Prediction)
4.5 Asynchronous Dynamic Programming
4.6 Generalized Policy Iteration
4.7 Effiffifficiency of Dynamic Programming
仿真实现部分待完善
前言:
The term dynamic programming (DP) refers to a collection of algorithms that can be
used to compute optimal policies given a perfect model of the environment as a Markov
decision process (MDP).
Classical DP algorithms are of limited utility in reinforcement
learning both because of their assumption of a perfect model and because of their great
computational expense, but they are still important theoretically.
DP provides an essential
foundation for the understanding of the methods presented in the rest of this book.
DP算法是其他强化学习的基础,其他算法实际上是希望用更少的计算量和对模型更少的假设,来达到和DP一样的效果
We usually assume that the environment is a fifinite MDP. That is, we assume that its
state, action, and reward sets, S, A, and R
, are fifinite, and that its dynamics are given by a
set of probabilities
p
(
s‘
, r
|
s, a
)
The key idea of DP, and of reinforcement learning generally, is the use of value functions
to organize and structure the search for good policies. In this chapter we show how DP
can be used to compute the value functions defifined in Chapter 3. As discussed there
一旦找到满足Bellman最优性方程的最优值函数v*或q*,就很容易得到最优策略:
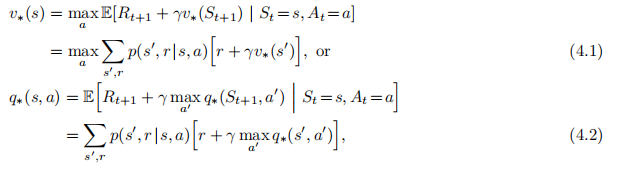
DP算法是通过将这些Bellman方程转化为赋值,即转化为改进期望值函数逼近的更新规则而得到的。
4.1 Policy Evaluation (Prediction)
First we consider how to compute the state-value function
vΠ
for an arbitrary policy
π
.
This is called
policy evaluation
in the DP literature. We also refer to it as the
prediction
problem
.
策略估计:计算任意一个策略下,这个策略下的状态值
状态值具有唯一性和确定性
迭代策略估计:
我们用迭代的方法,用贝尔曼方程作为更新规则,逐次去逼近vΠ
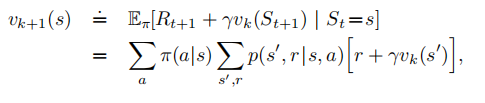
for all
s ∈
S
. Clearly,
v
k
=
vΠ
is a fifixed point for this update rule because the Bellman
equation for
vΠ
assures us of equality in this case. Indeed, the sequence
{
v
k
}
can be
shown in general to converge to
vΠ
as
k趋于无穷大,
under the same conditions that guarantee
the existence of
vΠ</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4678
4678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









