



 这篇博客介绍了在MIDL2018会议上提出的AttentionU-Net模型,该模型用于腹部CT图像的胰腺分割任务。通过结合soft-attention机制,网络能够抑制不相关信息,聚焦于关键区域。AttentionGate模块利用1x1x1卷积调整不同尺度特征图,并通过三线性插值实现上采样,确保尺寸匹配。模型在正向和反向传播中过滤神经元激活,优化背景区域的影响。该方法提高了分割精度,尤其适用于医疗图像分析。
这篇博客介绍了在MIDL2018会议上提出的AttentionU-Net模型,该模型用于腹部CT图像的胰腺分割任务。通过结合soft-attention机制,网络能够抑制不相关信息,聚焦于关键区域。AttentionGate模块利用1x1x1卷积调整不同尺度特征图,并通过三线性插值实现上采样,确保尺寸匹配。模型在正向和反向传播中过滤神经元激活,优化背景区域的影响。该方法提高了分割精度,尤其适用于医疗图像分析。
Attention U-Net: Learning Where to Look for the Pancreas
MIDL 2018
腹部CT胰腺分割
数据集:TCIA Pancreas CT-82和multi-class abdominal CT-150
原文链接
pytorch代码(包含2D/3D版本)
将soft-attention合并到标准的U-Net分割网络中的concatenation操作之前,抑制输入图像中的不相关的区域,突出特定局部区域的显著特征。
网络结构:
Attention Gate模块接收两部分的输入xl和g。因为g提取粗粒度信息,包含上下文信息,g里面的信息就是注意力该学习的方向,因此将g作为门控信号,将g里面的信息叠加到xl,学习attention coefficients,将attention coefficients与xl相乘,最后将得到的输出与上采样后的特征图拼接。
(疑问:为什么不需要裁剪可以之间串联?????需要看代码中unet是怎么设置的,可能卷积过程中进行了padding)
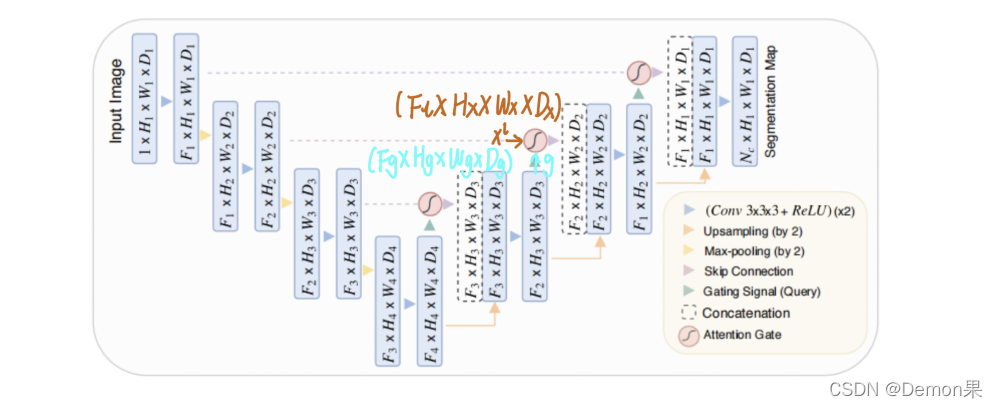
Attention Gate原理图:
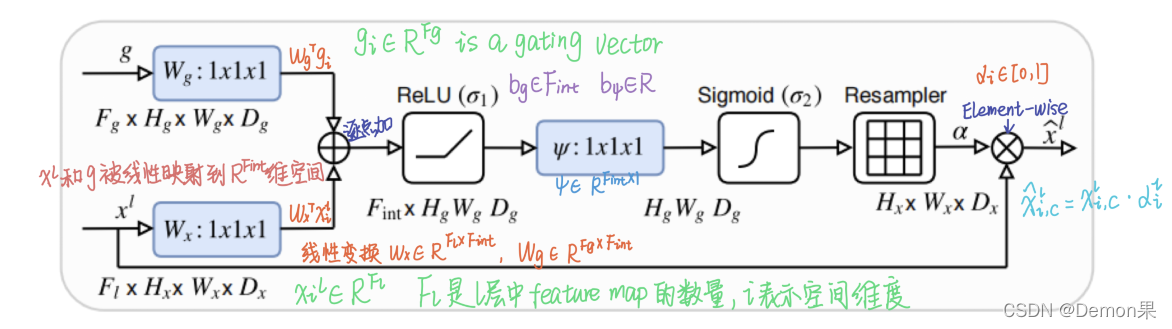
由于g和xl的尺寸不一样,需要先对xl进行下采样(也可对g进行上采样),否则无法完成逐点加操作。线性变换是使用1×1×1的channel-wise卷积实现的。Resampler通过三线性插值实现。在此处上采样,使
α
\alpha
α与xl的维度相同。
Attention Gate的公式如下,
b
g
b_g
bg和
b
b
b
ψ
\psi
ψ是偏置项。:
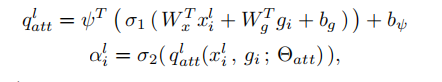
其中
σ
\sigma
σ1表示Relu函数,
σ
\sigma
σ2是sigmoid激活函数,因sigmoid函数可以使训练更好的收敛。
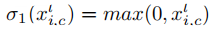
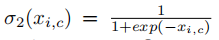
Attention Gate的最终输出是输入特征图和attention系数相乘:再将得到的最终输出与解码器上采样之后的feature map串联。
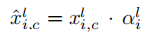
AGs在正向传递和反向传递中filter the neuron activations,来自背景区域的梯度在向后传递时向下加权。l-1层中卷积参数的更新规则:
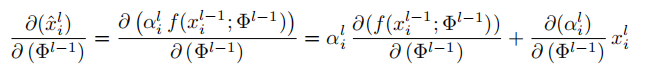
Reference:
https://blog.youkuaiyun.com/guzhao9901/article/details/119612308
https://zhuanlan.zhihu.com/p/114471013

















 79
79

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









