




Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);
在信息检索(如搜索引擎)、自然语言处理和检测分类中经常会使用这些参数,介于语言翻译上的原因理解难免出现误差,下面介绍下自己对他们的理解。
首先来个定义:
Precision:被检测出来的信息当中 正确的或者相关的(也就是你想要的)信息中所占的比例;
Recall:所有正确的信息或者相关的信息(wanted)被检测出来的比例。
F1-Meature后面定义。
查了资料都习惯使用四格图来解释,来个易懂的四格图:
| 正确的、相关的(wanted) | 不正确的、不相关的 | ||||
|
|
| |||
|
|
|
表格中的翻译比较重要,可以帮助理解。
true positives (纳真) false positives(纳伪)
false negatives(去真)true negatives (去伪)
其中false positives(纳伪)也通常称作误报,false negatives也通常称作漏报!
Precision = tp/(tp + fp);
Recall = tp / (tp + fn).
同样还有另外两个定义

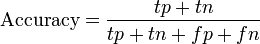
然而在实际当中我们当然希望检索的结果P越高越好,R也越高越好;事实上这两者在某些情况下是矛盾的。比如,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。因此在不同的场合中需要自己判断希望P比较高还是R比较高。如果是做实验,可以绘制Precision-Recall曲线来帮助分析。
F-Measure是Precision和Recall加权调和平均:
当参数a=1时,就是最常见的F1了:
很容易理解,F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









