







说在前面
最近在研究关系抽取任务,接下来会对抽取结果进行数据分析,需要使用到这3个评估指标,在此记录他们的计算方法,有没有代码等问题。
精确度 (Precision, P)、召回率 (Recall, R) 和 F1-score,这三个指标是用来衡量模型在关系抽取任务中的性能的。
计算方法:使用工具包 sklearn.metrics 。
关系抽取任务:LLM关系识别分类任务(关系多分类问题),输入 entity pair、relations。输出 best relation。
理解P/R/F1的公式

precision:预测为关系 instance of 的样本中,实际为关系 instance of 的的概率,看该类别混淆矩阵的列数据。分母是预测数据中为关系 instance of 的样本数据。
recall:真实关系为 instance of 的样本中,实际为关系 instance of 的概率,看该类别混淆矩阵的行数据。分母是 instance of 类别的所有样本数据。
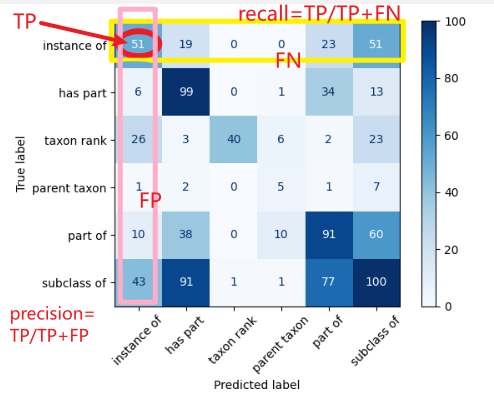
理解TP/FP/FN定义
数据示例:1000个样本数据格式:{text, head, relation, tail}。
任务:关系多分类问题,
- 输入:entity pair、relations。
- 输出:让模型从relations里面预测概率最大的一个relation。(LLM认为entity pair间不存在关系如何处理呢?)
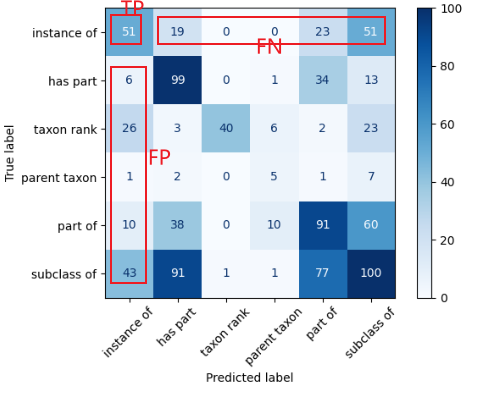
TP/FP/FN定义:
- TP 的定义:预测关系为A,真实关系也为A。(真实关系为A,预测关系也为A)
- FP 的定义:预测关系为A,真实关系为其他关系。
- FN 的定义:真实关系为A,预测关系为其他关系。
- TP 是指模型预测为某一类,且真实标签也是该类(即正确预测)。
- FP 是指模型预测为某一类,但真实标签不是该类(即错误预测)。
- FN 是指真实标签为某一类,但模型没有预测为该类(即漏预测)。
理解混淆矩阵:
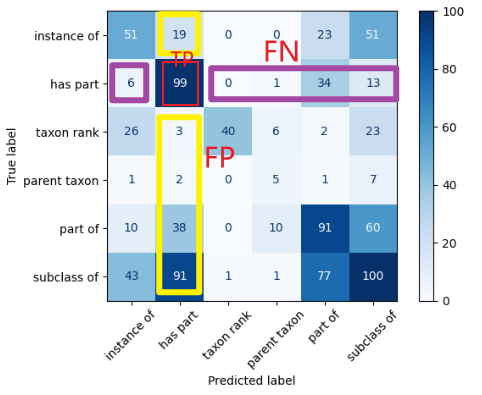
理解macro/micro/weighted
-
Micro(微平均):
- 定义: 在这种方法中,首先对所有类别的 True Positives (TP)、False Positives (FP) 和 False Negatives (FN) 进行汇总,然后使用这些总和来计算 precision、recall 和 F1 分数。
- 适用场景: 适用于类别分布比较均衡,或者你更关心整体的性能,而不是各个类别的单独性能。它对类别不平衡较为鲁棒,因为每个样本的贡献是均等的。
-
Macro(宏平均):
- 定义: 在这种方法中,先计算每个类别的 precision、recall 和 F1 分数,然后对这些单独类别的分数取平均。对每一类都赋予了相同的权重。
- 适用场景: 适用于各类别的性能比较重要的情况,尤其是在类别不平衡时。它不会受到大类别的主导影响,能反映小类别的性能。但如果某些类别的样本很少,可能导致 F1 分数不稳定。
-
Weighted(加权平均):
- 定义: 加权平均方法会根据每个类别在数据集中样本的比例,给每个类别的 precision、recall 和 F1 分数 赋予不同的权重。加权平均是根据类别出现的频率来调整每个类别的贡献。根据每一类的比例分别赋予不同的权重。
- 适用场景: 适用于类别不平衡的任务,能够综合考虑每个类别的重要性,并对类别频率较高的类别给予更大的权重。
sklearn.metrics计算分数代码demo
from sklearn.metrics import precision_score, recall_score, f1_score
# 示例数据
y_true = [0, 1, 2, 1, 0] # 真实关系标签
y_pred = [0, 1, 4, 1, 0] # 预测关系标签
# 计算精确率、召回率和F1分数
precision = precision_score(y_true, y_pred, average='macro') # 或者使用 'micro', 'weighted'
recall = recall_score(y_true, y_pred, average='macro') # 或者使用 'micro', 'weighted'
f1 = f1_score(y_true, y_pred, average='macro') # 或者使用 'micro', 'weighted'
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}")
20241211代码最新探究
import json
from sklearn.metrics import classification_report, precision_score, recall_score, f1_score
# 确保类别对齐
labels = ['instance of', 'has part', 'taxon rank', 'parent taxon', 'part of', 'subclass of']
y_true = [] # 真实关系标签
y_pred = [] # 预测关系标签
path = './output/results_final.json'
with open(path, 'r', encoding='utf-8') as file:
data = json.load(file)
for item in data:
gold_relation = item['triple']['relation']
pred_relation = item['output']['relation']
y_true.append(gold_relation)
y_pred.append(pred_relation)
print('y_true:',len(y_true) , y_true)
print('y_pred:',len(y_pred) , y_pred)
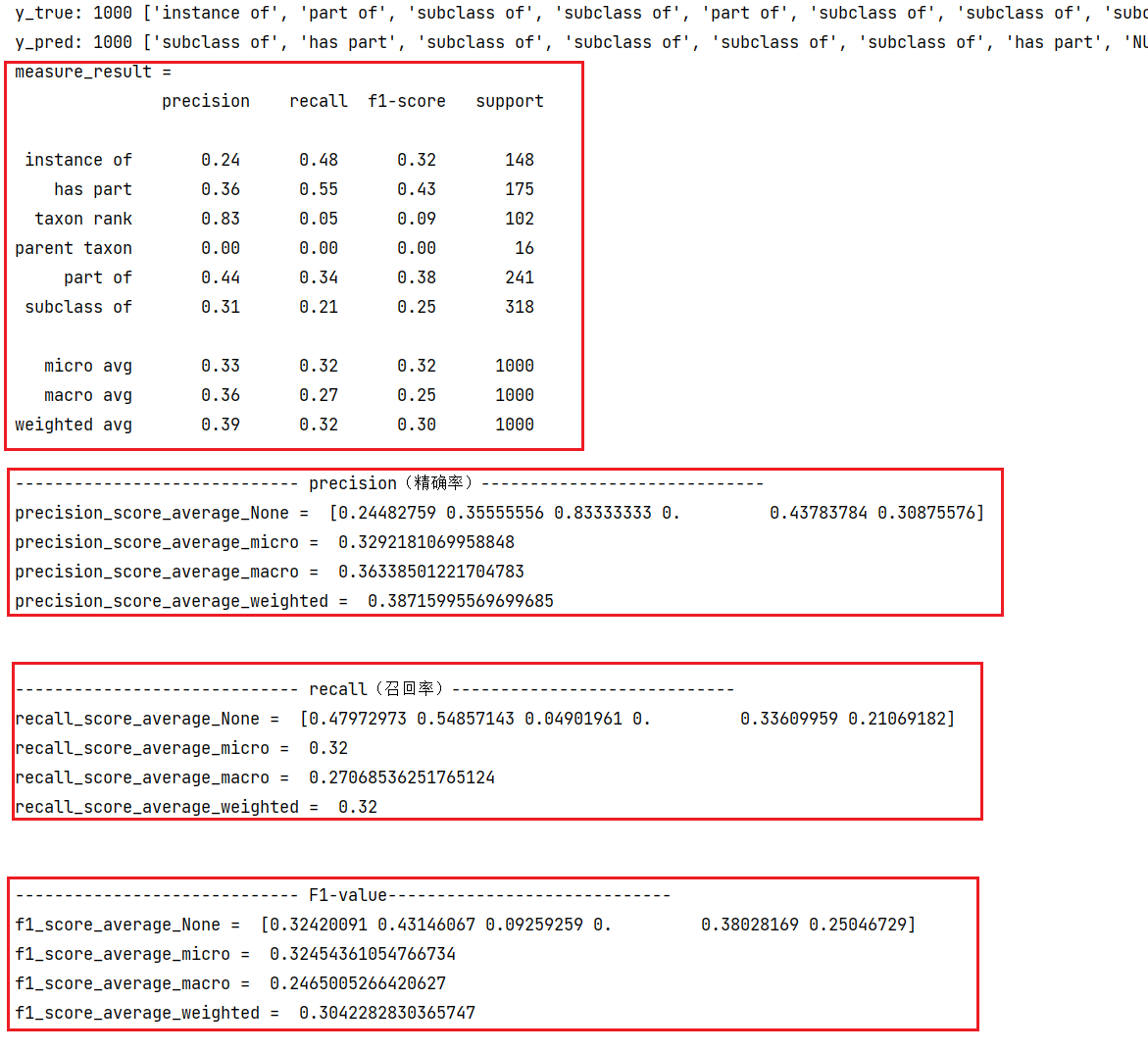
measure_result = classification_report(y_true, y_pred, labels=labels, zero_division=0)
print('measure_result = \n', measure_result)
print("----------------------------- precision(精确率)-----------------------------")
precision_score_average_None = precision_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
precision_score_average_micro = precision_score(y_true, y_pred, labels=labels, average='micro', zero_division=0)
precision_score_average_macro = precision_score(y_true, y_pred, labels=labels, average='macro', zero_division=0)
precision_score_average_weighted = precision_score(y_true, y_pred, labels=labels, average='weighted', zero_division=0)
print('precision_score_average_None = ', precision_score_average_None)
print('precision_score_average_micro = ', precision_score_average_micro)
print('precision_score_average_macro = ', precision_score_average_macro)
print('precision_score_average_weighted = ', precision_score_average_weighted)
print("\n\n----------------------------- recall(召回率)-----------------------------")
recall_score_average_None = recall_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
recall_score_average_micro = recall_score(y_true, y_pred, labels=labels, average='micro', zero_division=0)
recall_score_average_macro = recall_score(y_true, y_pred, labels=labels, average='macro', zero_division=0)
recall_score_average_weighted = recall_score(y_true, y_pred, labels=labels, average='weighted', zero_division=0)
print('recall_score_average_None = ', recall_score_average_None)
print('recall_score_average_micro = ', recall_score_average_micro)
print('recall_score_average_macro = ', recall_score_average_macro)
print('recall_score_average_weighted = ', recall_score_average_weighted)
print("\n\n----------------------------- F1-value-----------------------------")
f1_score_average_None = f1_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
f1_score_average_micro = f1_score(y_true, y_pred, labels=labels, average='micro', zero_division=0)
f1_score_average_macro = f1_score(y_true, y_pred, labels=labels, average='macro', zero_division=0)
f1_score_average_weighted = f1_score(y_true, y_pred, labels=labels, average='weighted', zero_division=0)
print('f1_score_average_None = ', f1_score_average_None)
print('f1_score_average_micro = ', f1_score_average_micro)
print('f1_score_average_macro = ', f1_score_average_macro)
print('f1_score_average_weighted = ', f1_score_average_weighted)
20241216代码最新探究
import json
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, precision_recall_fscore_support
from sklearn.metrics import classification_report, precision_score, recall_score, f1_score
# 确保类别对齐
labels = ['instance of', 'has part', 'taxon rank', 'parent taxon', 'part of', 'subclass of']
y_true = [] # 真实关系标签
y_pred = [] # 预测关系标签
path = './output/results_final.json'
with open(path, 'r', encoding='utf-8') as file:
data = json.load(file)
for item in data:
gold_relation = item['triple']['relation']
pred_relation = item['output']['relation']
y_true.append(gold_relation)
y_pred.append(pred_relation)
print('y_true:',len(y_true) , y_true)
print('y_pred:',len(y_pred) , y_pred)
cm = confusion_matrix(y_true, y_pred, labels=labels) # 显式指定标签顺序
# 创建混淆矩阵的可视化对象
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
# 生成混淆矩阵的图像, 可设置图形颜色
disp.plot(cmap=plt.cm.Blues)
# 旋转x轴标签,提高可读性
plt.xticks(rotation=45) # x轴旋转45°
plt.yticks(rotation=0) # y轴水平
plt.tight_layout() # 自动调整布局
plt.savefig('confusion_matrix.png')
# 通过 precision_recall_fscore_support 提取 TP/FP/FN
precision, recall, f1, support = precision_recall_fscore_support(y_true, y_pred, labels=labels)
# 初始化字典存储 TP、FP、FN
results = {label: {'TP': 0, 'FP': 0, 'FN': 0} for label in labels}
# 通过 precision, recall 和 support 反推出 TP、FP 和 FN
for i, label in enumerate(labels):
TP = int(support[i] * recall[i]) # recall = TP / (TP + FN)
FN = support[i] - TP # FN = 支持数 - TP
FP = int(TP / precision[i]) - TP if precision[i] > 0 else 0 # precision = TP / (TP + FP)
results[label]['TP'] = TP
results[label]['FP'] = FP
results[label]['FN'] = FN
# 输出结果
for label in labels:
print(f"类别: {label}")
print(f" TP: {results[label]['TP']}")
print(f" FP: {results[label]['FP']}")
print(f" FN: {results[label]['FN']}")
measure_result = classification_report(y_true, y_pred, labels=labels, zero_division=0)
print('measure_result = \n', measure_result)
print("----------------------------- precision(精确率)-----------------------------")
precision_score_average_None = precision_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
precision_score_average_micro = precision_score(y_true, y_pred, labels=labels, average='micro', zero_division=0)
precision_score_average_macro = precision_score(y_true, y_pred, labels=labels, average='macro', zero_division=0)
precision_score_average_weighted = precision_score(y_true, y_pred, labels=labels, average='weighted', zero_division=0)
print('precision_score_average_None = ', precision_score_average_None)
print('precision_score_average_micro = ', precision_score_average_micro)
print('precision_score_average_macro = ', precision_score_average_macro)
print('precision_score_average_weighted = ', precision_score_average_weighted)
print("\n\n----------------------------- recall(召回率)-----------------------------")
recall_score_average_None = recall_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
recall_score_average_micro = recall_score(y_true, y_pred, labels=labels, average='micro', zero_division=0)
recall_score_average_macro = recall_score(y_true, y_pred, labels=labels, average='macro', zero_division=0)
recall_score_average_weighted = recall_score(y_true, y_pred, labels=labels, average='weighted', zero_division=0)
print('recall_score_average_None = ', recall_score_average_None)
print('recall_score_average_micro = ', recall_score_average_micro)
print('recall_score_average_macro = ', recall_score_average_macro)
print('recall_score_average_weighted = ', recall_score_average_weighted)
print("\n\n----------------------------- F1-value-----------------------------")
f1_score_average_None = f1_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
f1_score_average_micro = f1_score(y_true, y_pred, labels=labels, average='micro', zero_division=0)
f1_score_average_macro = f1_score(y_true, y_pred, labels=labels, average='macro', zero_division=0)
f1_score_average_weighted = f1_score(y_true, y_pred, labels=labels, average='weighted', zero_division=0)
print('f1_score_average_None = ', f1_score_average_None)
print('f1_score_average_micro = ', f1_score_average_micro)
print('f1_score_average_macro = ', f1_score_average_macro)
print('f1_score_average_weighted = ', f1_score_average_weighted)
20241216-v2代码最新探究
- TP:预测关系为A,真实关系也为A。
- FP:预测为关系A,但真实关系为其他关系。
- FN:真实关系为A,预测关系为其他关系(包含NULL)。
1计算Micro 微平均:
- Precision = 关系识别正确数/总样本-NULL样本
- Recall = 关系识别正确数/总样本。
2计算 Macro 宏平均:
计算每个类别的precision、recall、f1-score,汇总取平均值。
import json
import matplotlib
import numpy as np
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, precision_recall_fscore_support
from sklearn.metrics import classification_report, precision_score, recall_score, f1_score
# 确保类别对齐
labels = ['instance of', 'has part', 'taxon rank', 'parent taxon', 'part of', 'subclass of', 'NULL']
y_true = [] # 真实关系标签
y_pred = [] # 预测关系标签
NULL_SAMPLES = 0 # 预测关系中不存在关系的样本数
RELATIONS = 6 # 关系类型数量
path = './output/results_final.json'
with open(path, 'r', encoding='utf-8') as file:
data = json.load(file)
for item in data:
gold_relation = item['triple']['relation']
pred_relation = item['output']['relation']
if pred_relation == 'NULL':
NULL_SAMPLES += 1
y_true.append(gold_relation)
y_pred.append(pred_relation)
cm = confusion_matrix(y_true, y_pred, labels=labels) # 显式指定标签顺序
# 创建混淆矩阵的可视化对象
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
# 生成混淆矩阵的图像, 可设置图形颜色
disp.plot(cmap=plt.cm.Blues)
# 旋转x轴标签,提高可读性
plt.xticks(rotation=45) # x轴旋转45°
plt.yticks(rotation=0) # y轴水平
plt.tight_layout() # 自动调整布局
plt.savefig('confusion_matrix.png')
# 获取每个类别的precision/recall/f1/support
precision, recall, f1, support = precision_recall_fscore_support(y_true, y_pred, labels=labels, zero_division=0)
# 初始化字典存储 TP、FP、FN
results = {label: {'TP': 0, 'FP': 0, 'FN': 0} for label in labels}
# 通过 precision, recall 和 support 反推出 TP、FP 和 FN
for i, label in enumerate(labels):
TP = int(support[i] * recall[i]) # recall = TP / (TP + FN)
FN = support[i] - TP # FN = 支持数 - TP
FP = int(TP / precision[i]) - TP if precision[i] > 0 else 0 # precision = TP / (TP + FP)
results[label]['TP'] = TP
results[label]['FP'] = FP
results[label]['FN'] = FN
results[label]['support'] = support[i]
# 输出结果
ALL_TP = 0
ALL_SAMPLES = 0
for label in labels:
ALL_TP += results[label]['TP']
ALL_SAMPLES += results[label]['support']
micro_P = ALL_TP/(ALL_SAMPLES-NULL_SAMPLES) if ALL_SAMPLES-NULL_SAMPLES > 0 else 0
micro_R = ALL_TP/ALL_SAMPLES if ALL_SAMPLES > 0 else 0
micro_F1 = (2 * micro_P * micro_R) / (micro_P + micro_R) if (micro_P + micro_R) > 0 else 0
# 将结果保存到文本文件
with open('results.txt', 'w') as f:
f.write("----------------------------- 方法1-手动计算 -----------------------------\n")
f.write("----------------------------- micro(微平均)-----------------------------\n")
f.write(f"micro_P: {micro_P * 100:.2f}%\n")
f.write(f"micro_R: {micro_R * 100:.2f}%\n")
f.write(f"micro_F1: {micro_F1 * 100:.2f}%\n\n")
f.write(f"micro_P: {micro_P :.2f}\n")
f.write(f"micro_R: {micro_R :.2f}\n")
f.write(f"micro_F1: {micro_F1 :.2f}\n\n")
precision_score_average_Single = precision_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
recall_score_average_Single = recall_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
f1_score_average_Single = f1_score(y_true, y_pred, labels=labels, average=None, zero_division=0)
macro_P = np.sum(precision_score_average_Single) / RELATIONS
macro_R = np.sum(recall_score_average_Single) / RELATIONS
macro_F1 = np.sum(f1_score_average_Single) / RELATIONS
f.write("----------------------------- macro(宏平均)-----------------------------\n")
f.write(f"macro_P: {macro_P * 100:.2f}%\n")
f.write(f"macro_R: {macro_R * 100:.2f}%\n")
f.write(f"macro_F1: {macro_F1 * 100:.2f}%\n\n")
f.write(f"macro_P: {macro_P :.2f}\n")
f.write(f"macro_R: {macro_R :.2f}\n")
f.write(f"macro_F1: {macro_F1 :.2f}\n\n")
f.write("----------------------------- 方法2-自动计算(classification_report)-----------------------------\n")
# 方法2
measure_result = classification_report(y_true, y_pred, labels=[label for label in labels if label != 'NULL'], zero_division=0) # 计算macro需要labels去掉NULL
# print('measure_result = \n', measure_result)
f.write(f"measure_result: {measure_result}\n")
















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









