




 DEC算法利用深度自动编码器进行数据聚类,通过深度神经网络学习特征空间和聚类中心。算法分为初始化和优化两阶段,采用KL散度最小化辅助目标分布,通过软分配和目标分布的匹配逐步优化聚类效果。实验中,DEC借助堆叠自动编码器初始化参数,并通过迭代优化提升聚类质量。
DEC算法利用深度自动编码器进行数据聚类,通过深度神经网络学习特征空间和聚类中心。算法分为初始化和优化两阶段,采用KL散度最小化辅助目标分布,通过软分配和目标分布的匹配逐步优化聚类效果。实验中,DEC借助堆叠自动编码器初始化参数,并通过迭代优化提升聚类质量。
算法(DEC)通过同时学习特征空间Z中的k个聚类中心{μj∈Z} j = 1 … k和将数据点映射到Z的DNN参数θ来对数据进行聚类。两个阶段:(1)使用深度自动编码器进行参数初始化和(2)参数优化(即,聚类),在此过程中,我们在计算辅助目标分布与最小化Kullback-Leibler(KL)差异之间进行迭代。我们从描述阶段(2)参数优化/聚类开始,给定θ的初始估计值,且{µj} j = 1,… k。
KL聚类
给定非线性映射fθ的初始估计和初始聚类质心{μj} kj = 1,我们建议使用在两步之间交替的无监督算法来改善聚类。第一步,我们计算嵌入点和聚类质心之间的软分配。在第二步中,我们通过使用辅助目标分布从当前的高置信度分配中学习来更新深度映射fθ并优化聚类质心。重复该过程,直到满足收敛标准为止。
软分配
我们使用学生的t分布作为核来衡量嵌入点zi和质心µj之间的相似度:

其中zi =fθ(xi)∈Z对应于嵌入后的xi∈X,其中α是学生t分布的自由度,而qij可解释为将样本i分配给聚类j的概率(即软分配)。 由于我们无法在无人监督的设置中对验证集上的α进行交叉验证,并且得知它是多余的,因此对于所有实验,我们让α= 1。
KL分流最小化
在辅助目标分布的帮助下,通过从集群的高可信度分配中学习来迭代地优化集群。具体来说,通过将软分配与目标分布匹配来训练我们的模型。为此,我们将目标定义为软分配qi和辅助分布pi之间的KL散度损失,如下所示:

目标分布P的选择对于DEC的性能至关重要。一种方法是将每个pi设置为高于置信度阈值的数据点的delta分布(至最接近的质心),并忽略其余部分。但是,由于qi是软分配,因此使用较软的概率目标更为自然和灵活。
具体来说,我们希望我们的目标分布具有以下属性:
(1)加强预测(即提高簇纯度),
(2)更加注重以高置信度分配的数据点
(3)归一化每个质心的损耗贡献,以防止大型聚类扭曲隐藏的特征空间。
在我们的实验中,我们通过先将qi升至第二次幂,然后通过每个群集的频率进行归一化来计算pi:


fj为软簇频率。培训策略可以看作是一种自我培训的形式。与自训练中一样,我们采用初始分类器和未标记的数据集,然后使用分类器标记数据集,以便对其自身的高置信度预测进行训练。实际上,在实验中,我们观察到DEC通过学习高置信度预测来提高每次迭代中的初始估计,从而有助于改善低置信度预测。
优化
我们使用带有动量的随机梯度下降(SGD)联合优化聚类中心{µj}和DNN参数θ。关于每个数据点zi和每个聚类质心µj的特征空间嵌入的L梯度计算如下:

然后将梯度∂L/∂zi向下传递到DNN,并在标准反向传播中用于计算DNN的参数梯度∂L/∂θ。在两次连续的迭代中,当有少于tol%的点会更改聚类簇的时候,停止执行该过程。
参数初始化
已经讨论了在给定DNN参数θ和簇质心{μj}的初始估计后DEC如何进行。现在我们讨论如何初始化参数和质心。我们使用堆叠式自动编码器(SAE)初始化DEC,因为最近的研究表明,它们在真实数据集上始终产生语义上有意义且分隔良好的表示形式。因此,SAE学习的无监督表示自然促进了DEC聚类表示的学习。我们逐层初始化SAE网络,每一层都是经过降噪处理的自动编码器,经过训练可以在随机破坏后重建上一层的输出。去噪自动编码器是一个两层神经网络,定义为:


其中Dropout(·)是随机映射,它随机地将其一部分输入维设置为0,g1和g2分别是用于编码和解码层的激活函数,θ= {W1,b1,W2,b2}是模型参数。 通过最小化最小二乘损失
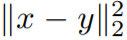
进行训练。 训练完一层后,我们将其输出h作为输入来训练下一层。 我们在所有编码器/解码器对中都使用整流线性单位(ReLU),除了第一对中的g2(它需要重建可能具有正值和负值的输入数据,例如零均值图像)和最后一对中的g1 (因此最终的数据嵌入会保留完整的信息)。
经过贪婪的逐层训练后,我们以反向逐层训练顺序将所有编码器层与所有解码器层连接起来,形成一个深层的自动编码器,然后对其进行微调,以最大程度地减少重建损失。最终结果是多层深层自动编码器,中间有一个瓶颈编码层。然后,我们丢弃解码器层,并将编码器层用作数据空间和特征空间之间的初始映射,如图1所示。
为了初始化聚类中心,我们通过初始化的DNN传递数据以获取嵌入的数据点,然后在特征空间Z中执行标准k均值聚类以获得k个初始质心{µj} kj = 1。
ACC
对于所有算法,我们将簇的数量设置为真实类别的数量,并以无监督的簇精度(ACC)评估性能:

其中li是真实标签,ci是算法产生的聚类分配。
调整
我们将常用参数用于DNN,并尽可能避免特定于数据集的调整。具体而言,受van der Maaten(2009)的启发,我们将所有数据集的网络维度都设置为d–500–500–2000–10,其中d是数据空间维度,在数据集之间会有所不同。所有层都紧密(完全)连接。在贪婪的逐层预训练过程中,我们将权重初始化为从零均值高斯分布(标准差为0.01)得出的随机数。每层都进行了50000次迭代的预训练,辍学率为20%。整个深度自动编码器可进一步微调100000次迭代而不会丢失。对于自动编码器的逐层预训练和端到端微调,最小批量大小设置为256,起始学习率设置为0.1,每20000次迭代除以10,权重衰减设置为0。全部设置以上参数中的一个以实现合理的重建损失,并在所有数据集中保持恒定。这些参数的特定于数据集的设置可能会提高每个数据集的性能,但是我们避免这种类型的不切实际的参数调整。为了初始化质心,我们使用20次重启来运行k-means并选择最佳解决方案。在KL散度最小化阶段,我们以0.01的恒定学习率进行训练。收敛阈值设置为to1 = 0.1%。
对于所有基线算法,我们在初始化质心时执行20次随机重启,并选择具有最佳目标值的结果。
假设与目标
DEC的基本假设是,初始分类器的高置信度预测大部分是正确的。
迭代优化的贡献
集群之间的隔离度越来越高。
自动编码器初始化的贡献
深度嵌入的强大功能以及通过提出的KL散度目标进行微调的好处。
最佳聚类数
需要一种确定最佳簇数的方法。 为此,我们定义了两个度量:
(1)标准度量,归一化互信息(NMI):

其中I是互信息量度,而H是熵
(2)可概括性(G),其定义为训练与验证损失之间的比率:

当训练损失低于验证损失时,G很小,这表明过度拟合的程度很高。
结论
DEC-一种在联合优化的特征空间中将一组数据点聚类的算法。 DEC通过使用自训练目标分布迭代地优化基于KL散度的聚类目标来工作。 我们的方法可以看作是半监督自我训练的无监督扩展。

















 6969
6969




 到【灌水乐园】发言
到【灌水乐园】发言







