 评分卡变量分箱方法及代码介绍
评分卡变量分箱方法及代码介绍





评分卡在建模之前,需要对变量进行分箱,它可以分析变量的有效性、加强模型的泛化能力,同时使评分卡模型可以以卡表形式来表示。变量分箱在评分卡制作中是不可缺乏的一个环节,本文介绍评分卡变量分箱的方法、代码。
一、评分卡的变量分箱-介绍
1.1.什么是变量的分箱
评分卡在建模之前,需要对变量进行分箱,即将变量进行如下的形式的分析:
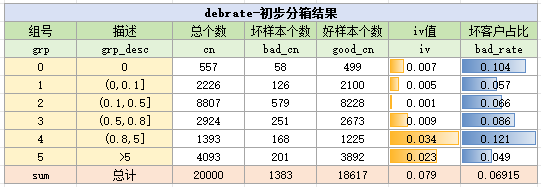
如图所示,需要先对变量进行分箱(即分组),然后统计出每一组的总个数、坏样本个数、好样本个数,并统计出IV值和坏客户的占比。
其中,如何将变量分箱,可以选择手动自行设置,也可以借助分箱算法来完成,下文再详细介绍。
1.2.分箱的作用
分箱的作用主要有三个,如下:
1.分析变量的有效性
借助分箱来分析x与y的关系,可以在建模前挑选有效的变量来作为建模的变量,避免使用无效变量进行建模,干扰模型的准确性、合理性。
2.加强模型的泛化能力
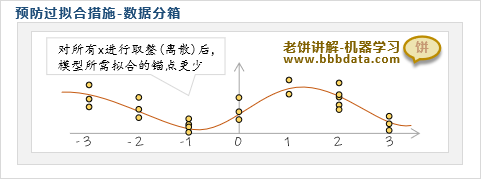
对数据分箱可以合理地减少模型所需拟合的锚点,并加强了每个锚点的稳定性,通过对变量进行分箱,可以降低噪声数据带来的影响,使模型曲线更平滑。
3.使模型可以以卡表形式表示
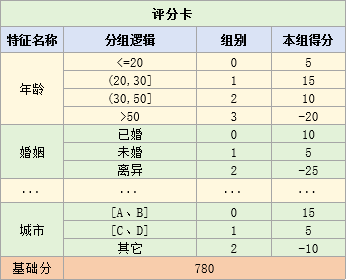
如图所示,只有进行分箱,才可以让模型以卡表形式来表示,即"样本分在了哪一组,得了多少分"。
二、分箱与变量分析
下面是一个变量的分箱,它包括了每一组的总个数、坏样本个数、好样本个数,以及IV值和坏客户的占比。
2.1.如何通过分箱来分析变量
对变量的有效性的判断一共有两种方法:
1.根据badrate的趋势来判断变量的有效性
如果坏客户占比(badrate)与分组有明显的趋势,则说明变量与y有强烈关系,如果没有明显的趋势,则说明关系不明显。
2.根据iv值来判断变量的有效性
IV也是用来判断x与y的关联性的一个常用指标,一般来说,IV值与变量对好坏客户的区分度的关系如下:

备注:IV值小并不说明变量完全无效,它仅作为参考值,并不是变量有效性的绝对评估
2.2. IV与badrate的优缺点
用badrate来分析的好处是,可以兼顾业务的合理性来分析badrate,它相比IV更加可靠。
而用iv来分析的好处是,它可以不依赖人的主观判断,可以只设定一个阈值,将IV值大于该阈值的变量作为入模变量,这也使得用IV作为依据时可以完全程序自动化。
三、如何分箱
对变量分箱可以分为手动分箱和自动分箱。手动分箱顾名思义,就是自行设置每组的取值范围。而自动分箱,则一般借助分箱算法来自动完成。
python的bbbrisk包提供了相关的数据,以及相关的分箱算法。下面以bbbrisk包来讲述变量的分箱方法与实际操作。
3.1.手动分箱
手动分箱依赖于对业务的理解,通过对变量的理解,来设定各个分箱的取值范围,然后统计出badrate、iv等指标。
下面以bbbrisk的rev变量为例,我们可以设定具体的分箱,然后统计出相关的指标。具体代码如下:
import bbbrisk as br
from bbbrisk import bins
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data['rev'] # rev变量
y = data['is_bad'] # 标签
# 手动分箱
bin_set = [[0,0.1],(['-',0],[0.1,0.37]),[0.37,0.64],([0.64,1.2],[2,'+']),[1.2,2]] # 设置变量的分箱
bin_stat = bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
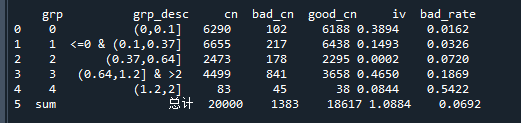
print('\n',bin_stat) # 显示分箱结果
运行结果如下:
3.2.自动分箱
自动分箱是指使用各种分箱算法对变量进行自动分箱,常用的分箱算法有:等频分箱、等距分箱、卡方分箱、KS分箱、决策树分箱等等。
虽然分箱算法有很多,但一般最常用的是卡方分箱,它的效果相对较好一些。
下面以bbbrisk的rev变量为例,我们指定使用卡方分箱、对rev变量进行分箱,然后统计出相关的指标。具体代码如下:
import bbbrisk as br
data = br.datasets.load_bloan() # 加载数据
x = data['rev'] # rev变量
y = data['is_bad'] # 样本标签
# 卡方分箱
bin_set = br.bins.merge.chi2(x,y,bin_num=5,init_bin_num=10) # 进行卡方分箱,bin_num是目标箱数,init_bin_num是初始箱数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* 卡方分箱结果:\n',bin_stat) # 显示分箱结果
# KS分箱
bin_set = br.bins.merge.ks(x,y,bin_num=5,min_sample=None) # 进行KS分箱,bin_num是目标箱数,min_sample是最小样本数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* KS分箱结果:\n',bin_stat) # 显示分箱结果
# 决策树分箱
bin_set = br.bins.merge.tree(x,y,max_depth=3,min_sample=None) # 进行决策树分箱,max_depth是树深度,min_sample是叶子最小样本数
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计分箱结果
print('\n* 决策树分箱结果:\n',bin_stat) # 显示分箱结果
代码运行结果如下:
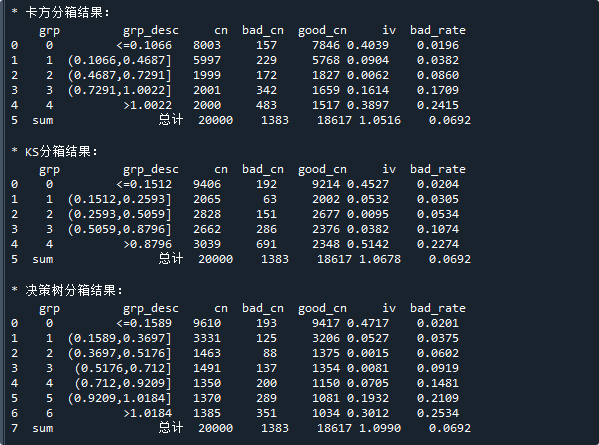
可以看到, 卡方分箱、KS分箱、决策树分箱最终的IV值分别为1.05、1.06、1.09。
四、结束语
好了,以上就是评分卡变量分箱的介绍与方法了,更多可以参考如下内容:
《评分卡-入门教程》
《评分卡-分箱教程》
《bbrisk-API说明》


















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











