






 本文探讨了推荐系统的需求、应用场景及常见算法,如基于用户和物品的协同过滤。内容涵盖推荐系统的输入输出、核心问题及解决策略,强调了在不同场景下选择合适推荐方法的重要性。
本文探讨了推荐系统的需求、应用场景及常见算法,如基于用户和物品的协同过滤。内容涵盖推荐系统的输入输出、核心问题及解决策略,强调了在不同场景下选择合适推荐方法的重要性。
1. 为什么需要推荐系统
我觉得商人嘛,就是要不断让客户买自己的东西,TA喜欢什么我就给TA什么。
包括现在网站也是,都是要尽量的留住用户,占用这个用户的时间,比如今日头条或者内涵段子之类的
其实这个思路自古有之,只是那个时候就是商人自己完成这个事情,现在大规模的交易在线上完成,自然我们就需要把这种功能利用机器的方式来实现,用机器的方式来实现推荐系统的功能就是
2. 都什么地方需要推荐系统
除了电商,经营内容的网站也采用这种方式,时间,金钱,你总得留点东西下来。
3. 出现频率比较高的算法
“基于用户的协同过滤推荐算法” (User-based Collaborative Filtering Algorithms)
基于物品的协同过滤算法(Item-based Collaborative Filtering Algorithms)
基于矩阵分解的协同过滤算法(SVD-based/NMF-based)
4. 推荐系统的输入和输出
输入: 就是一个矩阵,矩阵的行代表用户(user),列代表物品(items),值是评价(value)
用户也好,物品也好,评价也好,都是对同一个对象不同侧面和不同纬度的刻画。
物品也不一定是物品,也有可能是电影、文章等可以消费的东西。
这个矩阵叫做用户评分矩阵(the Rating Matrix)
输出:输出的是一个有优先次序的列表
这里设计到排序哦
5. 推荐系统要解决什么问题(数学形式化的语言,如何定义为一个数学问题)
给定一个已经存这着大量数据的用户评分矩阵,对于某一个user,向其推荐那些他没有打过分的item,他能够接受。
6. 两大核心问题
其实也就是推荐系统在运行的过程中两个核心的步骤
一个是预测:根据已有的信息,计算一个user在他没有打分的items上可能进行打分,如同上面的形式化定义
一个是推荐:计算出来的结果是一个长长的列表,用户不可能看完,于是就得选择一部分给他,怎么选也是有讲究的。
7. 推荐的方法
7.1 基于人口统计学的推荐(Demographic-Based Recommendation)
其实它也是基于“一个用户有可能能会喜欢与其相似的用户所喜欢的商品”这个假设的。
问题就在于如何定义“相似”
这种推荐方法,是基于非常粗浅的人口统计学的指标,比如年龄,性别这样的东西而非个人喜好。
7.2 基于内容的推荐(Content-Based Recommendation)
“一个用户有可能会喜欢和他曾经喜欢过的物品相似的物品”。
那么如何计算出和他曾经喜欢过的物品相似的物品呢?
其实这个问题可以改成所有这个客户没有尝试过的物品和这个客户喜欢过的物品之间的相似度进行计算。
首先我们就要拉出一个用户喜欢物品的清单(当然要考虑再一个特定的时间段,因为时间太长用户的喜好可能会发生变化)
之后我们就可以计算某一个其它这个客户没有尝试过的物品和客户喜欢的所有物品之间的相似度之后加权平均。
比较好的应对“冷启动”问题
7.3 基于协同过滤的推荐(Collaborative Filtering-Based Recommendation)分为
- 基于用户的协同过滤(User-based Recommendation)
- 基于物品的协同过滤(Item-based Recommendation)
- 基于模型的协同过滤(Model-based Recommendation)
要利用大稀疏矩阵,为了减少计算量可以先对用户或物品进行聚类
7.3.1 基于用户的协同过滤
和“基于人口统计的推荐”类似的原理,只是我们认为“用户相似”不是基于用户的人口统计特征,而是基于用户的喜好特征。具体的来讲,就是这两货喜欢的物品都差不多。
首先一个用户用一个向量进行表示(这个向量应该就是那个用户评分矩阵的行向量)
利用“pearson相关系数” “余弦相似度”计算他与所有其它用户之间相似度,找出与这个用户最相似的前K个用户。之后根据Top-K个用户的打分情况对这个用户没有打分的情况进行预测。
缺点是:如果用户数据量变大,那么计算TOP-K的时间会极大的变长。另外新用户加入的冷启动也是一个问题。
7.3.1 基于物品的协同过滤
把每一个item看成一个列向量(用户评分矩阵的列向量),计算这个item和其它所有item的相似度。这样我们就可以在用户选择了一个商品之后,把和这个商品相似的前K个商品再推荐给客户了。
细节:对于客户没有买过的item,我们可以拿出这个用户已经买过的所有item,用这些item和没有买过的item之间的相似度为权重,用买过的item的打分和这些权重做一个加权平均,作为没买过item的分数。用这种方法把所有的item的加权分数都计算一遍,之后安装打分的高低排序。
怎么感觉基于物品的协同过滤的感觉和基于物品的推荐差不多啊
计算简单,实时响应。相对于user打分来说,变化小,可以离线计算,实时响应。
7.3.2 对比总结
我们就从计算量这一个单一的纬度来
如果一个物品数量大于用户数量,而且物品数量并不是频繁更新的系统,利用item-base的方法会更好。
这个也是Amazon在2001年基于user-based的方法计算量太多难以实时响应的问题提出的解决方案,而且是Amazon的核心算法。
对于那种内容不断的更新,比如微博、博客,新闻这样的系统,就不适合用item-base的方法了。
8. 推荐方法的混合
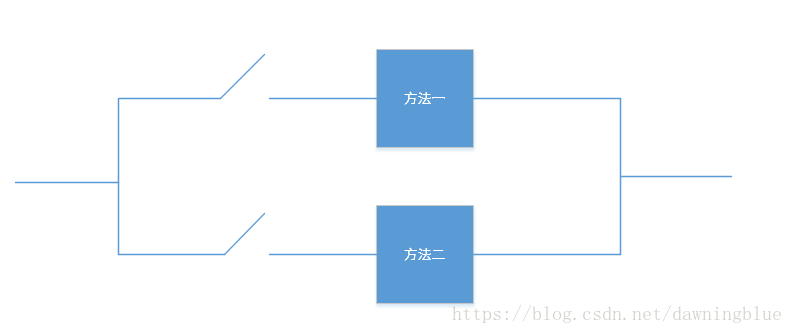
切换
方法的整体替换,这个行不行,不行就整体换另一种方法
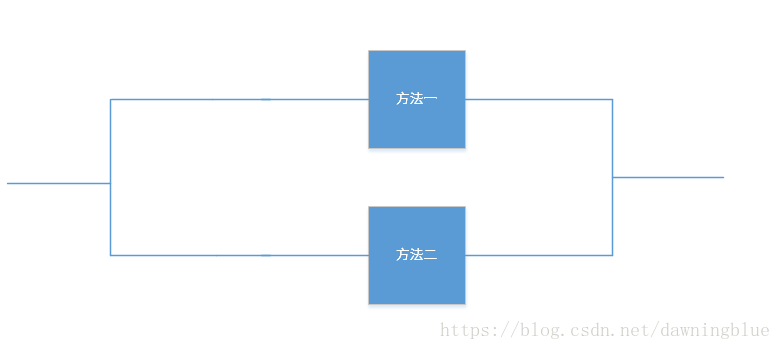
混合
我同时跑两个方法,然后把两个方法的结果混合在一起,如何排序是一个问题
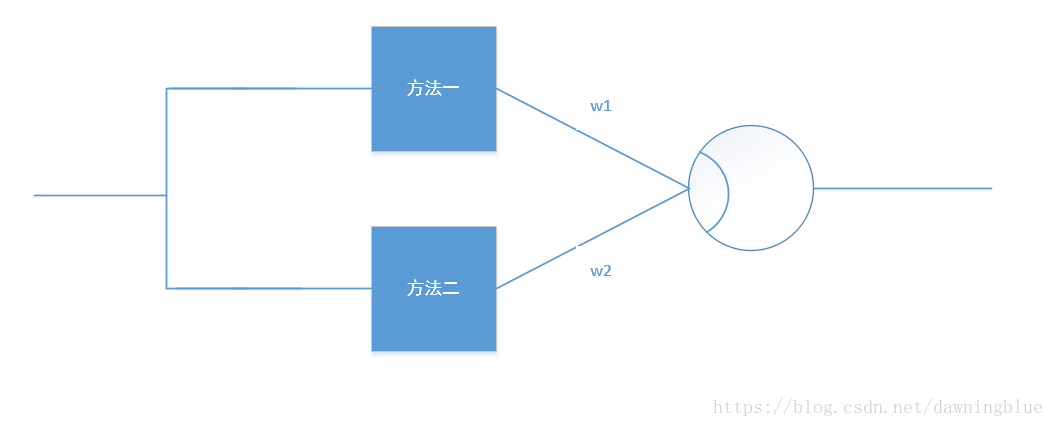
加权混合
利用感知机的线性混合,将基于协同过滤的和基于内容的推荐结果混合起来。
具体怎么操作的呢?
这是不是上一种混合方式的细化呢?
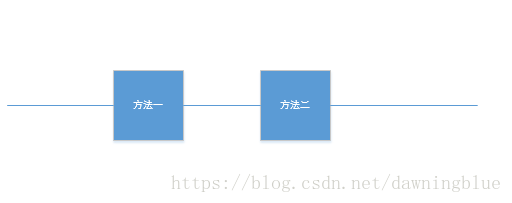
级联
总的方法是先用一种方法对结果进行一个初次的筛选,之后在用另一个方法做更细致的筛选。
特征递增
这个和级联的思路有点像,但是他的层次不同,级联的层次是在物品上。
但是特征递增是在数据加工层面上,上一层次的计算结果为下一层次提供某些特征,或者上一层次的计算结果可以当作下一层次的一个预处理。
这个和成品预处理的层次还是不一样的。
元层次混合
举个例子把U和I混合的方式
先求目标物品的相似物品集合(这一步是I的典型处理方式)
删去其它所有物品,
在相似集合上采用基于U的算法
9. 评价系统
这个其实很重要,这里先省略

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









