




导读:
本期是DataFun深入浅出Apache Spark第一期的分享,主讲老师耿嘉安开场介绍了自己的从业经历,当前就职的数新网络与Spark相关的两款产品赛博数智引擎CyberEngine和赛博数据智能平台CyberData。
本次分享题目为《Spark内核的设计原理》,主要介绍:
-
初识Spark
-
Spark有哪些特点
-
Spark基本概念
-
Spark的核心功能
-
Spark模型设计
-
Spark部署架构
▌初识Spark
Spark是一个通用的并行计算框架,由加州伯克利大学的AMP实验室在2009年开发,并且在2010年以0.6版本开源,2013年左右成为Apache旗下在大数据领域最活跃的开源项目之一。

▌Spark有哪些特点
Spark的基本特点可归纳为以下五点:灵活的内存管理,灵活的并行度控制,可选的Shuffle排序,避免重新计算,减少磁盘I/O。
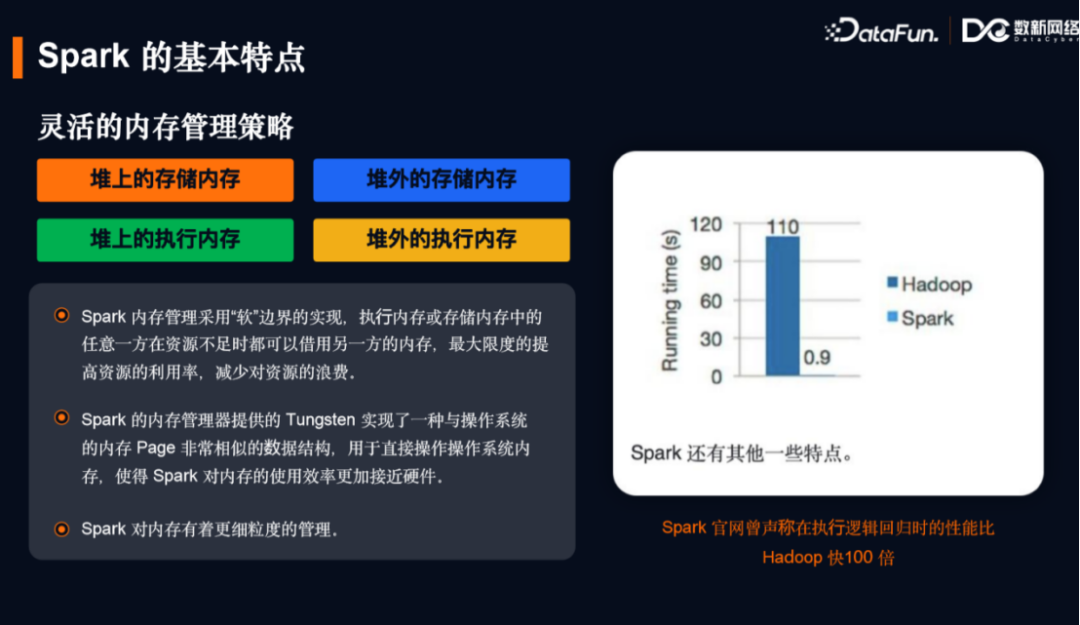
1.灵活的内存管理
减少了内存溢出的问题,用逻辑规划将JVM内存按照堆内/堆外,存储/计算分为四个象限。其中执行和存储内存的边界并不固定,通过逻辑规划来进行约定,可以相互借用,以此来提高内存资源的利用率,减少资源的浪费。Spark 1.4版本在内存管理器上通过“钨丝计划(Tungsten)”实现了一种与操作系统内存页非常相似的数据结构,内存管理可以直接向操作系统申请/释放内存,避免了JVM额外的开销,使得内存分配效率更加接近硬件。同时Spark有任务级别的内存管理,任务的计算属于执行内存的一部分。
2.灵活的并行度控制
Spark通过Shuffle依赖的关系把不同的环节抽象为Stage的概念,允许多个Stage既可以串行执行,又可以并行执行提升并行度。同时Stage内部由一系列的RDD组成,RDD允许用户自定义自身的并行度,能够更加有效应对海量数据的场景。
3.科学的Shuffle排序
Hadoop早期的MR在Shuffle之前会有固定的排序,便于后期Reduce端拉取数据。对于Spark这点是可选步骤,根据场景特点可在Shuffle之前的Map端或者之后的Reduce端进行排序。
4.避免重新计算
从Stage构建出来的DAG血缘关系能够在执行失败的时候重新调度,加上对检查点的支持可以避免重复计算,这点对于大数据量场景下的稳定运行非常关键。
5.减少磁盘I/O
最早期的时候,Spark和MapReduce类似,在Map端生成中间数据时,会针对每个Reduce端生成文件,从而产生很多小文件。后期Spark版本优化引入分区索引,Map端不会为下游Reduce端单独生成小文件,而是通过索引构建文件的方式,用偏移量为下游Reduce端拉取数据做服务。每个分区是顺序写的方式,在Reduce端读数据的时候也是顺序读取,避免了随机读,减少了大量的磁盘I/O开销。同时Spark Driver端支持把通过spark-submit命令提交的jar包等资源文件缓存到本地服务内存中,在Executor端执行的时候可以直接通过Netty拉过去,也是一个节省I/O方面的改进。
6.Spark
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









