



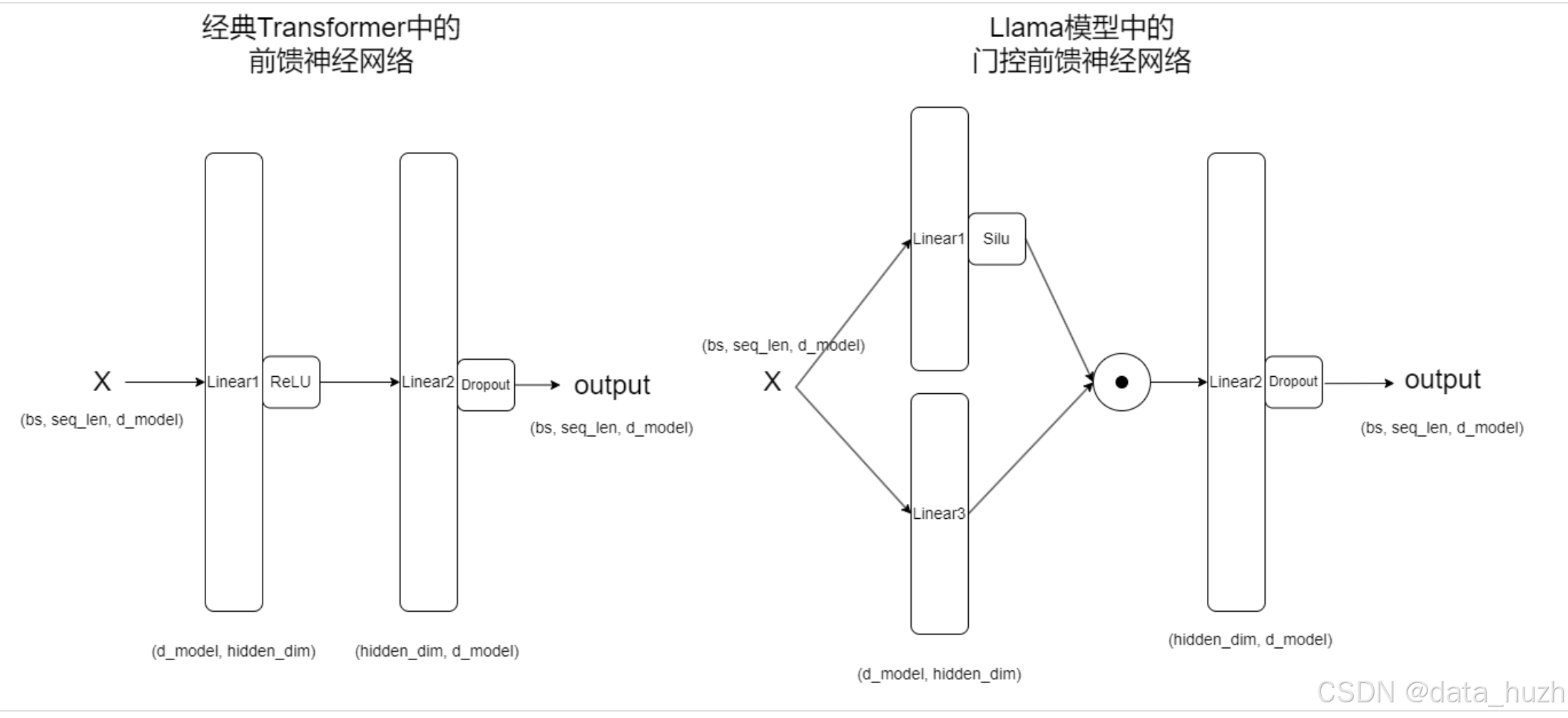
经典前馈神经网络:output = Linear2(ReLU(Linear1(x)))
llama中的前馈神经网络:output = Linear2(Silu(Linear1(x))Linear3(x))
SwiGLU(Switch-Gated Linear Unit)门控线性单元激活函数
SwiGLU 是一种新型的激活函数,由 Shazeer (2020) 在论文 “Gated Linear Units for Efficient and Scalable Deep Learning” 中提出。它被用在 深度学习模型的前馈神经网络(FFN)层,如 LLaMA、GPT-3 和其他大型 Transformer 模型中。SwiGLU 的设计核心是基于门控机制(gating mechanism),它通过引入两个线性路径的输出,并结合逐元素乘法,实现了对信息的动态控制。这种门控结构类似于在 LSTM 和 GRU 等门控循环网络中的思想,但它被应用在 Transformer 的前馈网络(FFN)层中,用于增强网络的非线性表达能力和训练效率。
SwiGLU = GELU(Linear1(x))Linear2(x)
GELU(Gaussian Error Linear Unit)是一个非线性激活函数,它与ReLU激活函数类似,但它比 ReLU 更平滑,适用于深度模型。
为什么要使用SwiGLU而不是ReLU?
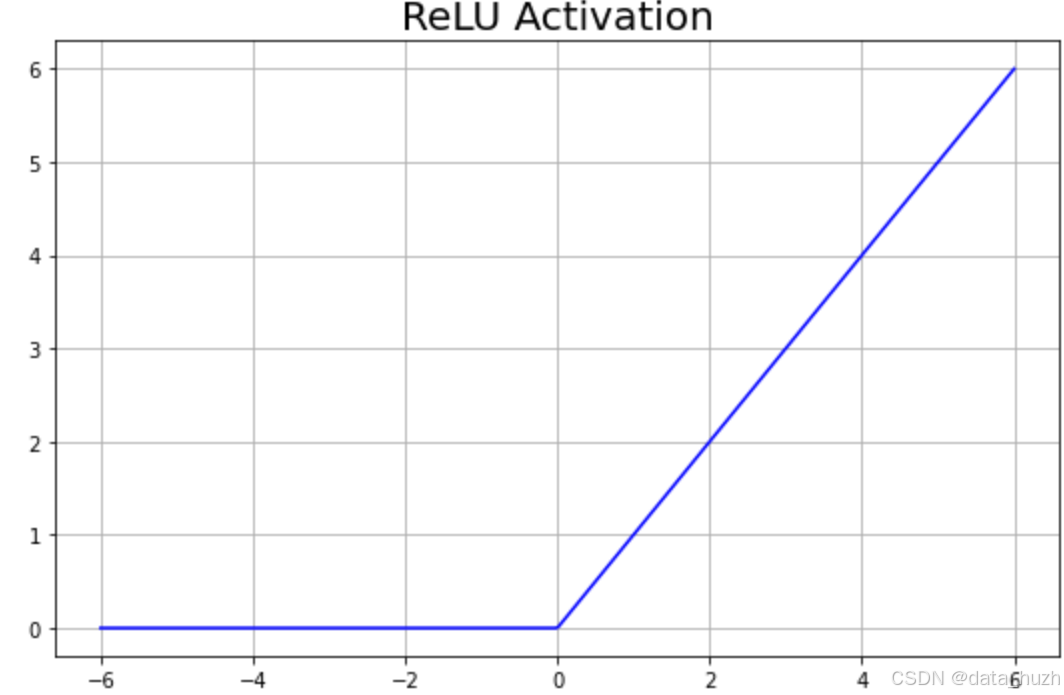
ReLU容易丢失负值信息,负值梯度为0可能导致死神经元
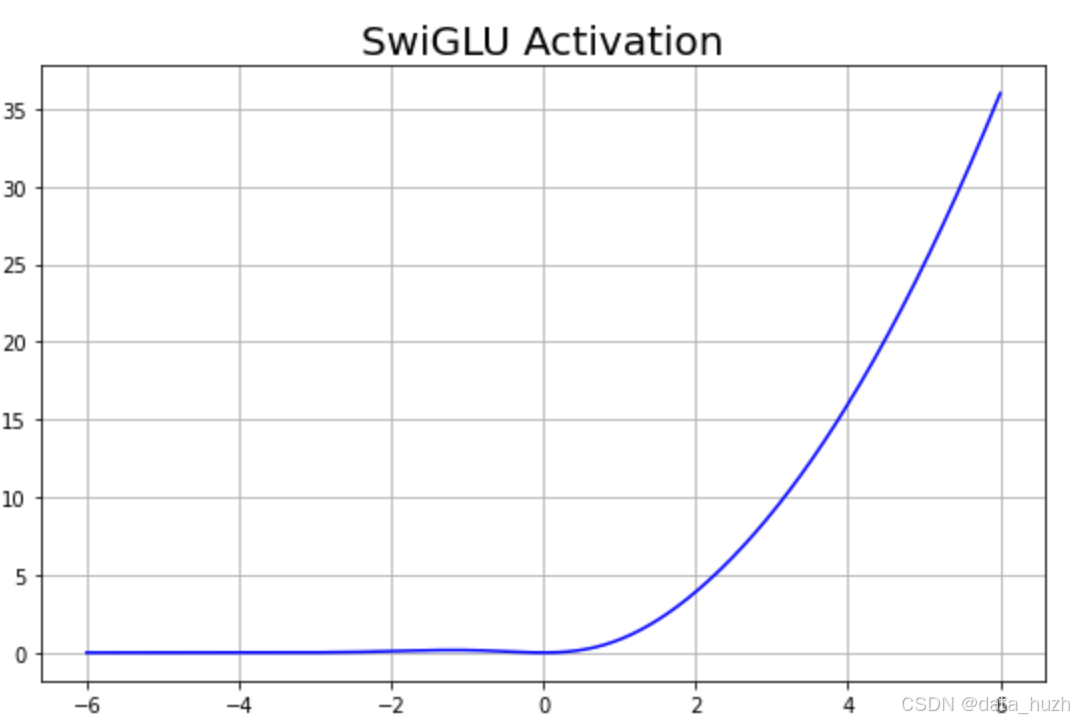
SwiGLU更平滑的梯度流动,训练更稳定,高效计算适合大规模模型
门控机制为什么高效?
参数学习:在训练过程中,网络通过反向传播算法学习门控单元的参数。这些参数决定了门控单元如何以及在何种程度上开启或关闭,从而让网络学会在特定任务中哪些信息是有用的。
优化和泛化:通过训练,门控机制能够优化网络在特定任务上的性能,并且由于其灵活性,它们通常具有良好的泛化能力。
门控机制通过训练过程中的参数学习和优化,为神经网络提供了一种强大且灵活的方式来管理和利用信息。这种能力并非来自预定义的函数规定,而是通过模型自身学习到的。
Llama架构中的激活函数
在实际实现LLaMA架构的时候,LLaMA官方却没有用广受好评的GELU函数,而是使用了SILU激活函数。SiLU 是一种平滑的非线性激活函数,全称为 Sigmoid-Weighted Linear Unit。它是由 Sigmoid 函数与输入的乘积构成的激活函数,具有较好的梯度流动特性,常用于深度神经网络的激活层中。SiLU 在许多深度学习任务中表现优于传统的激活函数(如 ReLU),并且已经被应用在 Transformer 等现代架构中(例如,EfficientNet 以及一些 NLP 模型)。
因此在LLaMA的前馈神经网络中我们实现的实际上是——
output(x) = Linear2(SiLU(Linear1(x))Linear3(x))


















 290
290



 到【灌水乐园】发言
到【灌水乐园】发言








