



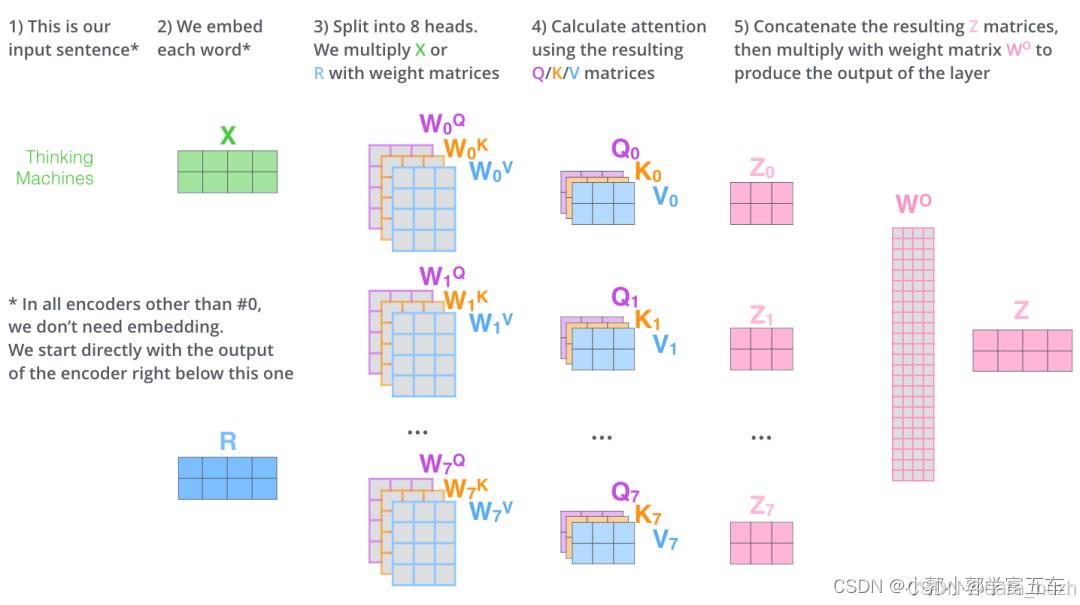
我在尝试实现多头注意力机制代码时,在网上发现了俩种对多头的解释,一种是(假设有8头)生成8份不同的Wq,Wk,Wv ,x与他们相乘后就有8份不同Q,K,V。再进过softmax,得到Z0,Z2,.....,Z7,把这些Z拼接起来变成一个大矩阵,再乘以Wo,把Z投影到原来维度。过程就如下图:
但是我在网上找多头注意力的代码时,发现在生成权重矩阵W时,并没有生成8份W,而是只生成了1份W。然后把W切分成立8份,代码如下图
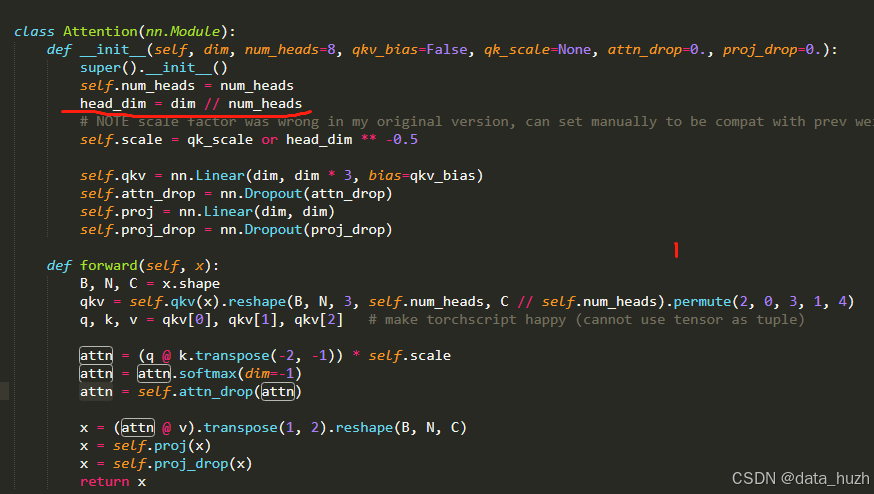
self.qkv=nn.Linear(dim,dim*3,bias=qkv_bais)
这里只生成了一份qkv,q=>(dim,dim)
后来我查资料发现,为了简化矩阵运算,实际上Wq=>(dim,dim=8*c1),
x=>(N,dim)乘以Wq==>(dim,dim=8*c1)
Q=>(N,dim=8*c1)
这里的Q实际就是8份,只不过合并成了一个矩阵,这样可以让在计算量不减的情况下,运行速度跟1个头的运行速度接近。

















 8545
8545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









