



1 引言
人口的快速老龄化以及住院医疗成本的急剧上升,使得人们认识到高效医疗系统(Nia 等人,2015年)的重要性,并推动了医疗保健、数据分析、无线通信、嵌入式系统和信息安全交叉领域的多项新兴研究方向。植入式和可穿戴医疗设备(IWMDs)能够实现无创预防、早期诊断以及对健康状况的持续治疗,被视为现代医疗的关键组成部分(Ghayvat 等人,2015年;Mukhopadhyay,2015年;Mosenia 等人,2017b)。在过去十年中,IWMDs 的计算能力、能量容量和网络功能显著提升,同时其尺寸大幅缩小。这些技术进步已将日常医疗系统从遥远的愿景推向现实的边缘。此外,物联网(IoT)的兴起以及新型计算/网络范式(如云计算和雾计算)的引入,使得由多个异构传感和计算设备组成的系统成为可能,从而彻底改变了传统医疗系统,并提供了新的机遇。
用基于互联网连接的IWMD系统替代医院内的医疗系统,从而 ushering us into the dawn of a new era of smart healthcare。
智能医疗并没有一个统一的定义。然而,我们对智能医疗的广义理解是,除了临床应用外,它还利用IWMDs在日常活动期间收集、存储和处理各种类型的生理数据。智能医疗系统可能依赖无线连接以利用外部资源,例如附近设备或云上的计算/存储资源,或向临床医生报告患者的健康状况。因此,智能医疗提供了一种主动的方法,用于疾病的早期检测甚至预防。它甚至使医生和临床医生能够在家庭环境中协助患者,通过众多互联网连接的医疗系统实现持续监测。这减少了机构化护理和住院治疗的需求,尤其有利于残疾人和老年人。同时,它还有望显著降低医疗成本,并提升患者的生活质量。
自从1958年首个植入式无线医疗设备(即植入式起搏器)问世以来,多种类型的IWMDs已被开发并推向市场,范围从汗液分析设备(Gao etal., 2016)到互联网连接的多传感器连续长期健康监测系统(Niaet al.,2015; Pantelopoulos and Bourbakis, 2010)。然而,尽管关于基于IWMDs和临床医疗系统的文献十分丰富(参见( Pantelopoulos and Bourbakis,2010)、(Mosenia et al.,2017b)以及(Musen et al., 2014)中的全面综述),但与智能医疗系统的设计与实现相关的基本挑战尚未得到充分解决。本文的主要目标是界定智能医疗的范围,并研究最先进的智能医疗系统、其组成部件、设计考虑因素,以及现有研究如何应对这些挑战。具体而言,我们做了以下工作。
我们提出了一种用于智能医疗的新型框架,旨在支持住院患者和门诊患者的健康监测,并讨论和比较临床与日常医疗。
•我们描述了几种新兴智能医疗系统,包括IBM沃森(高, 2012年)、 Open mHealth (埃斯特林和西姆,2010)、健康决策支持系统( HDSS)(尹和贾, 2017年)、压力检测与缓解系统(SoDA)(阿克曼多尔和贾,2017年),以及一种用于长期连续监测患者健康状况的节能系统(尼亚等人.,2015年)。
我们讨论了在设计智能医疗系统时应考虑的若干因素和挑战。
我们描述了五种研究趋势,以应对这些设计考虑,包括采用紧凑型深度神经网络和压缩感知技术来大幅降低计算能耗和存储需求,以及使用MedMon、OpSecure和SecureVibe来增强医疗保健系统的安全。
最后,我们讨论了几个未来研究方向,包括获取用于医疗数据集和机器学习模型的需求、标准化和基础设施,以及雾计算在智能医疗中可能发挥的积极作用。
本文其余部分组织如下。在第2章中,我们提出一个智能医疗框架,以推动从临床到日常医疗的扩展。在第3章中,我们分析五个作为智能医疗推动者的新兴系统。在第4章中,我们讨论这些系统相关的设计考虑因素与挑战,包括效率、安全、准确性、成本、响应性、可维护性、可扩展性、可靠性和容错性。在第5章中,我们描述五个应对其中部分挑战的新兴研究趋势。在第6章中,我们探讨开放问题和未来研究方向。最后,我们在第7章中进行总结。
2 什么是智能医疗?
现代医疗挽救了人类生命并提高了生活质量。过去二十年中,平均预期寿命增加了五年(Salomon et al.,2013年)。医疗保健对全球数十亿人产生的广泛影响,推动了巨大的跨学科研究努力和显著的创新。
然而几十年来,医疗保健一直局限于诊所/医院,未能利用从日常生活中获取的患者数据,从而错失了在疾病早期阶段进行干预的机会。
近年来,随着植入式无线医疗设备(IWMDs)带来的日常医疗的进步,即通过可穿戴医疗传感器(WMSs)和植入式医疗设备(IMDs),这些不足开始得到解决。日常医疗监测与传统临床医疗相结合,有望 usher in a new era of smart healthcare。
在本章中,我们提出了一种新颖的智能医疗框架,以捕捉从临床到日常医疗的快速扩展。该框架定义了智能医疗的范围,有助于将各种分散的医疗任务统一到一个整体之下。
2.1 智能医疗框架
根据医疗保健发生的场所,智能医疗可分为两个主要部分:(i)左侧图2.1所示的日常医疗,以及(ii)右侧图2.1所示的临床医疗。这两个部分由临床边界分隔。
图2.1的上半部分总结了智能医疗需要完成的五项主要任务:
疾病预防:(i)日常预防
•疾病诊断:(ii) 日常和 (iii) 临床诊断 疾病治疗:(iv)临床和(v)日常治疗 这五个任务属于三大类别,对应现代医疗保健面临的三个最关键的挑战:疾病的预防、诊断和治疗。每个任务构成一个活跃的研究领域,包含健康追踪、日常疾病诊断、医生差异减少、治疗方案选择和精准医学等具有挑战性的研究课题(如图2.1中项目符号所示)。这五个任务需要按照图2.1中箭头所示的顺序以循环方式进行。这一有向循环被称为智能医疗循环。
当医疗保健系统具备决策能力时,我们称其为“智能”医疗保健系统。这种能力由数据分析实现,如图2.1的下半部分所示。信息提炼始于各种有助于决策的相关数据类型,这些数据类型包括日常生活环境中的生理和环境读数,以及医院/诊所中的医生观察和实验室检测结果。这些数据必须被高效地采集、处理,并通过机器学习引擎(例如 WEKA(Hall 等人,2009年)和 TensorFlow(Abadi 等人,2016年))的安全辅助传输至医疗保健系统的上层,以提取健康推断。这些健康推断构成了循环中任务的重要组成部分。

接下来,我们将聚焦于临床医疗,然后是日常医疗,并详细讨论这两方面。
2.2 临床医疗
尽管过去几十年取得了显著进展,但美国的临床医疗系统仍远未达到最佳状态。例如,最近的一项研究(Makary和Daniel,2016年)显示,2013年可预防的医疗差错(PMEs)导致了超过25.1万人死亡,使其成为美国医院中心脏病和癌症之后的第三大死因。这一数字远高于1999年IOM报告(Kohn等,2000年)中提到的因可预防的医疗错误造成的9.8万人死亡。
计算机化信息系统,例如临床决策支持系统(CDSSs)和电子健康记录(EHRs),可为医生和医疗服务提供者提供智能筛选的临床建议,从而显著提高临床医疗的质量。已有超过66%基于电子健康记录的临床决策支持系统被证明从长远来看能显著改善临床实践( Huntet al.,1998)。因此,越来越多的医院和诊所正在采用临床决策支持系统和电子健康记录来辅助医生。这一趋势得益于2009年经济和临床卫生信息技术法案的推动,该法案配套了270亿美元的联邦拨款。
患者特异性临床数据量的急剧增加为机器学习算法提供了丰富的资源,以进行医疗推断。机器学习领域的快速算法进步甚至实现了超越人类的临床决策表现。例如,一种深度卷积神经网络(CNN)在皮肤癌分类中的表现已达到21名董事会认证的放射科医生的同等水平(Esteva等,2017年)。CheXNet,一个121层的卷积神经网络( CNN),在肺炎检测与分析方面的表现超过了四名放射科医生的平均水平(Rajpurkar等,2017年)。深度患者(Miotto等,2016年)采用三层堆叠的自编码器来捕捉聚合的电子健康记录中的规律性和依赖性。
70万名患者。它使用提取的规则进行疾病风险预测,并在76,214名测试患者中对78种疾病实现了非常高的准确性。借助图形处理单元( GPU)上的大规模并行深度学习,DeepBind 分析数百万条基因组序列(此前为1万到10万),以识别致病性疾病的变异(Alipanahi 等, 2015年)。这加快了脱氧核糖核酸、细胞中的关键分子以及相关疾病风险之间关系的探索,从而助力精准医学的发展(Leung 等,2016年)。
然而,临床医疗仍然局限于医院/诊所,很难获取患者的日常健康状况,而大多数疾病实际上是在日常生活场景中发生和治疗的( Estrin 和 Sim,2010)。这可能导致诸多不足。例如,日常健康数据是医生和临床决策支持系统做出诊断决策时极为重要、有时甚至是唯一的依据。仅依赖患者自报的症状回忆可能非常容易出错,因为症状往往甚至无法被个体察觉。这些缺陷表明有必要在日常生活场景中对临床医疗进行补充。
2.3 日常医疗
与长达数十年的临床创新进步不同,日常医疗是一个新兴的研究领域。它需要一种稳定、持续、准确且对用户透明的数据采集机制。得益于低功耗传感器和信号处理技术的最新进展,这一目标才得以实现。
过去十年见证了植入式无线医疗设备、家庭/办公室/健身房中的固定传感器以及手机中嵌入式传感器的大量部署。这些传感器能够在日常生活环境持续不断地收集大量健康相关数据,以支持决策。这属于一种物联网范式,即设备之间相互通信与协作,广泛实现共同目标(Atzori 等,2010)。物联网框架包含三个层次化计算层:传感器、边缘和云。在医疗保健背景下,物联网的三个层次依次将健康相关数据(如生理信号和环境读数)转化为有意义的医疗推断,例如疾病诊断和活动预测,从而为日常医疗带来智能化。由于需要支持数十亿设备,当前的物联网框架面临传感器能量预算有限、通信带宽受限、服务器存储容量有限以及恶意攻击者攻击面广泛等问题(李等人,2011年; Halperinetal.,2008年;尹等人,2015年)。这些不足导致了显著的设计挑战,例如对效率和安全的需求。我们将在第4章讨论这些设计考虑,并在第5章介绍应对这些挑战的技术。
迄今为止,已采用两种主要方法来在物联网层级中获取医疗推断:
•一种来自云的自上而下方法:该方法从云计算出发,获得群体级推断并提取通用规则。这种方法需要处理的数据量很大,通常为太字节(1012 B)或更多。因此,该方法在数据收集、存储和预处理方面的分析成本较高。IBM Watson1采用了这种方法,详见第 3 章。
•一种来自传感器/边缘的自下而上方法:该方法从用户端开始,获取个性化推理结果。它通常汇集并分析相对较小患者群体的数据,从而实现细粒度分析,有助于构建更准确的个性化模型。需要分析的数据量通常在兆字节(106 B)到千兆字节(109 B)范围内,因此远小于自上而下方法。因此,它降低了机器学习模型生成的相关成本。采用此方法的示例包括Open mHealth(Estrin andSim, 2010)、HDSS(尹和贾, 2017年)和SoDA(阿克曼多尔和贾, 2017年),这些将在第3章中详细说明。
1IBM Watson, https://www.ibm.com/watson。
然而,这两种方法都尚未成熟。自上而下方法生成的广义群体级模型可能无法适应个体患者的个人特征,因而难以满足个性化需求。这也是个性化诊断与精准医学领域所面临的一个基本研究问题。另一方面,自下而上方法生成的个性化模型受限于单个患者群体的数据分析,可能无法得出适用于群体层面的通用规则。这可能导致推理模型在该群体内部表现良好,但无法推广到其他群体,因为其特征可能并非来自相同的概率分布。
为了解决上述问题,我们提出了一种用于智能医疗的潜在推理模型,该模型由广义模型和个性化模型共同组成。我们将其称为混合推理模型,如图2.2所示。元学习器函数 H(·) 接收来自广义函数 G(·) 和 个性化函数 I(·) 的输入作为其基础学习器。这能够有效:
•根据个人的生理特征,为每个人调整通用模型,
•通过添加更多真实情况和更大的知识库来增强个性化模型。
3 新兴智能医疗系统
普适医疗对于提升人类福祉至关重要。现代医疗系统已基于数据分析领域的空前进步而变得智能化,并因物联网的快速部署而日益普及。
在本章中,我们回顾了智能医疗领域中的多个系统,包括:(i) IBM Watson,该系统从医学文献中提取规则以回答健康相关问题(高,2012年);(ii)Open mHealth,旨在基于手机应用程序收集的数据进行日常慢性病预防(Estrin和Sim,2010);(iii)健康决策支持系统(HDSS),利用可穿戴监测系统(WMSs)和机器学习集成实现疾病诊断(尹和贾,2017年);(iv)SoDA,专注于通过整合工作记忆样本数据与机器学习算法实现连续压力检测与缓解(阿克曼多尔和贾,2017年);以及(v)一种节能系统,用于长期连续监测患者病情(Nia等,2015年)。
3.1 IBM Watson
IBM Watson 是一种认知系统,结合了深度自然语言处理(NLP)、假设生成和动态学习,以生成基于置信度的响应(高, 2012年)。它能够从海量非结构化和嘈杂数据中提取信息:科学论文、教科书、用户手册、指南、常见问题、计划、实验室笔记、新闻以及专有数据。提取出的知识库存储为沃森语料库。沃森为每个目标领域生成唯一的语料库。由于其强大的自然语言处理能力,沃森已应用于广泛的领域,如工程、医学、法律和金融(Chen 等,2016年)。
沃森使用其语料库进行问答式推理。当提出一个新问题时,它会 (i)提取问题的主要特征,(ii)通过语料库生成的数百个假设获取候选答案,(iii)利用推理算法比较这些答案,然后(iv)选择置信度得分最高的答案。这种自上而下方法,即从阅读目标领域中所有可用信息开始,虽然取得了惊人的成果,但成本非常高。例如,IBM Watson在2011年的危险边缘知识竞赛中战胜了人类冠军。为此,它预先阅读了大约2亿页的内容以构建其语料库。在比赛中,它依赖于90台 IBM Power750处理器和16TB内存(Chandrasekar, 2014)。
在医疗保健领域,沃森的超越人类的内容阅读能力使其能够在日常和临床场景中回答健康相关问题。它可以扫描和分析来自各种医疗资源的内容:科学期刊、专利、药物和疾病相关本体、临床试验、电子健康记录、实验室和影像数据、基因组数据、理赔数据以及网络社交内容(Chen 等,2016年)。这促成了沃森在医疗保健中的三大主要应用程序:
•肿瘤学:沃森可以将患者档案与相关的临床试验/记录进行比较,以评估和排序癌症治疗方案。这减少了查阅文献所需的时间成本。
以及电子健康记录。例如,沃森仅用10分钟就为一名76岁的脑瘤患者确定了治疗方案,而人类专家完成这一过程大约需要160小时(Wrzeszczynskiet al.,2017年)。
•药物发现:沃森可以识别新的药物靶点以及现有药物的新用途。例如,它成功地从一家制药公司提供的药物候选池中识别出15种针对疟原虫的新型药物候选物(Chen et al.,2016年)。为此,它首先查阅了文献,确定了在抑制疟原虫方面已被证明有效的相关药物,然后通过化学结构和作用机制的相似性评估了候选药物。
基因组学:沃森能够揭示基因、蛋白质、药物和疾病之间新的关联与关系。它还可以对患者肿瘤中脱氧核糖核酸的最可能驱动突变及其变异类型进行排序和预测,从而增强个性化治疗,为医生提供更多治疗选择。
3.2 Open mHealth
开放移动健康(移动健康)项目旨在基于从手机和设备中的医疗保健应用程序收集的数据,实现日常慢性病预防与管理(Estrin 和 Sim, 2010)。到 2012 年,苹果iPhone 上已有超过 13,000 个与健康相关的应用程序(Localystics,2012年)。这些应用程序使患者能够每天电子化记录和追踪其重要的生理体征,从而实现令人满意的以用户为中心的成果。例如,威尔多克是一款基于手机的糖尿病管理应用程序,通过消息和提示来追踪用户的血糖水平(Quinn 等,2011年)。一项随机对照试验发现,使用威尔多克可显著降低用户的糖化血红蛋白水平,并使临床就诊和急诊护理使用率减少 20%(Quinn 等,2011年)。
Open mHealth 旨在标准化部署在手机上的分散式移动健康应用程序。它提出了开放的应用程序。
3.3 HDSS:健康决策支持系统
围绕一组最小化的通用通信协议构建的编程接口(应用程序编程接口) (Estrin 和 Sim,2010;Chen 等人,2012年)。这使得数据和应用程序模块能够在不同设备、不同操作系统以及多种慢性疾病之间共享。
InfoVis 是 Open mHealth 项目中开发的第一个标准数据可视化工具(Chen 等,2012年)。它接收来自底层乐高式可重用软件模块的数据输入:数据处理单元(DPUs)和数据可视化单元(DVUs)。每个 DPU 和 DVU 执行一项通用任务。多个 DPUs 和 DVUs 协同工作,以提供应用程序级别的功能。
Chen 等人开发了用于移动健康应用程序“创伤后应激障碍( PTSD)探索者”的数据处理单元和数据可视化单元,该应用程序可帮助 PTSD 患者管理急性痛苦症状(Chen et al.,2012年)。由于与之相关的污名、后勤障碍以及难以察觉的症状,这类患者很少寻求面对面咨询,因此移动应用程序可以为 PTSD 患者提供独特的标准护理(Hogeet al.,2004年)。数据处理单元和数据可视化单元能够直接可视化患者自报的 PTSD 检查清单评分和血糖水平(Chenetal.,2012年)。基于共享的应用程序编程接口的开放架构,这些 PTSD 数据处理单元和数据可视化单元也可用于其他应用程序,例如对患者自报的慢性疼痛测量结果进行可视化(Chenet al.,2012年)。
3.3 HDSS:健康决策支持系统
健康决策支持系统(HDSS)通过整合无线医疗传感器数据与临床决策支持系统(尹和贾,2017年),实现在诊所内外的疾病诊断。HDSS 具有多层结构,起始于无线医疗传感器层,并依托强大的机器学习技术,使疾病诊断模块能够单独追踪各种疾病。该系统依次构建了日常健康监测、初步临床检查、详细临床检查以及诊断后决策支持的信息框架。
HDSS 包含两个主要部分,以支持日常和临床医疗保健:(i)普适决策支持系统(PHDS),如图 3.1左侧所示;(ii)PHDS 辅助的临床决策支持系统(CDSS+),如图 3.1右侧所示。PHDS 对工作记忆样本数据进行处理,用于日常疾病诊断。CDSS+则负责临床诊断。HDSS 包含四个主要层级。第一层协助日常健康监测。第一层中的决策模块使用临床领域知识进行训练。这可将医生的专业知识跨越临床边界进行传输,从而帮助无专业医疗培训的个体有效追踪其疾病状况。
当第一层发出警报时,会将症状记录作为疾病发作记录跨过临床边界传递。第二层基于基本临床测量为 incoming 患者提供即时决策支持。第三层基于详细的实验室检测进行更详细的诊断分析。最后,第四层级提供诊断后的治疗、处方和生活方式建议。较高级别的层级比低级别的层级收集更多信息,但伴随更高的时间和能量成本。HDSS 按照四个层级以顺序和闭环方式运行,如图 3.1中四个层级后方的大箭头所示。
健康决策支持系统部署了各种转换流程(T),以促进各层级之间的信息流动,如图 3.1 中带索引的箭头所示。当第一层触发警报时,转换流程 TIN将疾病发作记录传递过临床边界。在第二层,健康决策支持系统将数据与医生的额外见解进行整合,然后通过 T1 将数据传递给诊断引擎。诊断引擎包含可供机器学习引擎访问的库,例如 WEKA(Hall 等人,2009年)和 TensorFlow(Abadi 等人,2016 年)。如果诊断需要进一步的实验室检测,则通过 T2将健康决策支持系统转移到第三层。否则,通过 T2′将健康决策支持系统转移到第四层级。无论哪种情况,诊断建议都会立即提供给医生。当 T2发生时,第三层通过 T3连接到诊断引擎。引擎通过 T4下达适当的实验室检测指令,之后检测结果通过 T5反馈回诊断引擎。第三层的诊断相比第二层消耗更多的时间和费用。例如,获取一份血液检测报告可能需要 12‐16 小时(对于计算机断层扫描等检测则可能需要更长时间)。
 and PHDS-assisted Clinical Decision Support System(CDSS+). Transition i, disease diagnosis modules, disease-onset record, and machine learning algorithm are denoted by Ti, DDM, DOR, and MLA, respectively(Yin and Jha, 2017))
and PHDS-assisted Clinical Decision Support System(CDSS+). Transition i, disease diagnosis modules, disease-onset record, and machine learning algorithm are denoted by Ti, DDM, DOR, and MLA, respectively(Yin and Jha, 2017))
健康决策支持系统依靠疾病诊断模块进行疾病监测。每个此类模块为特定目标疾病的诊断指定了唯一且必要的信息框架组件。因此,只需修改目标疾病的疾病诊断模块即可更新或评估诊断规则,而无需重构整个健康决策支持系统。多种疾病诊断模块并行推导疾病特征,以同时监测多种疾病。为了区分不同疾病,健康决策支持系统采用国际疾病及相关健康问题统计分类(ICD)编码系统对疾病诊断模块进行索引。ICD代码由世界卫生组织维护。其最新版本ICD‐10包含两个编码子系统:用于疾病分类的ICD‐10‐CM和用于住院患者手术识别的 ICD‐10‐PCS。健康决策支持系统使用ICD‐10‐CM进行疾病索引。目前, ICD‐10‐CM包含分配至20个疾病类别的69,000个人类疾病代码( Quan et al., 2005)。
尹和贾通过基于加利福尼亚大学欧文分校(UCI)数据集( Lichman,2013;Czerniak 和 Zarzycki,2003)生成心律失常、2型糖尿病、乳腺癌、膀胱功能障碍、肾盂源性肾炎和甲状腺功能减退症的疾病诊断模块,证明了通过健康决策支持系统(HDSS)进行疾病诊断的可行性。他们实验了八种监督式机器学习算法和六种集成方法用于疾病诊断模块训练。表3.1总结了这些方法的名称、缩写及其简要描述。集成方法规定了元学习器如何根据其基础学习器的预测结果做出最终决策。通常,集成方法可提升机器学习算法性能。
疾病诊断模块性能总结在表3.2中。以类型索引的行列出了达到最高诊断准确率的机器学习模型。以
表3.1: 机器学习算法和集成方法(尹和贾, 2017年)
| Name | 缩写 | 描述 |
|---|---|---|
| 朴素贝叶斯 | NB | 基于贝叶斯定理的概率学习器 |
| 贝叶斯网络 | BN | 网络驱动,节点上的条件表 |
| k‐nearest neighbor | IB-k | k最近实例的相似性分析 |
| 最佳优先决策树 | BFTree | 基于特征二元分割的树 |
| J48 | J48 | 剪枝或未剪枝的决策树 |
| 决策表 | DT | 基于决策表的多数学习器 |
| 支持向量机 | SVM | 基于支持向量的线性分隔器 |
| 多层感知机 | MLP | 基于反向传播的神经网络 |
| 堆叠器 | ST | 基于组合器的基础学习器堆叠 |
| AdaBoost(提升器) | ADA | 弱分类器的加权决策 |
| DECORATE(投票器) | DEC | 通过多样化的基础学习器进行投票 |
| 装袋器 | BAG | 使用采样子集进行训练 |
| 随机树 | RT | 基于树采样特征的袋装法 |
| 随机森林 | RF | 基于树采样实例/特征的袋装法 |
表3.2: 健康决策支持系统在UCI生物医学数据集上的性能总结(尹和贾,2017年)
| 疾病 → | DDM ↓ | 心律失常 | 糖尿病 2型 | 乳腺癌 | 泌尿 膀胱 紊乱 | 肾盂 起源 肾炎 | 甲状腺功能减退 |
|---|---|---|---|---|---|---|---|
| ICD‐10‐CM | I49.9 | E11‐* | C50‐* | N32.0 | N12 | E03.9 | |
| 第一层 | Type | RF+F | NB+F | – | RT | NB | RF |
| Obj. | B | B | – | B | B | B | |
| ACC | 85.9% | 77.6% | – | 99.6% | 93.7% | 94.8% | |
| 第二层 | Type | BAG(BN)+F | NB+F | – | RF+F | RT | ADA(BFTree) |
| Obj. | M-16 | B | – | B | B | B | |
| ACC | 77.4% | 77.6% | – | 100% (100% 3 ) | 99.9% (100% 3 ) | 94.8% | |
| 第三层 | Type | 袋装法(BN)+F | DEC(BN) | 袋装法(BN)+F | – | – | J48+F |
| Obj. | M-16 | B | B | – | – | B | |
| ACC | 77.4% (78.9%1 ) | 78.9% (76.5%2 ) | 97.0% (95.5%2 ) | – | – | 99.3% |
+F:特征滤波;DDM:疾病诊断模块; 1:(Jadhav 等,2011年); 2:(Cao 等,2016年); 3:(Arif 和 Basalamah,2012年)。机器学习算法的缩写汇总见表3.1。
目标列出了从第一层的二分类(B)到第二层和第三层的 k类多分类 (M‐k)的性能目标。以ACC为索引的行汇总了相应诊断层级的最高诊断准确率。这些
C00‐D48 肿瘤 乳腺癌 E00‐E90内分泌、营养和代谢 疾病 2型糖尿病 甲状腺功能减退 I00‐I99循环系统疾病 心律失常 N00‐N99泌尿生殖系统疾病 膀胱功能障碍 肾盂源性肾炎 A00‐B99某些传染病和寄生虫病 疟疾 G00‐G99 神经系统疾病 癫痫发作 睡眠呼吸暂停 帕金森 J00‐J99 呼吸系统疾病 呼吸系统病理学 L00‐L99皮肤和皮下组织疾病 色素性皮肤损害 P00‐P96围生期起源的某些情况 时期 产前和围生期保健 D50‐D89血液和造血器官疾病以及涉及免疫机制的某些疾患 涉及免疫机制 F00‐F99 精神和行为障碍 H00‐H59 眼和附属器疾病 H60‐H95 耳和乳突疾病 K00‐K93 消化系统疾病 M00‐M99 肌肉骨骼系统疾病 O00‐O99 妊娠、分娩和产褥期 Q00‐Q99先天性畸形、变形和染色体异常 R00‐R99症状、体征以及未在其他地方分类的临床和实验室异常发现,未 elsewhereclassified S00‐T98损伤、中毒及外部因素造成的某些其他后果 V01‐Y98 发病和死亡的外部原因 Z00‐Z99影响健康状况及与卫生服务接触的因素
ICD‐10‐CM 类别 for 69,000种疾病 由[尹和贾2017]研究 相关研究 开放的研究机会

数值可与文献中的相关研究(Suryakumar 等,2013;Cao 等, 2016; Arif 和 Basalamah,2012; Jadhav 等, 2011)相媲美甚至更优。值得注意的是,健康决策支持系统(HDSS)即使在第一层(Tier‐1),也能获得较高的诊断准确率,而该层级的数据仅能从可穿戴监测系统(WMSs)中收集。
为了评估健康决策支持系统(HDSS)的可扩展性,尹和贾对过去十年内尚未公开生物医学数据集的疾病进行了文献综述。他们讨论了七项代表性研究,这些研究验证了机器学习在疟疾(Das 等,2013)、睡眠呼吸暂停(Khandoker 等, 2009)、帕金森病(Tahir 和 Manap, 2012)、呼吸功能障碍(Palaniappan 等, 2014)、癫痫发作(Tzallas 等, 2009)、皮肤病变(Korotkov 和 Garcia, 2012)以及产前/围产期缺陷(Cerqueira 等, 2014)的诊断和治疗中的适用性。
图 3.2总结了当前HDSS在ICD‐10‐CM类别中的覆盖范围。该图包含三个主要部分。最浅的部分包括表3.2中疾病诊断模块所涵盖的四个ICD‐10‐CM类别。浅灰色部分突出显示了至少有一个经验证的机器学习模型但基于私有数据集的类别,一旦这些数据集公开,HDSS也可应用于这些类别。最后,深灰色部分列出了生物医学数据集和机器学习模型较为稀少的开放类别,这为进一步拓展HDSS的应用范围提供了机会。
3.4 SoDA:压力检测与缓解系统
压力与多种健康问题相关,从心血管疾病(Schubert 等人,2009年)到睡眠障碍(McEwen,2004年)和癌症(Irie 等人,2001年)。降低这些严重健康问题的风险需要将压力控制在合理范围内。阿克曼多尔和贾提出了一种名为SoDA的系统来解决这一问题(Akmandor 和 Jha,2017年)。
SoDA 是一个自动压力检测与缓解系统,通过可穿戴监测系统收集生理信号,并对这些信号进行机器学习推理。其主要组件如图 3.3 所示。它利用机器学习推理实现持续的、面向用户和情境的压力水平追踪(绿色路径)和辅导(红色路径)。
SoDA 中操作的详细流程如图3.4所示。第一步,SoDA 从可穿戴监测系统收集生理数据。然后对收集到的数据进行处理,以去除伪影,即异常值,

基线漂移、电源线干扰和肌电噪声,并提取信息特征。将特征值输入预先训练的机器学习模型(图3.4中的分类模块)后,SoDA判断当前时段对应的是“应激状态”还是“非应激状态”。如果判断为“非应激状态”,SoDA将跳过压力缓解协议,并执行图3.4中的上路径操作。然而,如果判断为“应激状态”,SoDA将通过图3.4中的下路径激活压力缓解协议。利用算法1中概述的压力缓解协议,SoDA引导用户进行减压疗法,并分析从采集的生理数据中提取的特征值。根据特征值的趋势,SoDA或终止压力缓解协议,或在同一或下一个减压疗法下继续执行预定义时间段。
 )
)
3.4 SoDA:压力检测与缓解系统
算法1 减压协议(阿克曼多尔和贾,2017年) 给定: 疗法集合,减压技术的集合。
1: therapy← null, k← 0, flag← 0
2:对于 i= 1,…, length(therapySet)
3: therapy←疗法集合(i)
4: Delay(30sec.)
5: Compute selected N feature values
6: Compute k, number of features showing stress relief
7: if k ≥N/2
8: Delay(30sec.)
9: Compute selected N feature values
10: Compute k
11: if k ≥N/2
12: flag← 1
13: 返回
14: end
15: end
16:结束
17: 如果 flag= 0, none of the stress alleviation techniques is effective
18: Give warning to the user
19:返回
20:结束
SoDA 具有两种操作模式:“广义”和“个性化”。在“广义” 模式中,机器学习模型是通过来自大量个体的 WMS 数据获得的,因此“广义”模型可以立即使用。另一方面,“个性化”模型仅基于特定个体的 WMS 数据获得。由于模型参数会根据特定用户的数据进行调整,“个性化”模型需要额外的训练时间。然而,它在压力追踪和辅导过程中提供更高的分类准确率。
阿克曼多尔和贾使用以下可穿戴监测系统进行压力检测与缓解:心电图(ECG)、皮肤电反应(GSR)、呼吸频率(RESP)、血压(BP)和血液
表3.3: 选定的特征集(阿克曼多尔和贾,2017年)
| 特征 | 传感器集 |
|---|---|
| 1由ECG推导的呼吸率 | ECG I, II |
| 2皮肤电导幅度均值 | GSR I, II |
| 3皮肤电导的标准差 幅度 | GSR I, II |
| 4皮肤电导幅度之和 超过阈值的响应(连续) 分解分析) | GSR I |
| 5紧张性活动的平均值 | GSR I |
| 6最大正向偏转 | GSR I |
| 7呼吸持续时间均值 | RESP I |
| 8呼吸信号均方根 呼吸信号 I, II | RESP I, II |
| 9呼吸持续时间中位数 | RESP I |
| 10血氧水平均值 | BO I, II |
| 11收缩压均值 | BP I, II |
| 12收缩压变异度 | BP I, II |
| 13舒张压均值 | BP I, II |
| 14平均动脉压均值 | BP I, II |
| 15平均动脉压变异度 | BP I, II |
血氧仪(BO)。数据来自32名参与者,包括总共八个诱发压力的时段: 其中四个伴有减压疗法,四个不伴有减压疗法。收集到的工作记忆样本数据经过伪迹去除、特征提取、特征选择和主成分分析(PCA)处理。最终的特征向量作为输入提供给机器学习模型进行决策。因此,压力推断以对用户透明的方式完成。
在数据处理和特征提取之后,对两个特征集的压力检测性能进行了分析(见表3.3)。SoDA 使用k‐最近邻(k‐NN)和支持向量机( SVM)径向基函数(RBF)作为分类器。“个性化”模型在两个特征集上的平均压力分类准确率如下(见图3.5(a)和图3.5(b)): 94.5‐95.8%,93.7‐94.7%,93.8‐94.8%,
 I、(b) II 和 (c) 箱线图参数定义的压力检测准确性统计(Akmandor 和 Jha, 2017))
I、(b) II 和 (c) 箱线图参数定义的压力检测准确性统计(Akmandor 和 Jha, 2017))
94.2‐94.5% 和 86.7‐83.2%,分别对应 k‐NN (k= 1)、 k‐NN (k= 2)、 k‐NN (k= 3)、 k‐NN (k= 4) 和 SVM RBF 分类器。在压力缓解阶段的分析中,阿克曼多尔和贾比较了进行压力治疗与未进行压力治疗时的特征值,发现治疗显著改善了压力水平。
总之,SoDA 是一种自动且用户友好的压力水平指导系统,可持续追踪生理信号以检测压力,并在需要时引导用户。由于其高压力检测准确率和高效的压力缓解能力,SoDA 是用于预防和治疗压力及相关健康问题的一项有前景的技术。
3.5 节能型健康监测系统
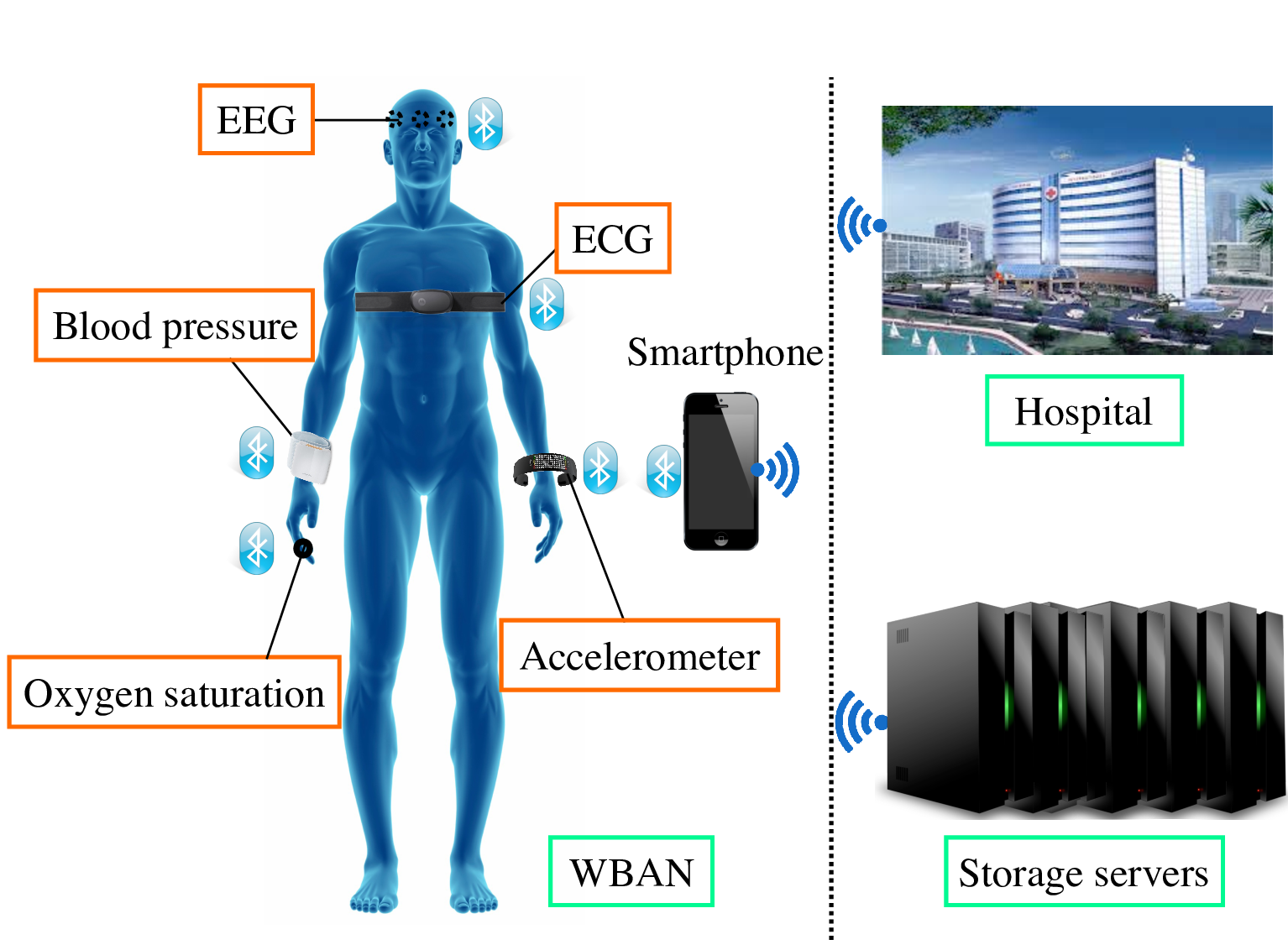
传统医疗监护仪,例如床边心电图和血氧饱和度监测系统,在数据采集、存储和传输过程中不进行(或仅进行极少)设备端处理。此外,这类系统通常由电源插座供电,而先进的植入式/可穿戴医疗设备则依赖能量受限的电池。近年来在信号处理、低功耗电子技术、通信协议,特别是低功率射频传输模块设计方面的进展,使得即使是最受能量限制的医疗设备也能实现无线连接,从而构成无线体域网(WBAN) (Ullah et al.,2012;Ko et al., 2010)。基于WBAN的连续健康监测系统依赖于一组医疗传感器网络,能够采集、处理和存储多种类型的生理数据,为疾病预防与早期检测提供整体性方法。事实上,近年来连续健康监测系统受到越来越多的关注,被视为智能医疗系统的基本组成部分。
此类系统在设计和开发过程中存在若干关键挑战。为了最大程度地提高系统接受度和用户便利性,植入式无线医疗设备必须体积小且为被动式,即以最少用户参与来收集生理数据。这些要求对每个传感器的存储和电池容量施加了显著限制。Nia 等人(2015年)

全面检查连续个人健康监测系统的能量和存储需求。为了实现节能型连续健康监测,他们首先对植入式无线医疗设备进行了详尽的文献综述,总结了其常见的分辨率、采样率和传输率,并分析了一个由八个传感器组成的健康监测系统,该系统持续采集并传输原始生理数据至基站以进行进一步处理(图3.6)。表3.4总结了各种传感器的分辨率、采样率和最大无线数据传输率。
尼亚 等人 (2015年)开发了多个分析模型,以描述此类系统,并突显出长期连续监测的存储/能源需求与现有健康监测系统中使用的植入式无线医疗设备的能力之间存在显著差距。为了降低每个传感器的能耗,他们
表3.4: 分辨率、采样率和最大传输速率(尼亚 等,2015年)
| 传感器 | 分辨率(位/样本) | 采样速率 (赫兹) | 传输速率 (位/秒) |
|---|---|---|---|
| 心率 | 10 | 2-8 | 80 |
| 血压 | 16 | 0.001‐100 | 1600 |
| 氧饱和度 | 8 | 0.001‐2 | 16 |
| 温度 | 8 | 0.001‐1 | 8 |
| 血糖 | 16 | 0.001‐100 | 1600 |
| 加速度计 | 12 | 2‐400 | 4800 |
| ECG | 12 | 100‐1000 | 12000 |
| EEG | 12 | 100‐1000 | 12000 |
表3.5: 不同方案的比较(尼亚 等, 2015年)
| 方案 | 能量 | 存储 | 延迟 | 可扩展性 |
|---|---|---|---|---|
| 基线 | 非常高 | High | Low | High |
| 聚合 | 非常高 | High | 可变 | High |
| 异常驱动 | Low | Low | Low | Low |
| 基于压缩感知 | 非常低 | Low | Low | Low |
分析三种轻量级传感器上计算技术,即样本聚合、异常驱动传输和压缩感知(CS)。
表 3.5总结了(Nia et al.,2015年)中讨论的所有方案的关键特征。他们将自己的提议方案与基线场景进行比较,在该基线场景中,所有传感器持续收集数据并将其传输到基站,且不进行任何传感器上计算。如(Nia etal.,2015年)所述,除了传感器的存储和电池容量外,延迟和可扩展性要求也是为每个传感器选择合适的计算/传输方法时需要考虑的关键因素。接下来,我们将更详细地描述这两个要求。
延迟: 在(Nia et al.,2015年)中,延迟被定义为显著事件(例如, 异常)发生到医疗设备或医生做出响应之间的时间间隔。可容忍延迟在很大程度上取决于传感器的应用以及患者状况。例如,用于监测健康个体的健康监测系统可以通过长时间间隔(例如,每天一次)收集并将医疗信息发送给医生或医院,以提供常规体检,因此可以使用样本聚合。相比之下,用于监测有严重疾病史(例如高血糖)个体的监测系统应立即检测健康状况的任何变化(例如血糖快速升高),而不能使用样本聚合。
Extensibility:可扩展性是一个关键的设计要求,其实现需考虑未来修改。高可扩展性意味着生物医学传感器的应用程序未来可以在最小工作量下进行扩展。通常,不执行传感器上计算的方案更具可扩展性,因为它可以在不修改传感器的情况下进行更改。
要点: 在传感器上进行计算可以显著降低传感器的总能耗,例如,压缩感知技术可以在能量和存储方面实现高达三个数量级的提升。除了显著延长植入式无线医疗设备的电池寿命外,该方法还提供了另一个关键优势:设计人员可以利用节省的能量(Nia 等, 2015年)在植入式无线医疗设备上实现安全增强技术(特别是由于显著的能量开销而通常在植入式无线医疗设备中被避免的强加密方案)。
4 设计考虑因素
智能医疗系统日益增加的功能复杂性带来了固有的设计挑战:效率、安全、准确性、成本、响应性、可维护性、可扩展性、可靠性和容错性。由于智能医疗系统涉及人类生命安全,这些方面存在的任何不足都可能导致不良后果,从系统无法实用到威胁生命的状况(阿克曼多尔 和 贾, 2018)。在本章中,我们总结并解释智能医疗系统的关键设计考虑因素,以实现以下目标:(i) 明确现有系统可以改进之处; (ii) 为未来系统设计提供指导。关键设计考虑因素包括:
•效率: 智能医疗系统必须兼具节能且存储高效的特点。它们依赖于位于人体内外以及环境中的设备来采集用户的健康信息。如果系统频繁耗尽电池能量或需要外部能源,其实用性将受到负面影响。例如,在某些植入式医疗设备(如起搏器)中,电池更换需要进行手术,伴随一定风险(Halperin等, 2008年)。数据压缩技术 (例如,结合直接计算的压缩感知)
图4.1: 智能医疗系统设计考虑因素
(肖艾布等人, 2015, 2014),压缩信号处理(卢等人,2016)等方法在提高能效方面是有效的。压缩可减小数据大小,从而降低计算能耗需求。利用内在的传感器/边缘分组的物联网数据结构(例如,从一个WMS收集的数据在空间上与其他WMS收集的数据分离)的分层推理模型(HIM)也可以在不影响准确性的前提下提高效率。例如,尹等人表明,HIM可在八种针对七种物联网应用(包括压力监测、化学气体分类以及心脏病、肾盂疾病、膀胱功能障碍、甲状腺功能减退和2型糖尿病的诊断)推导出的推理模型上,将运行时系统传输负载降低3.2-60.0×倍,同时分类准确 性变化仅在 −0.4%-+6.7%范围内(尹等人, 2018)。此外,柔性电子器件为可穿戴物联网应用提供了能量收集潜力。如Jokic 和 Magno (2017) 所示,薄膜柔性光伏面板通过能量收集有望实现持续长期的健康监测。该技术可减少或消除电池更换或充电的需求。智能医疗系统还需要支持高效的内存利用。所收集的数据、信号处理所需的参数以及推理模型都需要大量存储空间。这可能会使推理变慢,并限制更多传感器/设备的集成。因此,需要仔细分析智能医疗系统的能耗和存储需求。
•安全: 智能医疗系统会从用户处提取敏感的健康信息。因此,此类系统的安全至关重要。然而,大多数智能医疗系统忽视了安全性。先前的研究已揭示了各种医疗设备存在的漏洞,例如胰岛素泵(李等人,2011年)、起搏器(Halperin 等人, 2008年)、生理侧信道(Nia 等人,2016年)等,这些设备均可能遭受安全攻击。这些攻击可能导致从隐私泄露到危及生命的后果。因此,智能医疗系统的设计应具备抵御潜在安全攻击的能力。
•准确性: 智能医疗系统之所以被称为“智能”,是因为其具备决策能力。这种能力源于推理。由于智能化能够实现疾病诊断、治疗决策、治疗持续时间确定以及发出警报(尹和贾,2017年;阿克曼多尔和贾,2017年),因此推理的准确性直接影响用户的健康。如果系统提供错误的警报、诊断或治疗建议,误导用户或医生,系统的可靠性将下降。这可能导致对系统的失去信心,从而导致停用。因此,准确性在智能医疗系统的使用率、质量和有效性中起着关键作用。
•成本: 随着成本降低,智能医疗系统在日常和治疗性医疗应用中的部署更加广泛。这有望减少对医院/诊所的依赖,提高健康状况的早期诊断能力,并使国家医疗成本呈下降趋势。因此,此类系统的成本方面需要在设计阶段进行全面分析。柔性混合电子(FHE)是实现这一目标的有前景的技术。FHE将柔性电子器件与硅技术相结合。它在制造成本和柔性基板方面受益于柔性技术,同时保留了传统硅技术的计算和存储优势(Guptaet al., 2017;Huang etal., 2015)。
•响应性: 智能化为医疗系统带来了增强的功能性,但同时也增加了计算和存储资源的成本。这可能会降低系统的响应性(即增加其延迟)。由于这些系统在必要时提供治疗、诊断、指导和警报,延迟的增加会对系统功能产生不利影响。如果系统无法及时提供所需的响应,那么为系统添加智能功能就变得不合理且具有劣势。因此,系统的响应性也需要进行仔细分析。
•可维护性: 智能医疗系统需要定期维护。这包括软件和硬件更新 (阿克曼多尔和贾,2018)。系统应能轻松适应这些更新,从而在发现小缺陷时无需丢弃整个系统。能量收集也对可维护性有积极影响。由于薄膜柔性光伏面板(乔基奇和马尼奥,2017年)不仅能应对能量效率挑战,还能提升可维护性,因此它们是可穿戴医疗系统的理想候选方案。
•可扩展性: 传感器技术的进步使得越来越多的传感器和设备能够集成到智能医疗保健系统中。这种增强的功能性拓宽了应用程序范围。因此,系统设计应预见到系统能力的未来扩展。
•可靠性与容错性: 智能医疗系统从各种来源收集数据。在数据收集、信号处理或数据传输过程中,由于系统的不同部分出现故障,可能会引入错误。可靠性表示系统抵御这些故障的能力。更高的可靠性使得智能医疗系统更有可能被采用。因此,在存在故障的情况下持续运行是非常理想的。这可以通过内置的容错性来确保。
5 创新与趋势
在本章中,我们阐述了五种创新的研究趋势,这些趋势可能有助于解决智能医疗系统的设计考虑因素。我们首先介绍两种能够显著提高能效和存储效率的方法:(i)第5.1节中的紧凑型深度神经网络;(ii) 第5.2节中的压缩感知。然后,我们介绍三种应对安全问题的方法: (i)第5.3节中用于无线体域网(WBAN)无线通信信道监控的 MedMon;(ii)第5.4节中用于光密钥交换的OpSecure;(iii)第 5.5节中通过振动侧信道实现安全通信的SecureVibe。
5.1 NeST:合成紧凑型深度神经网络
神经网络(NNs)已经开始对各种医疗应用产生广泛影响。它们通过多层抽象从海量数据中提炼智能的能力,可实现卓越甚至超越人类的表现,正如CheXNet和DeepBind的案例所示(见第2.2节)。然而,传统的神经网络消耗
庞大的内存和计算能耗。因此,大多数面向医疗保健的深度神经网络仍局限于临床云中,无法应用于日常使用的手机。
针对大型应用寻找精确且紧凑的神经网络(或轻量级神经网络)的问题几十年来一直未能解决。传统方法通过大量试错来搜索最优神经网络。这类方法效率极低。对于具有数百万个参数的深度神经网络,即使使用最快的GPU,每次训练尝试也容易消耗数十甚至数百小时。此外,生成的神经网络仍然存在显著冗余。例如,韩等人表明,在不影响准确性的前提下,著名的AlexNet(Krizhevsky et al., 2012年)神经网络架构在ImageNet数据集(Deng et al., 2009年)上的参数数量可减少 9×(韩等人, 2015年)。
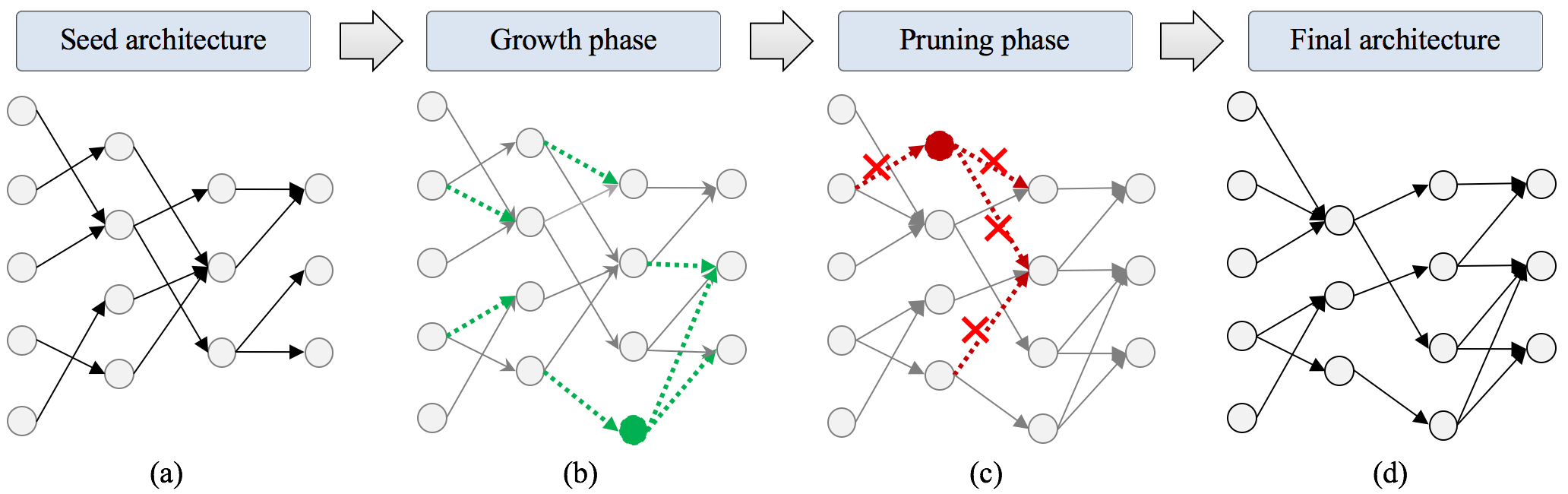
为解决这些问题,戴等人提出了一种神经网络合成工具(NeST),该工具可根据目标应用数据集自动生成精确且极其紧凑的神经网络 (戴等人, 2017年)。NeST能显著降低深度神经网络的内存成本、推理运行时间以及能耗。它有望使手机等移动设备集成深度神经网络成为可能,从而将此类神经网络的应用范围从临床领域扩展到日常医疗。
NeST 方法如图5.1所示。它从一个非常稀疏的种子神经网络架构开始,通过以下方式迭代调优该架构:(i)神经元的基于梯度的增长,以及(ii) 基于幅值的剪枝
图5.2: NeST中神经网络架构综合算法的主要组件(戴等人, 2017年)
和连接。这两个阶段涉及的主要技术总结在图5.2中。增长阶段利用梯度信息添加新连接、神经元和特征图,使神经网络能够轻松适应当前问题。剪枝阶段则移除冗余连接和神经元,从而大幅减少神经网络参数数量,进而降低内存和每次推理的浮点运算(FLOPs),即计算成本。最终,NeST生成准确但非常紧凑的神经网络。
戴等人使用NeST基于LeNet‐300‐100和LeNet‐5架构(Lecun et al.,1998)的提示为MNIST数据集合成紧凑型神经网络,并基于 AlexNet架构的提示为ImageNet数据集2合成紧凑型神经网络。NeST提供的神经网络极为紧凑,其准确率相对于相应的神经网络基线相同或更高: 对于 LeNet‐300‐100,NeST 将网络参数减少了 70.2×,FLOPs 减少了 79.4×。对于LeNet‐5,NeST将网络参数减少了 74.3×,FLOPs减少了 43.7×。对于AlexNet,NeST将网络参数减少了 15.7×,FLOPs减少了 4.6×。所有这些结果构成了当前最先进的技术水平(戴等人,2017年)。
5.2 压缩感知:降低计算负载
压缩感知是另一种可通过降低计算负载来减少智能医疗系统能耗和存储需求的技术。当数据在次级基上稀疏,并且所使用的随机投影矩阵与该次级基之间存在非相干性时,压缩感知即可适用(Donoho, 2006年;Candes and Tao,2006年)。如果随机投影矩阵的元素是从 {+1,−1}集合中均匀分布采样得到的,则通常满足这种非相干性 (Candes and Tao,2006年;肖艾布等人,2015年)。
随机投影是一种单矩阵乘法运算。因此,其计算开销很小( Shoaib et al.,2015年)。然而,对于传统的奈奎斯特域信号处理而言,压缩信号需要在用户端进行重建,以支持机器学习推理。由于需要求解凸优化问题,重建过程的计算负载很高,导致其非常耗能(能耗比压缩高出三到四个数量级)(Shoaib et al.,2015年)。由于高能耗操作与许多智能医疗系统不兼容(因为需要频繁进行电池充电) (Akmandorand Jha,2018年),Shoaib et al. 和 卢等人 提出了在推理阶段无需信号重建的技术。这些技术分别基于对压缩感知数据的直接计算(do notrequire signal reconstructionin the inference stage.These techniquesare based on direct computations on compressively-sensed data(Shoaibet al., 2015, 2014) and Compressed SignalProcessing(CSP)(Lu etal.,2016), respectively.
对压缩感知数据进行直接计算需要推导出压缩域信号处理操作。这些操作使得特征提取和分类都能在压缩域中完成,从而显著降低能耗。
CSP在奈奎斯特域中执行信号处理操作,然后进行随机投影。这最小化了压缩域相对于奈奎斯特域的内积误差,从而提高了分类准确率。我们将在下文详细讨论这些方法。
5.2.1 压缩感知数据上的直接计算
在奈奎斯特域中,对应于数据时段 x的特征向量通过公式5.1基于线性信号处理矩阵H(肖艾布等人,2015年)获得。在压缩域中,由于数据通过随机投影矩阵 Φ进行随机投影,ˆ肖艾布等人推导出矩阵H在压缩域中的等效形式H。ˆH可用于获取特征向量ˆy(公式5.2)。理想情况下,如公式5.3所示,ˆy和 y应相等,以保持推理性能。
y= H · x (5.1)
yˆ= Hˆ · Φ · x (5.2)
y= yˆ⇒ H · x= Hˆ · Φ · x⇒ H= Hˆ · Φ (5.3)
对于一个 N维输入 x,H是一个 N×N矩阵, Φ是一个 M×Nˆ ˆ矩阵,其中 MN,且 H是一个 N×M矩阵。为了推导 H,公式5.3指定了 N × M个变量和 N × N个方程,从而形成一个超定系统(肖艾布等人,2015年)。为了解决这个问题,肖艾布等人引入了一个正则化项 Θ。这将公式5.3转换为公式5.4。
Θ · y= yˆ⇒ Θ · H · x= Hˆ · Φ · x⇒ Θ · H= Hˆ · Φ (5.4)
肖艾布等人获得方程H和非方阵H情况下的解。当H为方阵时,解可以是精确的或近似的(近似解以分类准确率的轻微下降换取更高的能效)。算法2ˆ展示了如何在这些情况下获得H。
肖艾布等人将他们提出的技术应用于神经假体脉冲分类和脑电癫痫检测。在神经假体的情况下,即使样本更少,该技术也能实现与奈奎斯特域处理相当的系统性能。在压缩域中,作为该应用程序主要系统级指标的脉冲计数(SC)、神经元放电率(FR)估计和变异系数(CV)对应的准确率分别为98.63%、98.56%和96.51%,而在奈奎斯特域中分别为98.97%、99.69%和97.09%。在基于脑电的癫痫发作
算法2 压缩域信号处理的计算 矩阵 Hˆ(肖艾布等人,2015年)
要求: 投影维度 K 和矩阵 Φ 以及 H 确保: Θ和 Hˆ,其中 ΘH= HˆΦ
1:Init: N←# 列(Φ); M←# 行(Φ); L←# 行(H)
2:如果 L= N 那么
3: DT:= ΦH−1;USVT←奇异值分解(D); .对于 θi=D ˆhi
4:如果 K= M 那么
5: ˆH = √(N/M)(S−1VT); Θ= √(N/M)(ˆHΦH−1);
6: else
7: 对于 i= 1到 K 执行
8: xi ∼ N(0, IM)/√(K); .对于ˆhi ∼ N(0,VS−2VT)
9: ˆhi=VS−1xi; θi= Uxi;
10: end for
11: Θ=√(N/M) (θ1T;…; θKT);ˆH=√(N/M) (ˆh1T;…;ˆhTK);
12:结束如果
13:否则
14: PQRT←奇异值分解(H); VSUT←奇异值分解(Φ);
15: Θ ∼ N(0,1) /√(NK/M); . ortho(Θ) 如果 K> L
16: B = ΘPQ; A = BRTU; ˆH = √N/M(AS−1VT);
17:结束 if
检测时,他们在压缩域中需要更少的样本,并实现了94.43%的灵敏度、 4.70秒延迟和每小时0.1543次误报。该结果与奈奎斯特域中的96.03% 灵敏度、4.59秒延迟和每小时0.1471次误报相当。
该方法可以显著降低医疗应用中的能耗和存储容量。例如,Nia et al.(2015年)表明,该方法可使心律失常检测的心电图传感器能耗降低高达 724×。当脑电图传感器用于癫痫发作检测时,其存储节省可达 19344×。
5.2.2 压缩信号处理
CSP(Lu et al.,2016年)在奈奎斯特域中进行信号处理和特征提取。在计算出特征向量后,CSP使用随机投影来提高能效。如˜公式 5.5 所示,H矩阵提供此变换并输出特征向量 y˜。Lu等人旨在最小化 y˜与 y之间的差异,以保持推理性能。
y˜= H˜ · x (5.5)
卢等人还将其技术应用于神经假体脉冲分类和脑电癫痫检测。在神经假体脉冲分类的情况下,奈奎斯特域中的SC、FR和CV平均误差分别为4.00%、4.00%和2.75%。在压缩域中,使用 32×更少的样本, SC、FR和CV的平均误差分别为4.89%、4.90%和3.42%。在脑电癫痫检测的情况下,与奈奎斯特域(灵敏度100%,延迟4.37秒,每小时误报次数0.12次)相比,使用 32×更少的样本获得了100%的灵敏度、 4.33秒的延迟以及每小时0.22次的误报次数。
CSP 在将数据压缩 32× 的同时提供了相当的推理性能。这可用于大幅降低能量和存储消耗,从而为资源受限的医疗应用带来显著优势。
5.3 MedMon:防御无线攻击
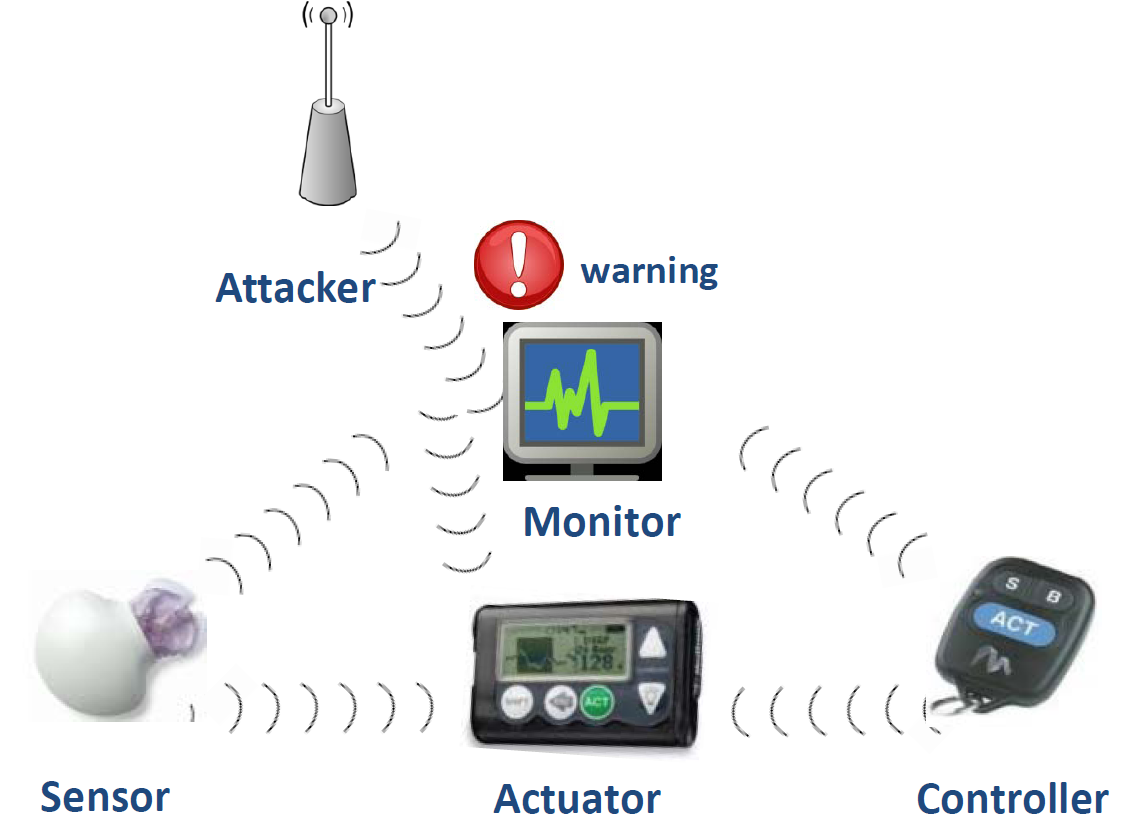
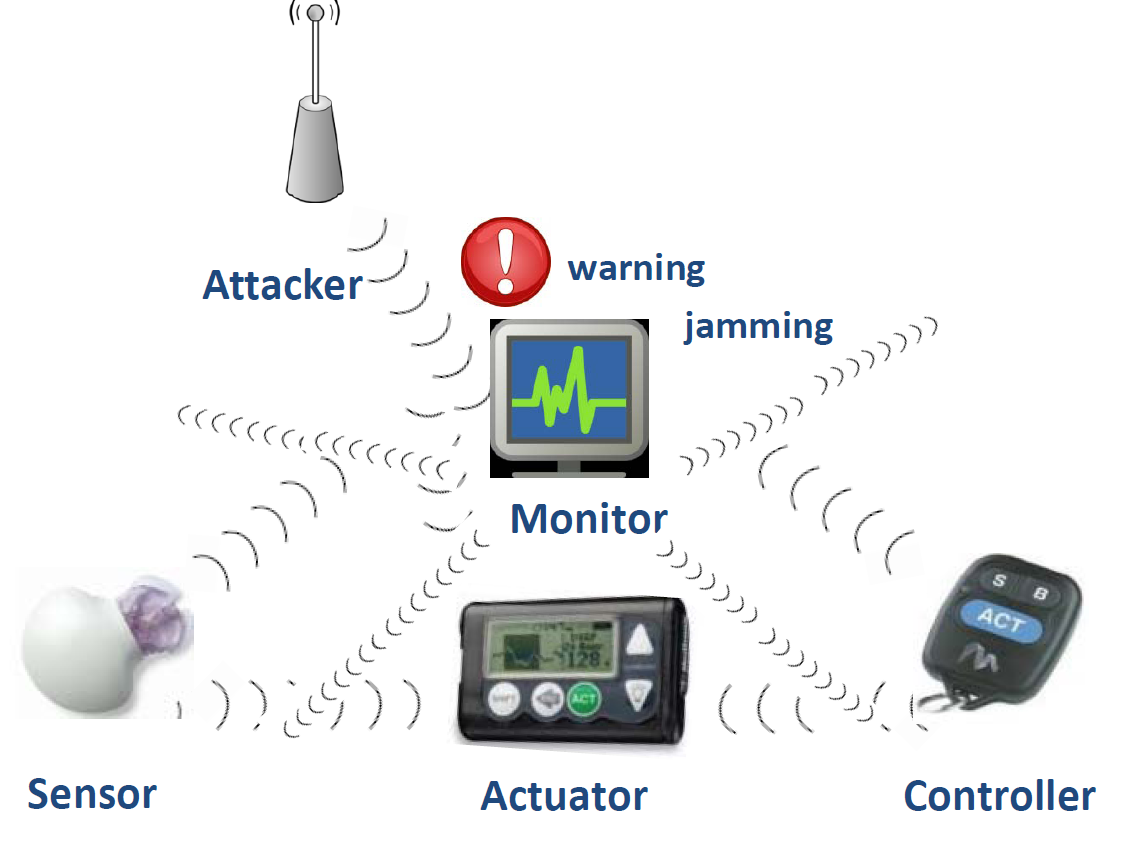
糖尿病是21世纪最重要的公共卫生挑战之一。2015年,美国有超过 3030万人患有糖尿病(占人口的9.4%)3。糖尿病患者依赖有效的监测与响应系统,例如连续血糖监测和胰岛素输送,以避免高血糖(高血糖水平)或低血糖(低血糖水平)。这些系统是糖尿病管理的最先进方法,因此在糖尿病患者中变得越来越普及。
然而,连续血糖监测和胰岛素输送系统存在安全漏洞。例如,李等人成功对一种流行的血糖监测和胰岛素输送系统发起了安全攻击 (李等人,2011年)。这些攻击利用了未加密的无线通信信道,该信道使葡萄糖传感器、血糖仪、胰岛素泵和遥控器之间能够相互通信。因此,用户的安全与隐私可能轻易受到损害。
李等人5.3使用一种广泛可得的现成通用软件无线电外设( USRP)来发起攻击,如图所示。USRP 可以在目标频段内截获无线电通信,并以不同的功率和多种调制方案在该目标频段生成无线信号。他们的攻击可分为两大类:
•被动攻击:窃听无线通信。Liet等人使用USRP拦截遥控器与胰岛素泵在915MHz通信频段之间的通信,如图5.3所示。他们首先识别出信道调制方案为通断键控方案(载波存在表示1,否则表示0)。这使得他们能够通过逆向工程破解80位通信数据包:4位设备类型指示符、36位设备PIN码、12位有效载荷信息,
12位系统计数器、12位循环冗余校验字符串以及末尾的4位常量字符串‘0101’。该12位有效载荷比特串会泄露患者信息,例如治疗的存在与否以及血糖水平,从而完全破坏用户隐私。
李等人表明,当USRP处于胰岛素泵的7‐8米范围内时,很容易发起被动攻击。
•主动攻击:伪装并控制胰岛素泵以改变治疗。在破解80位数据包后,李等人生成看似合法的数据包,这些数据包通过所有检查,因此被胰岛素泵接受。他们使用USRP向胰岛素泵传输这些恶意构造的数据包。这些数据包包含恶意命令,例如停止胰岛素注射或注射过高或过低剂量。这可能导致高血糖或低血糖等严重不良后果,从而危及患者生命。
李等人表明,即使USRP距离胰岛素泵20米远,仍可成功发起主动攻击。这一距离甚至超过了遥控器原有的控制范围:4.5米。
李等人提出了两种针对这些攻击的对策。第一种方法采用基于滚动码编码器的密码学方法,该编码器成对嵌入在遥控器和胰岛素泵中。加密机制可防止攻击者访问设备PIN码和数据载荷,从而防御这两种攻击。第二种方法通过人体而非无线通信信道传输命令信号。只要攻击者没有处于与患者非常接近的距离或未接触患者的皮肤,就无法获取数据包。这两种方法都会导致胰岛素泵产生额外电池能耗。
张等人提出了一种名为MedMon的医疗安全监控器,用于检测对无线体域网(WBAN)的无线攻击,且在生物医学设备上实现零额外功耗(张等人, 2013年


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









