







标签多少才够用?质量差怎么办?机器学习五大范式帮你搞定所有数据场景
在数据驱动决策成为时代核心引擎的今天,机器学习作为实现 “从数据到知识” 转化的核心技术,其范式选择直接决定了模型的性能边界、应用成本与落地价值。而贯穿所有机器学习范式的核心矛盾,始终围绕着 “数据标签” 这一关键要素展开 —— 人工标注的精确标签是模型学习的 “黄金指南”,却需耗费高昂的人力、时间成本;无标签数据虽海量易得,却因缺乏明确监督信号而难以直接转化为精准的预测能力。
从为图像逐像素标注 “肿瘤区域” 的医学影像分析,到仅能获取 “含异常 / 无异常” 粗粒度标签的工业设备监测;从拥有百万级精确标注的 ImageNet 图像分类任务,到互联网上海量未标注的文本、视频数据探索 —— 不同场景下 “标签的可得性、质量与规模” 存在巨大差异,也催生了机器学习领域多样化的学习范式。
监督学习凭借全量精确标签实现了高精度预测,却受困于标注成本的桎梏;无监督学习挣脱了标签依赖,却因缺乏目标导向而难以直接解决实际预测问题;自监督学习创新地从数据自身生成 “伪标签”,在无人工干预下搭建起 “监督信号” 的桥梁;半监督学习以少量精确标签为锚点,激活了海量无标签数据的价值;弱监督学习则直面现实中 “标签质量低而非数量少” 的痛点,从模糊、嘈杂的监督信号中挖掘有效信息。
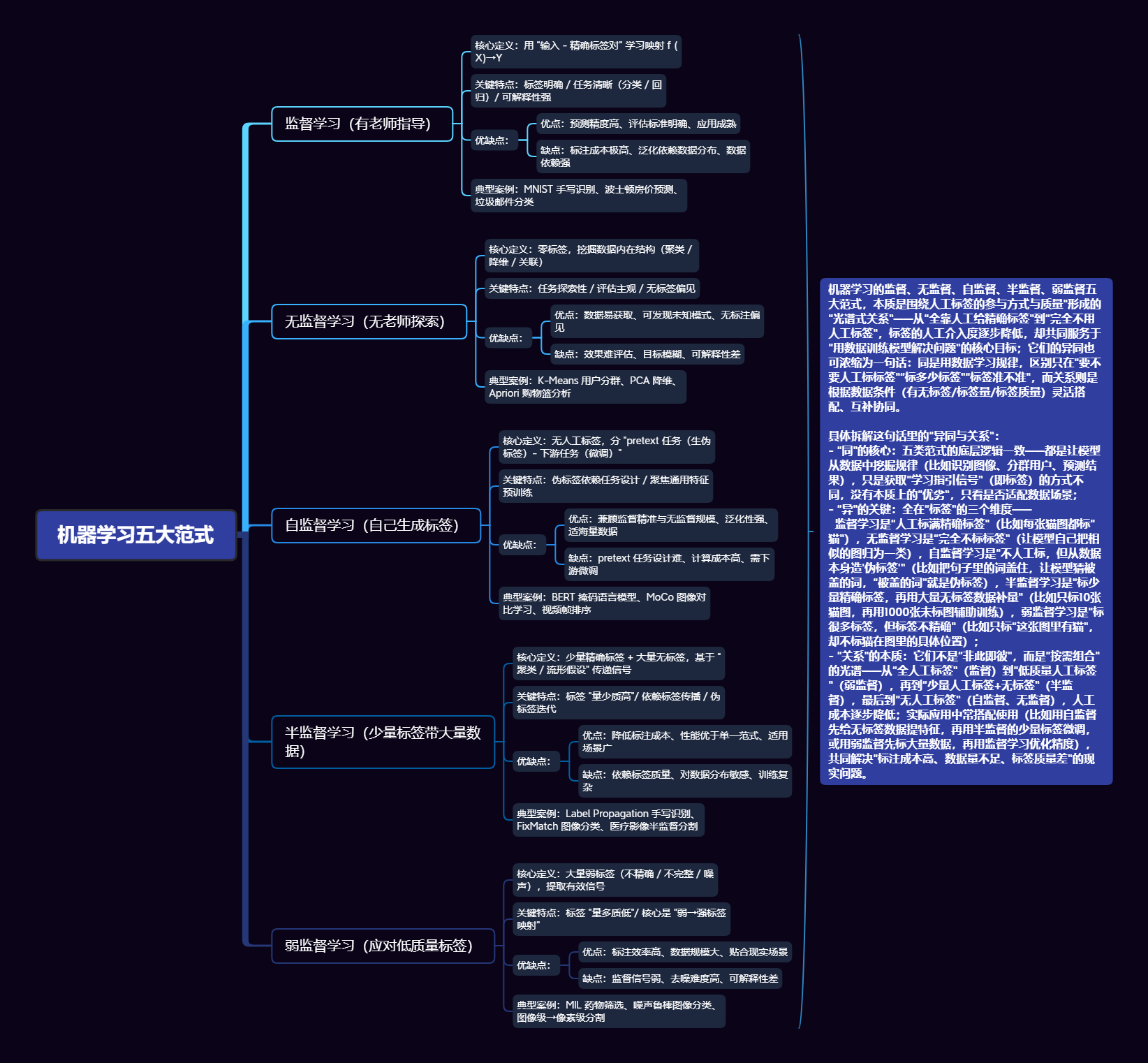
监督学习、无监督学习、自监督学习、半监督学习、弱监督学习 这五种学习范式并非孤立存在,而是构成了一条从 “全人工监督” 到 “无人工干预” 的完整光谱,分别对应着不同标签条件下的最优解。深入理解它们的核心逻辑、技术路径与适用边界,不仅是掌握机器学习理论体系的关键,更是在实际场景中平衡 “模型性能” 与 “成本投入”、实现技术落地的前提。本文将系统剖析监督学习、无监督学习、自监督学习、半监督学习与弱监督学习的本质特征,厘清其内在关联与核心差异,为不同场景下的范式选择提供清晰指引。
要深入理解监督学习、无监督学习、自监督学习、半监督学习、弱监督学习,需从“标签依赖”这一核心维度切入——它们的本质差异在于对“人工标注数据(标签)”的依赖程度、质量要求和利用方式。以下将从定义、核心特点、关键技术与案例、优缺点、典型应用场景五个维度逐一拆解,并最终系统梳理它们的关系与区别。
一、监督学习(Supervised Learning):“有老师指导的学习”
监督学习是最成熟、应用最广泛的机器学习范式,核心是“用带人工标注标签的数据训练模型,让模型学习‘输入→标签’的映射关系”。这里的“监督”类比人类学习中的“老师”——模型每一步预测都会与“标准答案(标签)”对比,通过误差调整参数。
1. 核心定义
给定数据集 ( D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } ) ( D = \{(x_1,y_1), (x_2,y_2), ..., (x_n,y_n)\} ) (D={(x1,y1),(x2,y2),...,(xn,yn)}),其中 ( x i ) ( x_i) (xi) 是输入数据(如图片、文本、数值特征), ( y i ) ( y_i) (yi) 是人工标注的精确标签(如“猫/狗”“垃圾邮件/正常邮件”“房价”),模型通过学习 ( x i ) ( x_i ) (xi) 与 ( y i ) ( y_i ) (yi) 的关联,最终能对新输入 ( x n e w ) ( x_{new} ) (xnew) 预测出对应的 ( y n e w ) ( y_{new} ) (ynew)。
2. 关键特点
- 标签依赖性极强:必须依赖大规模、高质量的人工标注数据,标签是模型训练的“指挥棒”。
- 目标明确:任务目标由标签定义(如分类、回归),模型无需自主探索数据结构。
- 可解释性相对较高:多数监督学习模型(如决策树、逻辑回归)的预测逻辑可追溯,结果易验证。
3. 关键技术与案例
根据标签类型,监督学习分为两大核心任务:
| 任务类型 | 标签特点 | 典型算法 | 实际案例 |
|---|---|---|---|
| 分类任务 | 标签是离散类别(如“0/1”“猫/狗/鸟”) | 逻辑回归、支持向量机(SVM)、随机森林、卷积神经网络(CNN,用于图像分类) | 1. 图像识别:给图片标注“猫”或“狗” 2. 文本分类:给新闻标注“体育/财经/娱乐” 3. 垃圾邮件检测:给邮件标注“垃圾/正常” |
| 回归任务 | 标签是连续数值(如“价格”“温度”“销量”) | 线性回归、梯度提升树(XGBoost/LightGBM)、神经网络(用于复杂回归) | 1. 房价预测:输入“面积、地段、楼层”,输出“房价” 2. 销量预测:输入“促销力度、季节、竞品价格”,输出“未来一周销量” 3. 温度预测:输入“历史温度、湿度、气压”,输出“次日气温” |
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 1. 预测精度高:在标签质量高、数据充足时,模型性能稳定且可达到工业级精度; 2. 任务通用性强:可覆盖分类、回归、排序等绝大多数明确目标的任务; 3. 工程落地成熟:有大量开源工具(如Scikit-learn、PyTorch Lightning)和调参经验支持。 | 1. 标注成本极高:大规模数据标注需大量人力(如ImageNet数据集含1400万张标注图片,耗时数年); 2. 泛化性受限:模型易“过拟合”到训练数据的标注细节,对未见过的场景(如罕见样本、数据分布变化)适应能力差; 3. 依赖标签质量:若标签存在错误(如人工标注失误),模型会“学错”,且难以自我修正。 |
5. 典型应用场景
需要明确预测目标且能承担标注成本的场景:图像识别、自然语言处理(NLP)中的情感分析、推荐系统中的用户偏好预测、金融风控中的欺诈检测等。
二、无监督学习(Unsupervised Learning):“无老师指导,自主探索结构”
无监督学习是“仅用无标签数据训练模型,让模型自主发现数据内在的结构或规律”——类比人类“通过观察大量现象自主总结规律”,无需人工提供“标准答案”。
1. 核心定义
给定数据集 ( D = { x 1 , x 2 , . . . , x n } ) ( D = \{x_1, x_2, ..., x_n\} ) (D={x1,x2,...,xn}),无任何人工标注标签(即无 ( y i ) ) ( y_i )) (yi)),模型通过分析数据自身的特征相似性、分布模式,挖掘隐藏的结构(如聚类、关联、降维)。
2. 关键特点
- 零标签依赖:完全无需人工标注,仅利用数据本身的特征信息。
- 目标模糊:任务目标是“探索数据结构”,而非“预测固定标签”,结果需人工解读。
- 主观性强:模型输出的结构(如聚类结果)是否有意义,依赖领域知识判断(如“将客户分为3类” vs “5类”,需业务人员验证)。
3. 关键技术与案例
无监督学习的核心任务是“结构发现”,主要分为三类:
| 任务类型 | 核心目标 | 典型算法 | 实际案例 |
|---|---|---|---|
| 聚类任务 | 将相似数据归为一类,不相似数据分在不同类 | K-Means(硬聚类)、DBSCAN(密度聚类)、层次聚类、高斯混合模型(GMM,软聚类) | 1. 客户分群:根据“消费金额、购买频率、浏览时长”将客户分为“高价值/中等/低价值”; 2. 异常检测:识别信用卡交易中“与正常交易模式差异大的异常交易”(如盗刷); 3. 图像聚类:将无标签图片按“内容相似性”分为“风景/人物/动物”。 |
| 降维任务 | 减少数据特征维度(去除冗余信息),同时保留核心结构 | 主成分分析(PCA)、t-SNE(可视化降维)、自编码器(Autoencoder,深度学习降维) | 1. 高维数据可视化:将100维的用户特征降为2维,用散点图展示用户分布; 2. 图像压缩:将256×256的图片降维后存储,解压时可恢复核心信息; 3. 特征冗余去除:在房价预测中,去除“建筑面积”与“使用面积”的冗余关联。 |
| 关联规则挖掘 | 发现数据中“频繁共同出现的特征组合” | Apriori算法、FP-Growth算法 | 1. 购物篮分析:发现“购买面包的客户中,80%会同时购买牛奶”(即“面包→牛奶”的关联规则); 2. 网页推荐:发现“浏览‘机器学习’页面的用户,60%会继续浏览‘深度学习’页面”。 |
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 1. 数据获取成本低:无需人工标注,可利用海量无标签数据(如互联网爬取的图片、文本); 2. 可发现未知规律:能挖掘人工未注意到的隐藏结构(如异常交易模式、潜在客户群体); 3. 适用于“探索性分析”:在任务目标不明确时(如“客户有哪些潜在分群”),可作为前期分析工具。 | 1. 结果不可控:模型输出的结构可能无实际意义(如聚类得到的“客户群”与业务需求无关); 2. 评估困难:无标签意味着无“标准答案”,难以用精确指标(如准确率)评估模型性能,需依赖人工主观判断; 3. 精度有限:相比监督学习,无监督学习的结果难以直接用于高精度预测任务(如仅靠聚类无法精准识别“猫”)。 |
5. 典型应用场景
数据标注困难、任务目标不明确的场景:客户分群、异常检测、数据预处理(降维、去噪)、关联推荐(如购物篮分析)、探索性数据分析(如生物基因序列聚类)。
三、自监督学习(Self-Supervised Learning):“无监督的进阶,自己给数据打标签”
自监督学习是无监督学习的一个重要分支,核心创新是“从无标签数据中自动生成‘伪标签’(Pseudo-Label),再用监督学习的方式训练模型”——相当于“自己给自己当老师”,既避免了人工标注,又能利用监督学习的高效训练逻辑。
1. 核心定义
给定无标签数据集 ( D = { x 1 , x 2 , . . . , x n } ) ( D = \{x_1, x_2, ..., x_n\} ) (D={x1,x2,...,xn}),通过数据自身的内在关联(如空间关系、时序关系、上下文关系)设计“ pretext task( pretext 任务,即‘伪任务’)”,自动为 ( x i ) ( x_i ) (xi) 生成对应的“伪标签 ( y p s e u d o ) ( y_{pseudo} ) (ypseudo)”,再以“ ( ( x i , y p s e u d o ) ) ( (x_i, y_{pseudo}) ) ((xi,ypseudo))”为训练数据,用监督学习的方式训练模型,最终将模型迁移到实际任务(downstream task,如分类、检测)。
2. 关键特点
- “伪标签”是核心:伪标签由数据自身生成(非人工),质量依赖“pretext任务设计”。
- 分两阶段训练:先通过pretext任务训练“通用特征提取器”,再将该提取器迁移到下游任务(通常只需少量标注数据微调)。
- 兼顾无监督与监督优势:既无需人工标注,又能学习到结构化的特征(比传统无监督学习的特征更有用)。
3. 关键技术与案例
自监督学习的核心是“设计合理的pretext任务”,不同数据类型的任务设计差异较大:
| 数据类型 | Pretext任务设计逻辑 | 典型算法/模型 | 实际案例 |
|---|---|---|---|
| 图像数据 | 利用图像的空间关联性(如局部与整体、旋转与原始)生成伪标签 | 1. 旋转预测:将图片随机旋转0°/90°/180°/270°,伪标签为“旋转角度”; 2. 拼图还原:将图片切成9块打乱,伪标签为“正确拼接顺序”; 3. MoCo(动量对比学习):通过对比“同一图片的不同增强版本(正样本)”与“其他图片(负样本)”,学习图像特征。 | 1. 图像分类预训练:用MoCo在无标签图片上训练特征提取器,再用少量标注数据微调,精度接近全监督训练; 2. 医学影像分析:在无标注CT影像上用“切片顺序预测”预训练,再迁移到“肿瘤检测”任务,减少对标注数据的依赖。 |
| 文本数据 | 利用文本的上下文关联性生成伪标签 | 1. BERT的“掩码语言模型(MLM)”:随机掩盖句子中15%的词,伪标签为“被掩盖的原词”; 2. 句子排序:将段落中的句子打乱,伪标签为“正确句子顺序”; 3. 对比学习(如SimCSE):将同一句子的不同表达(如同义词替换)作为正样本,其他句子作为负样本,学习文本语义。 | 1. NLP通用预训练:BERT在海量无标签文本(如维基百科)上用MLM预训练,再迁移到“情感分析”“文本分类”等任务,大幅提升小样本场景性能; 2. 机器翻译:在无平行语料(如“英-中对照文本”)时,用自监督预训练的文本特征器提升翻译精度。 |
| 时序数据(如视频、传感器数据) | 利用时序关联性(如帧顺序、前后状态)生成伪标签 | 1. 视频帧排序:将视频片段的帧打乱,伪标签为“正确帧顺序”; 2. 传感器状态预测:用前10秒的传感器数据(如加速度)预测后1秒的状态,伪标签为“实际后1秒状态”。 | 1. 视频行为识别:在无标注视频上预训练帧顺序预测模型,再迁移到“跌倒检测”“手势识别”任务; 2. 工业设备故障预测:用传感器数据的时序关联预训练,再迁移到“设备异常检测”。 |
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 1. 无需人工标注:可利用海量无标签数据,解决“标注成本高”的核心痛点; 2. 特征通用性强:pretext任务训练的特征提取器可迁移到多个下游任务(如BERT可用于分类、问答、翻译); 3. 小样本性能优:迁移到下游任务时,只需少量标注数据微调即可达到较高精度。 | 1. Pretext任务设计难度高:需深入理解数据特性(如图像的空间结构、文本的上下文),设计的任务若不合理,伪标签质量差,模型无法学习有效特征; 2. 训练成本高:多数自监督模型(如MoCo、BERT)需大规模算力支持(如GPU集群),训练周期长; 3. 泛化性依赖下游微调:若下游任务与pretext任务差异过大(如用“图像旋转”预训练迁移到“医学影像分割”),性能可能下降。 |
5. 典型应用场景
数据标注稀缺但无标签数据充足的场景:通用人工智能(如BERT、GPT的预训练)、医学影像分析(标注成本极高)、工业设备监测(传感器数据多但故障样本少)、小样本学习(如仅100张标注图片实现图像分类)。
四、半监督学习(Semi-Supervised Learning):“少量标签+大量无标签数据的结合”
半监督学习的核心是“利用少量人工标注数据(监督信号)引导大量无标签数据的学习,提升模型性能”——介于监督学习(全标签)和无监督学习(全无标签)之间,解决“标注数据不足但有少量标签可用”的场景。
1. 核心定义
给定数据集 $ ( D = D_{labeled} \cup D_{unlabeled} )$ ,其中$( D_{labeled} = {(x_1,y_1), …, (x_k,y_k)})( k ) $ 很小,如仅占总数据的5%-20%), ( D u n l a b e l e d = { x k + 1 , . . . , x n } ) ( D_{unlabeled} = \{x_{k+1}, ..., x_n\} ) (Dunlabeled={xk+1,...,xn})(无标签,占比大)。模型先利用 ( D l a b e l e d ) ( D_{labeled} ) (Dlabeled) 学习初步的“输入→标签”映射,再通过“标签传播”“伪标签生成”等方式,将 ( D l a b e l e d ) ( D_{labeled} ) (Dlabeled) 的监督信号传递到 ( D u n l a b e l e d ) ( D_{unlabeled} ) (Dunlabeled),最终提升对新数据的预测精度。
2. 关键特点
- 标签“量少质高”:少量标注数据是“锚点”,引导无标签数据的学习方向;
- 核心假设明确:基于两个关键假设:
1. 聚类假设:相似的数据应具有相同的标签(如“相似的图片都是猫”);
2. 流形假设:数据分布在低维流形上,相邻数据的标签应一致(如流形上相近的样本标签相同); - 兼顾监督与无监督:用监督信号避免无监督学习的“结果失控”,用无标签数据补充监督学习的“数据不足”。
3. 关键技术与案例
半监督学习的核心是“如何将少量标签的信息传递到无标签数据”,主要分为三类方法:
| 方法类型 | 核心逻辑 | 典型算法 | 实际案例 |
|---|---|---|---|
| 生成式方法 | 假设数据由某个生成模型(如高斯混合模型)生成,先利用少量标签估计模型参数,再用模型为无标签数据分配标签 | 高斯混合模型(GMM)、生成对抗网络(GAN,用少量标签训练生成器和判别器) | 1. 文本分类:用少量标注新闻训练GMM,再为大量无标签新闻分配“体育/财经”标签,扩大训练集; 2. 图像生成:用少量标注的“猫”图片训练GAN,生成更多“猫”的伪样本,辅助监督模型训练。 |
| 半监督SVM(S3VM) | 基于SVM的“最大间隔”思想,在无标签数据中寻找“最可能正确的标签”,使最终分类边界尽可能远离所有数据点 | 半监督支持向量机(S3VM)、标签传播算法(Label Propagation) | 1. 手写数字识别:仅用10%的标注数字(如MNIST数据集的6000张)训练S3VM,通过标签传播利用剩余90%无标签数据,精度接近全监督训练; 2. 客户流失预测:用少量“已流失/未流失”客户的标签,通过标签传播为大量无标签客户分配伪标签,提升预测精度。 |
| 伪标签方法(深度学习常用) | 1. 用少量标注数据训练一个基础模型; 2. 用基础模型为无标签数据预测“高置信度伪标签”(如预测概率>0.9的标签); 3. 将“标注数据+高置信度伪标签数据”合并,重新训练模型,迭代优化。 | 伪标签迭代训练、FixMatch(固定数据增强方式提升伪标签质量) | 1. 图像分类:用1%的CIFAR-10标注数据训练基础模型,为无标签数据生成伪标签,迭代训练后精度提升20%+; 2. 语音识别:用少量标注语音训练基础模型,为大量无标注语音生成“语音→文字”伪标签,扩大训练集。 |
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 1. 降低标注成本:只需标注少量数据,即可利用大量无标签数据提升性能,比全监督学习更经济; 2. 性能优于单一方法:在标注数据不足时,性能远好于仅用少量标签的监督学习,也优于无监督学习; 3. 适用场景广泛:多数实际场景中,标注数据都是“少量”的,半监督学习的实用性强。 | 1. 依赖标签质量:若少量标注数据存在错误(如标注偏差),错误会通过“标签传播”放大,导致模型性能下降; 2. 对数据分布敏感:若无标签数据与标注数据的分布差异大(如标注数据是“城市猫”,无标签数据是“乡村猫”),模型无法有效利用无标签数据; 3. 训练复杂度高:需设计复杂的标签传播或伪标签迭代逻辑,比监督学习更难调参。 |
5. 典型应用场景
标注数据稀缺但有少量标签的场景:手写数字识别(少量标注即可覆盖多数样本)、医疗诊断(少量专家标注病例)、语音识别(少量标注语音+大量无标注语音)、工业质检(少量合格/不合格产品标注)。
五、弱监督学习(Weakly Supervised Learning):“标签质量低,而非数量少”
弱监督学习的核心是“利用‘低质量标签’(而非‘少量标签’)训练模型”——这里的“弱”指标签的“质量弱”(不精确、不完整、含噪声),而非“数量少”(甚至可能有大量低质量标签)。它解决的是“标注容易但标签不精确”的场景。
1. 核心定义
给定数据集 ( D = { ( x 1 , y 1 w ) , ( x 2 , y 2 w ) , . . . , ( x n , y n w ) } ) ( D = \{(x_1,y_1^w), (x_2,y_2^w), ..., (x_n,y_n^w)\} ) (D={(x1,y1w),(x2,y2w),...,(xn,ynw)}),其中 ( y i w ) ( y_i^w ) (yiw) 是弱标签(质量低的标签),而非精确的人工标注标签 ( y i ) ( y_i ) (yi)。弱标签主要分为三类:
- 不精确标签(Imprecise Labels):标签粒度粗于实际需求(如需要“猫的品种”,但标签只有“猫”);
- 不完整标签(Incomplete Labels):部分样本无标签,或标签缺失(如图片中有“猫和狗”,但标签只有“猫”);
- 含噪声标签(Noisy Labels):标签存在错误(如将“狗”误标为“猫”,或随机标注)。
模型的目标是“从弱标签中提取有效监督信号,学习接近精确标签的预测能力”。
2. 关键特点
- 标签“量多质低”:弱标签通常容易获取(成本低),但质量无法保证;
- 核心是“去噪/补全标签”:模型需通过算法逻辑(如噪声过滤、标签补全)从弱标签中挖掘“真实监督信号”;
- 与监督学习的区别:监督学习用“精确标签”,弱监督学习用“弱标签”;与半监督学习的区别:半监督学习是“少量精确标签+大量无标签”,弱监督学习是“大量弱标签(可能无无标签数据)”。
3. 关键技术与案例
根据弱标签类型,技术路线差异较大:
| 弱标签类型 | 核心技术逻辑 | 典型算法 | 实际案例 |
|---|---|---|---|
| 不精确标签 | 从粗粒度标签中推断细粒度标签(如“图像级标签→像素级标签”) | 多实例学习(MIL)、标签细化(Label Refinement) | 1. 图像分割:只有“图像级标签(如‘猫’)”,通过MIL推断“像素级标签(哪些像素是猫)”; 2. 文本实体识别:只有“句子级标签(如‘包含人名’)”,通过标签细化定位“词级标签(哪个词是人)”。 |
| 不完整标签 | 补全缺失的标签(如用相似样本的标签补全当前样本) | 标签补全算法(Label Completion)、矩阵补全(Matrix Completion) | 1. 多标签图像分类:图片中有“猫、狗、鸟”,但标签只有“猫”,通过相似图片的标签补全“狗、鸟”; 2. 用户兴趣预测:用户仅标注了“喜欢电影”,通过用户浏览记录补全“喜欢动作片、科幻片”。 |
| 含噪声标签 | 过滤错误标签,保留正确标签(即“标签去噪”) | 噪声鲁棒损失函数(如Label Smoothing、Bootstrap Loss)、样本重加权(如Hard Negative Mining)、两阶段去噪(先检测噪声样本,再用干净样本训练) | 1. 图像分类:从互联网爬取的图片标签含大量错误(如“狼”标为“狗”),用Bootstrap Loss降低噪声样本的权重; 2. 情感分析:用户评论标注由非专业人员完成,含大量噪声(如“中性评论”标为“正面”),用样本重加权突出干净样本的作用。 |
4. 优缺点
| 优点 | 缺点 |
|---|---|
| 1. 标签获取成本低:弱标签可通过自动爬取(如互联网图片标签)、非专业标注(如众包)获取,无需专家标注; 2. 数据规模大:弱标签数据易大规模收集,可支撑复杂模型(如深度学习)的训练; 3. 适用场景贴合实际:多数真实场景中,标签都是“不精确/含噪声”的(如电商商品标签、社交媒体文本标签)。 | 1. 监督信号弱:弱标签中的有效信息少,模型易“学错”(如被噪声标签误导); 2. 去噪难度高:若噪声比例过高(如>30%),现有算法难以有效过滤噪声,性能大幅下降; 3. 可解释性差:多数弱监督模型(如深度学习去噪模型)的标签推断逻辑难以追溯,结果难以验证。 |
5. 典型应用场景
标签易获取但质量低的场景:互联网图像分类(爬取的标签含噪声)、众包标注任务(非专业人员标注)、多标签分类(标签易缺失)、图像分割(图像级标签易获取,像素级标签难标注)。
六、五大学习范式的关系与区别
1. 整体关系:以“标签”为核心轴的光谱分布
五大学习范式的本质是“对人工标注标签的依赖程度、质量要求的差异”,可看作一条“标签依赖光谱”:
无监督学习(零标签) → 自监督学习(自动生成伪标签) → 半监督学习(少量精确标签+大量无标签) → 弱监督学习(大量弱标签) → 监督学习(大量精确标签)
- 左半侧(无监督/自监督):完全不依赖人工标注,核心是“从数据自身挖掘信息”;
- 中间(半监督):依赖“少量人工标注”引导“大量无标签数据”,核心是“标签量的平衡”;
- 右半侧(弱监督/监督):依赖“大量标签”,核心是“标签质量的差异”(弱监督是低质量,监督是高质量)。
2. 核心区别:多维度对比
通过下表可清晰区分五大范式的关键差异:
| 对比维度 | 监督学习 | 无监督学习 | 自监督学习 | 半监督学习 | 弱监督学习 |
|---|---|---|---|---|---|
| 标签类型 | 大量、精确的人工标签 | 无任何标签 | 自动生成的伪标签 | 少量精确标签+大量无标签 | 大量、低质量的弱标签(不精确/含噪声) |
| 核心目标 | 学习“输入→标签”的映射 | 发现数据内在结构 | 预训练通用特征提取器 | 用少量标签引导无标签学习 | 从弱标签中提取有效监督信号 |
| 数据需求 | 大规模标注数据 | 大规模无标签数据 | 大规模无标签数据 | 少量标注+大量无标签数据 | 大规模弱标签数据 |
| 关键假设 | 标签精确、数据分布一致 | 数据存在内在结构 | 数据自身关联可生成伪标签 | 相似数据标签一致(聚类/流形假设) | 弱标签中存在有效监督信号 |
| 典型问题 | 分类、回归 | 聚类、降维、关联挖掘 | 特征预训练 | 小样本分类、预测 | 噪声过滤、标签补全 |
3. 易混淆范式的关键区别
-
自监督学习 vs 无监督学习:
相同点:均无人工标签;
不同点:自监督通过“pretext任务生成伪标签”,用监督学习方式训练(目标是学习有用特征);无监督直接探索数据结构(目标是结构发现)。
例:同样是无标签图片,自监督会“旋转图片并预测角度”(生成伪标签),无监督会“将图片聚类为不同类别”(无伪标签)。 -
半监督学习 vs 弱监督学习:
相同点:均非“大量精确标签”;
不同点:半监督的核心是“标签数量少”(但少量标签是精确的),弱监督的核心是“标签质量低”(但标签数量多)。
例:同样是图像分类,半监督是“100张精确标签+10000张无标签”,弱监督是“10000张含噪声的标签(如30%标错)”。 -
自监督学习 vs 半监督学习:
相同点:均利用无标签数据;
不同点:自监督无需任何人工标签(伪标签自动生成),半监督必须依赖少量人工标签(作为引导)。
例:同样是文本数据,自监督用“掩码预测”(无人工标签),半监督用“100条精确标注文本+10000条无标签文本”。
七、总结:如何选择合适的学习范式?
选择的核心是“数据标签的可获得性(数量)和质量”,以及“任务目标”:
- 若有大量精确标签、任务目标明确(如分类/回归)→ 监督学习;
- 若无任何标签、需探索数据结构(如分群/降维)→ 无监督学习;
- 若无任何标签、但需学习通用特征用于下游任务→ 自监督学习;
- 若只有少量精确标签、但有大量无标签数据→ 半监督学习;
- 若有大量标签、但标签质量低(含噪声/不精确)→ 弱监督学习。
机器学习的监督、无监督、自监督、半监督、弱监督五大范式,本质是围绕“人工标签的参与方式与质量”形成的“光谱式关系”——从“全靠人工给精确标签”到“完全不用人工标签”,标签的人工介入度逐步降低,却共同服务于“用数据训练模型解决问题”的核心目标;它们的异同也可浓缩为一句话:同是用数据学习规律,区别只在“要不要人工标标签”“标多少标签”“标签准不准”,而关系则是根据数据条件(有无标签/标签量/标签质量)灵活搭配、互补协同,实际应用中常结合使用(如 “自监督预训练+半监督微调”“弱监督去噪+监督训练”),共同解决真实场景中的数据与标签问题。
具体拆解这句话里的“异同与关系”:
- “同”的核心:五类范式的底层逻辑一致——都是让模型从数据中挖掘规律(比如识别图像、分群用户、预测结果),只是获取“学习指引信号”(即标签)的方式不同,没有本质上的“优劣”,只看是否适配数据场景;
- “异”的关键:全在“标签”的三个维度——
监督学习是“人工标满精确标签”(比如每张猫图都标“猫”),无监督学习是“完全不标标签”(让模型自己把相似的图归为一类),自监督学习是“不人工标,但从数据本身造‘伪标签’”(比如把句子里的词盖住,让模型猜被盖的词,“被盖的词”就是伪标签),半监督学习是“标少量精确标签,再用大量无标签数据补量”(比如只标10张猫图,再用1000张未标图辅助训练),弱监督学习是“标很多标签,但标签不精确”(比如只标“这张图里有猫”,却不标猫在图里的具体位置); - “关系”的本质:它们不是“非此即彼”,而是“按需组合”的光谱——从“全人工标签”(监督)到“低质量人工标签”(弱监督),再到“少量人工标签+无标签”(半监督),最后到“无人工标签”(自监督、无监督),人工成本逐步降低;实际应用中常搭配使用(比如用自监督先给无标签数据提特征,再用半监督的少量标签微调,或用弱监督先标大量数据,再用监督学习优化精度),共同解决“标注成本高、数据量不足、标签质量差”的现实问题。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









