







 本文深入探讨了SparkSQL条件下推的原理,通过具体案例解析了数据类型不匹配导致的全表扫描问题,揭示了谓词下推的机制,并通过源码分析解释了问题的根源。
本文深入探讨了SparkSQL条件下推的原理,通过具体案例解析了数据类型不匹配导致的全表扫描问题,揭示了谓词下推的机制,并通过源码分析解释了问题的根源。
首先感谢 spark君 细心的整理,下文是早些时候在群里关于一个SparkSQL条件下推问题的实录,由于刚刚发表了一篇文章(Flink SQL vs Spark SQL),正好对这块理解还是热乎的,所以我作为D君,我也混水摸了一下鱼。
在阅读正文之前,大家再看一眼这幅图,应该会对理解下文有所帮助。

----------------------------------华丽得分割线---------------------------
spark君前段时间组织了一波学习社区,没过几天竟然增加到了人数增加230多个人。
大家在社区里面是互利互助的关系,如果只索取不分享对社区其他小伙伴是不公平的,有很多人入群后,就深度潜水了,这样的话我可能认为这个社区对你没有什么价值,你对这个社区其他成员也没有价值,所以上周末一口气踢掉了60多个人,也全部从知识星球里面也移除了,现在我也懒得踢人了,进入社区也提了提门槛,想进入学习社区必须有平时有总结分享知识点的习惯,先发一篇自己整理的东西,就是平时解决了啥问题,一段话描述问题解决方案和思路,或者看到的什么知识点记录,或者之前收集的一些学习资料,面试资料,大数据或者AI相关的都行,不用很全很完整的东西,只要能看到你认真整理分享的态度就行。
还有另外一个问题就有些人总是习惯于无脑地甩报错截图,能问别人的绝不google,这种人我认为你是对别人时间的不尊重,在社区里面提问题要讲究提问题的艺术:
碰到问题的时候先去google,先尽自己最大能力解决问题,如果解决不了,提问题的时候,说清楚前因后果,详细的描述信息,不要让回答者感觉问题很模棱两可,加上问题的各种前提条件,自己尝试过哪些方案,想要达到什么目标,自己卡住的关键点,抓住重点,不要问太泛太大的问题,这种一般没法回答。
以上都是题外话,这两天有人在社区里面提了一个问题,我觉得可以给大家分享一下:
问题君:
我今天通过pyspark去读取kudu表的数据,然后做了一个filter(pt=20190301 and courier_mobile='xxxxxxx'),在filter的时候由于字段类型错误(本来是pt="123",我错写成pt=123,pt是分区字段,string类型),导致了全表扫描,很久都没跑出来结果
上面这种提问题的方式spark 君觉得也还是ok的,最起码清晰描述出来了问题的基本情况
A君给的建议:
你是想看看你写的程序底层有没有做全表扫描么,可以看执行计划吧
提问君:
我对比下前后两次explain()有什么区别吧
然后过了一会给出了两种不同写法的执行计划
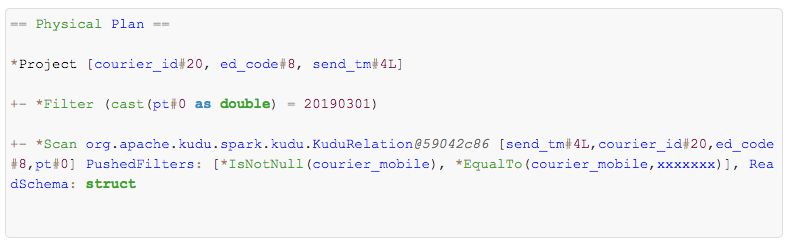
错误情况:
正确情况:
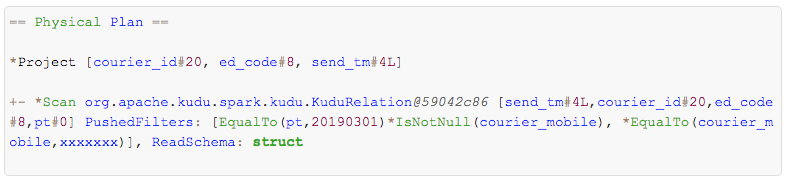
两种的区别好像就是 错误写法的Filter 没有下推到Scan 操作里面,而且Filter的谓词表达式里面多了一个类型转换
C君给的回答:
我记得sparksql的优化中有个东西叫做谓语下移 我想应该是这样的
如果是pt=“sadsa” string与string比较的话 他会优化语法 将 fliter--在sql中有点像where这样的谓语下移到scan表格的时候直接过滤掉 将scan和filter合成一步操作
如果是pt=12311 string与int比较的话 他就不会做优化 会先scan所有 再拿pt的数据转换成int在与12311对比 scan和fliter会分成两步操作
这个只是猜想 你可以考虑下这种情况
D君:
赞成,应该是类型不匹配的时候,优化器没降条件下推,而是自己来过滤了
问题君:
你说的这种情况感觉是符合逻辑的
在错误情况下
1、 想kudu发送命令,依据另一个courier_mobile的条件,从kudu中查询所有数据,这里courier_mobile不是分区字段,kudu里面全表扫描,这一布非常非常慢
2、 spark拿到第一步的结果,在内存里面做filter
C君竟然神奇的搞出来一个图,也不知道从哪来搞来的,还是现成话的,佩服:
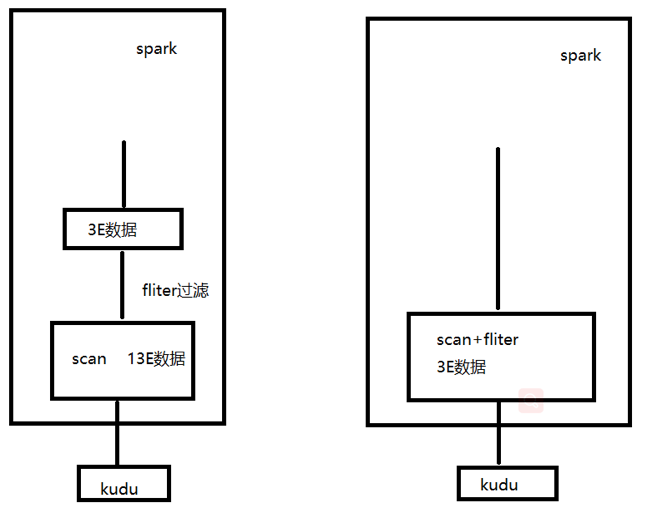
。。。。。
经过一番激烈的讨论,大家达成了一致,就是因为过滤的时候Filter 对比的数据类型,跟数据库kudu中字段的类型不一致,导致字段需要转换,然后这个谓词下推就没法下推的数据库层面去过滤,导致了全表扫描,拉取全部数据,然后在spark这边进行过滤。
这时候spark君本人也来了兴致,开始装逼:
撸了很长时间源码,发现问题出在逻辑执行计划变为物理执行计划这一步
在 DataSourceStrategy类 -> pruneFilterProjectRaw ->selectFilters -> translateFilter 这个方法上面,

这个方法中会对 Filter算子的谓词表达式进行过滤,使用模式匹配,把一些不能下推到数据库的Filter给过滤掉,可以下推的谓词表达式过滤出来,下推到数据库来执行过滤操作
spark 君分分钟写了单测,然后经过漫长的spark源码build过程,debug 发现两种写法传递到这里的谓词表达式果然不同
错误写法: "SELECT a, b FROM test1 WHERE pt = 20190301"
传递到这里的 谓词表达式是: cast(pt#2 as int) = 20190301

正确写法: "SELECT a, b FROM test1 WHERE pt = '20190301'"
传递到这里的 谓词表达式是:(pt#2 = 20190301)

在过滤的模式匹配中只会匹配两种 :
EqualTo(变量,常量)
EqualTo(常量,变量)
所以错误写法被过滤掉,不会下推到数据库去执行过滤
到此为止,一个问题就真相大白了,大家都从中学到了很多东西,棒棒哒


















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











