









 本文详细介绍了MySQL服务的启动、停止和重启命令,以及数据库的创建、查看、修改和删除操作。接着讲解了表的创建、修改和删除,包括字段约束如主键、唯一、非空、默认值和自动增长。此外,还讨论了外键约束、索引的种类和创建方法,以及数据的插入、更新和删除。最后,涵盖了各种数据类型的使用和单表查询、分组查询、多表查询的技巧。
本文详细介绍了MySQL服务的启动、停止和重启命令,以及数据库的创建、查看、修改和删除操作。接着讲解了表的创建、修改和删除,包括字段约束如主键、唯一、非空、默认值和自动增长。此外,还讨论了外键约束、索引的种类和创建方法,以及数据的插入、更新和删除。最后,涵盖了各种数据类型的使用和单表查询、分组查询、多表查询的技巧。
-
mysql服务相关命令
-
启动MySQL服务 命令1
sudo /usr/local/MySQL/support-files/mysql.server start -
停止MySQL服务
sudo /usr/local/mysql/support-files/mysql.server stop -
重启MySQL服务
sudo /usr/local/mysql/support-files/mysql.server restart
-
-
创建数据库
- create database dbname; # dbname为所创建数据库名称
-
查看数据库
- show create database dbname;
-
修改数据库编码
- alter database dbname character set “gbk”
-
删除数据库
- drop databse dbname;
-
创建表
- 语法如下:
create table 表名( 字段名1 字段类型1 [完整性约束], # 注意需要逗号,[]表示optional 字段名2 字段类型2 [完整性约束], ...... 字段名3 字段类型3 [完整性约束] )- 如创建学生信息表student(id, name, gender, age)
create table student( id int(6), name varchar(20), gender varchar(1), age int(2) )- 表的相关操作
- 表的查看:desc tbname;
- 表的详细结构:show create table tbname;
- 修改表名:alter table tbname rename tbname2;
- 修改数据字段类型:alter table tbname modify 列名 新字段类型;
- 修改字段名称及类型:alter table tbname change 旧字段名 新字段名 新字段类型;
- 添加字段:alter table tbname add 字段名 字段类型 [完整性约束] [first | after 字段名] # 最后是指定添加位置
- 删除字段:alter table tbname drop 列名;
- 删除表:drop table tbname;
-
约束
- 主键约束 :列级别约束
create table student( id int(8) primary key, # 列级约束 name varchar(20), age int(2), sex varchar(1) )- 主键约束:表级别约束(多字段组合的主键只能设置在表级别,添加到如下id后面)
create table student( id int(8), name varchar(20), age int(2), constraint pk_student primary key(id) # pk_student是主键约束名- 给已有的表添加主键:alter table xxx add [constraint abc] primary key(id);
- 删除主键:alter table xxx drop primary key;
- 唯一约束:字段值不能重复
create table student( id int(8) unique, # 列级唯一约束 name varchar(20), age int(2), # [constraint uni_student unique(id,) # 表级别唯一约束 )- 给已有的表添加唯一约束:alter table xxx add [constraint abc] unique(id);
- 删除唯一约束:alter table xxx drop index 唯一约束名;没有唯一约束名则取相应字段名;
- 非空约束 :只有列级别的非空约束
create table student( id int(8) not null, name varchar(20), age int(2),- 给已有表添加列级别的非空约束:alter table abc modify name varchar(20) not null;
- 默认值约束
create table student( id int(8), name varchar(20), sex varchar(2) default "man",- 删除默认值约束:alter table abc modify name varchar(20); # 不加即删除
- 自动增长约束:一个表只能有一个自动增长字段;一般配合主键使用
create table student( id int(8) primary key auto_increment, name varchar(20), sex varchar(2),- 外键约束:table A字段A1的值依赖于table B的字段B1的值
- 使用表级添加外键约束
--班级 create table t_class( cno int(8) primary key auto_increment, cname varchar(20) ) create table t_student( cno int(8) primary key auto_increment, cname varchar(20), name varchar(20), age int(2), sex varchar(2), cno_stu int(8), constraint fk_t_student_cno_stu foreign key(cno_stu) references t_class(cno) )- 在已有表中添加外键约束:alter table xxx add [constraint yyy] foreign key(field1) references table2(field2)
- 有外键约束的表如何删除:先删除有约束的表 or 先删除有约束的表的外键;
-
索引
-
目的:实现数据库的快速查询
-
索引的分类
- 普通索引:没有任何要求
- 主键索引:主键字段添加索引,非空且唯一
- 唯一索引:唯一但可以有空值;
- 全文索引:适用于一大串文本添加的索引,只可以给字符串类型添加(char,varchar,text)
- 空间索引:数据类型只能是空间数据,且非空(geometry,point,linestring,polygon)
- 复合索引:多个字段添加的索引,要求查询条件中使用第一个字段;
-
自动创建索引
- 主键约束和唯一约束,mysql会自动创建主键索引和唯一索引
- 查询命令:show index from table_name;
-
手动创建索引
- 创建表时,创建索引
- 创建普通索引、主键索引、唯一索引、全文索引
create table index_student2( sno int(8), sname varchar(20), sloc point not null, unique index(sname), # 创建唯一索引 index(sno), # index|key [索引名][索引类型](字段名[(长度)][asc|dec]) primary key index(sno), # primary key [index|key] [索引名][索引类型](字段名[(长度)][asc|dec]) fulltext index(sname), # fulltext [index|key] [索引名][索引类型](字段名[(长度)][asc|dec]) spatial index(sloc), # spatial [index|key] ... - 创建表后,使用“create index”
- 语法:create [unique|fulltext|spatial] index 索引名称 [索引类型] on 表名(字段名1[(长度)][asc|dec],字段名2[(长度)][asc|dec]…)
- 该方式不能创建主键索引
create tab;e index_stu( sno int(8), sname varchar(20), sloc point not null, -- 空间字段类型,要加非空约束 age int(2), ) -- 创建普通索引 create index index_stu_sno on index_stu(sno) -- 创建唯一索引(全文索引、空间索引类似) create unique index unique_stu_sname on index_stu(sname)- 给已有表添加索引“alter table”
- 语法:alter table 表名 add index|key [索引名] [索引类型] (字段名)
create tab;e index_stu( sno int(8), sname varchar(20), sloc point not null, -- 空间字段类型,要加非空约束 age int(2), ) alter table index_stu add index(sno) - 创建表时,创建索引
-
-
删除索引
- alter table 表名 drop index|key 索引名称
- drop index 索引名称 on 表名(该方法不能删除主键索引)
- 删除主键索引: alter table xxx drop primary key
-
插入数据
- 为所有字段插入数据:insert [into] table_name[(field1, field2,…)] values|value(val1, val2, …);
create table student( sno int(8) primary key auto_increment, sname varch(20) not null, age int(8), sex varchar(1) default "男", email varchar(30) unique ) insert into student(sno, sname, age,sex, email) values(1,"张三",23,"男","zs@163.com");- 指定字段插入数据:大致同上,必须指定字段;
- 使用SET插入数据:insert [into] table_name set field1=val1, field2=val2, …
- 同时插入多条数据:insert [into] table_name[(field1, field2,…)] values|value(val1, val2, …), (val1, val2, …) …;(指定字段自行调整)
- 插入查询结果:insert [into] table1(f1, f2, f3) select f1,f2,f3 from table2 where condition1;
-
更新、删除数据
- 更新:update table1 set filed1=val1, field2=val2 where condition1
- 删除1:delete from table1 where condition1;
- 删除2:truncate table1;
- delete和truncate的区别
- delete支持事务回滚
- delete删除后序号为剩余最大序号,以此累积;truncate只保留表结构,序号重置
-
数据类型
- 浮点数:Double(M,D)–M表示数字总个数,D表示小数位数;注意超过M会报错;M/D默认0,不做约束;
- 定点数:Decimal(M,D),M默认10,D默认0,此时1.23被存储为1
- 日期和时间类型
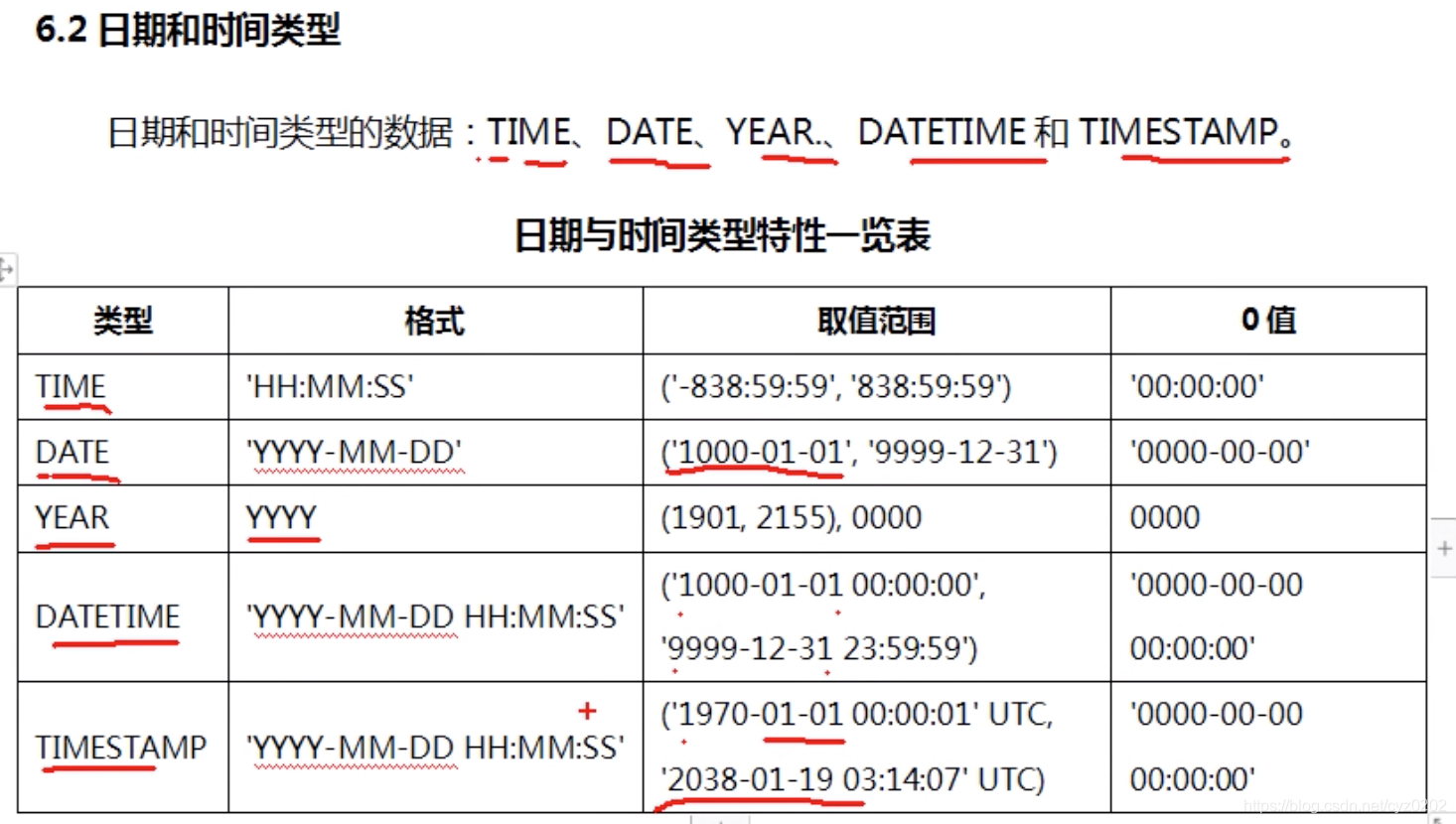
-
字符串类型
- CHAR:定长,右边填充,超出报错
- VARCHAR:变长,不填充,所占空间为输入长度+1,超出报错;一般VARCHAR即可
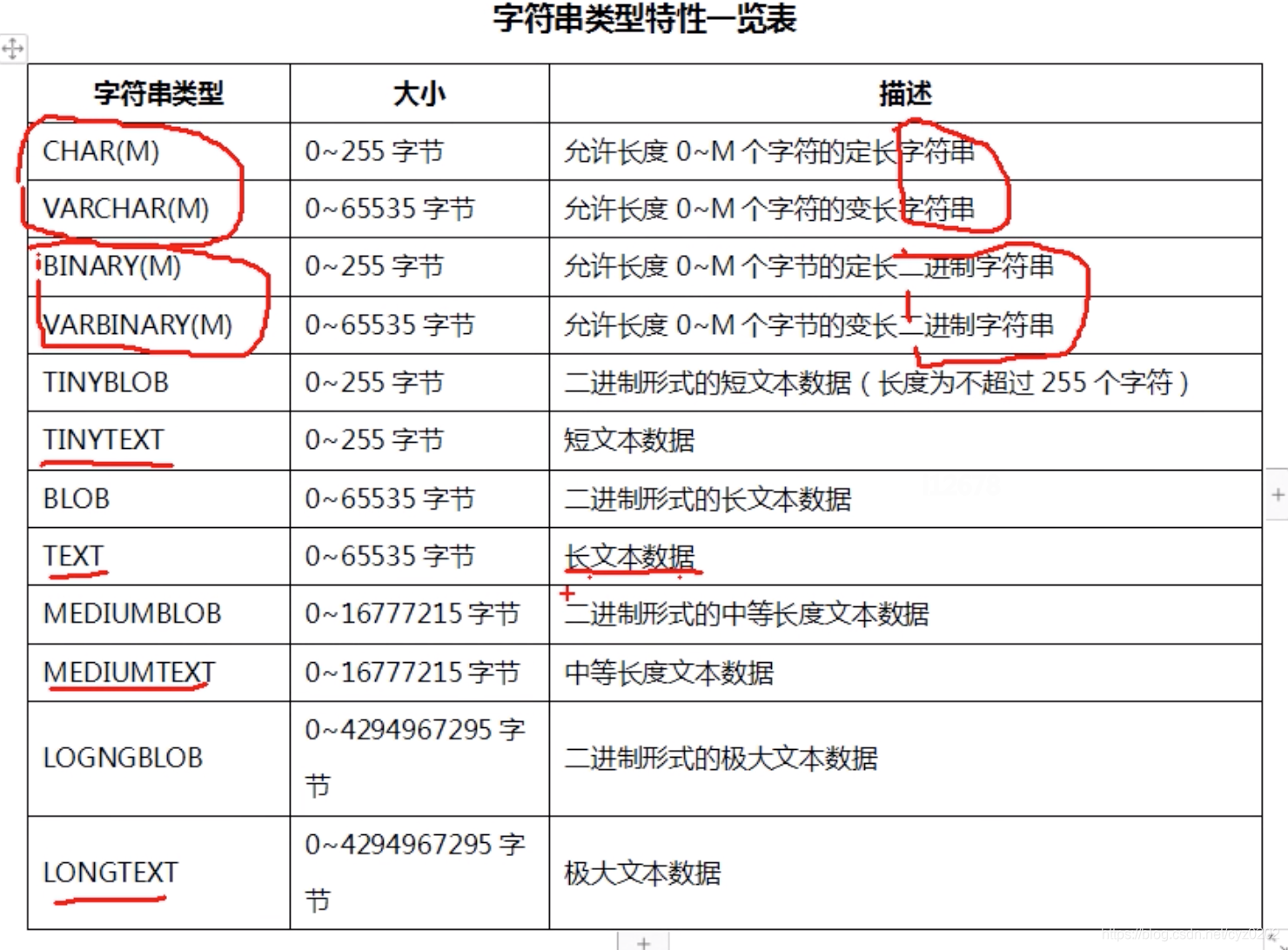
-
ENUM(“val1”, “val2”, …)
-
SET(“val1”, “val2”,…):与ENUM的不同是,可以一次插入多个枚举值的join
-
JSON
create table test_json(
content json
)
insert into test_json values("['aa', 1, 1.1]") # 除了一般kv,还可插入多数据类型数组
-
单表查询
-
去重:select distinct feat1,feat2,… from table_name;
-
设置数据的显示格式:select concat(“name:”, name, “sex:”, sex) [as?] concat_name from tname;
-
排序:select name,sex,salary from tname order by salary [ASC|DESC];
- 多字段排序:select name,sex,salary from tname order by salary ASC, name DESC;
-
条件查询:where xxx
- 区分大小写:where binary ename=“Smith”
- 区间查询:where salary [NOT] between 1500 and 3000;
- IN查询:where name [NOT] in (“abc”, “def”)
- null查询:where name is [NOT] null
- 多条件查询:AND OR
-
模糊查询:where name [NOT] like regular_expression
- "_"表示任意字符 "%"表示任意类型、任意多个
- select * from tbname where name [NOT] like “s%”
- select * from tbname where name like “%a_%” escape “a” # escape指定_要转义
-
limit使用:limit [start_index] count
- select * from tbname where name=“abc” limit 5, 10;
- 分页显示,从第二页开始,需要指定start_index
- 通常与order by 一起使用,先排序后limit分页
-
-
单行函数
-
字符串函数
- concate()
- length()
- lower()
- replace(str, oldstr, newstr): str中的oldstr替换为newstr
- substring(str, index, count)
-
数值函数
- abs()
- ceil()/floor()
- mod(): 10/3=1
- pi(): pi
- pow(m,n): m^n
- rand(): 0~1
- round(num,n): round(3.12345, 2)=3.12
- truncate(num, n)
-
日期时间函数
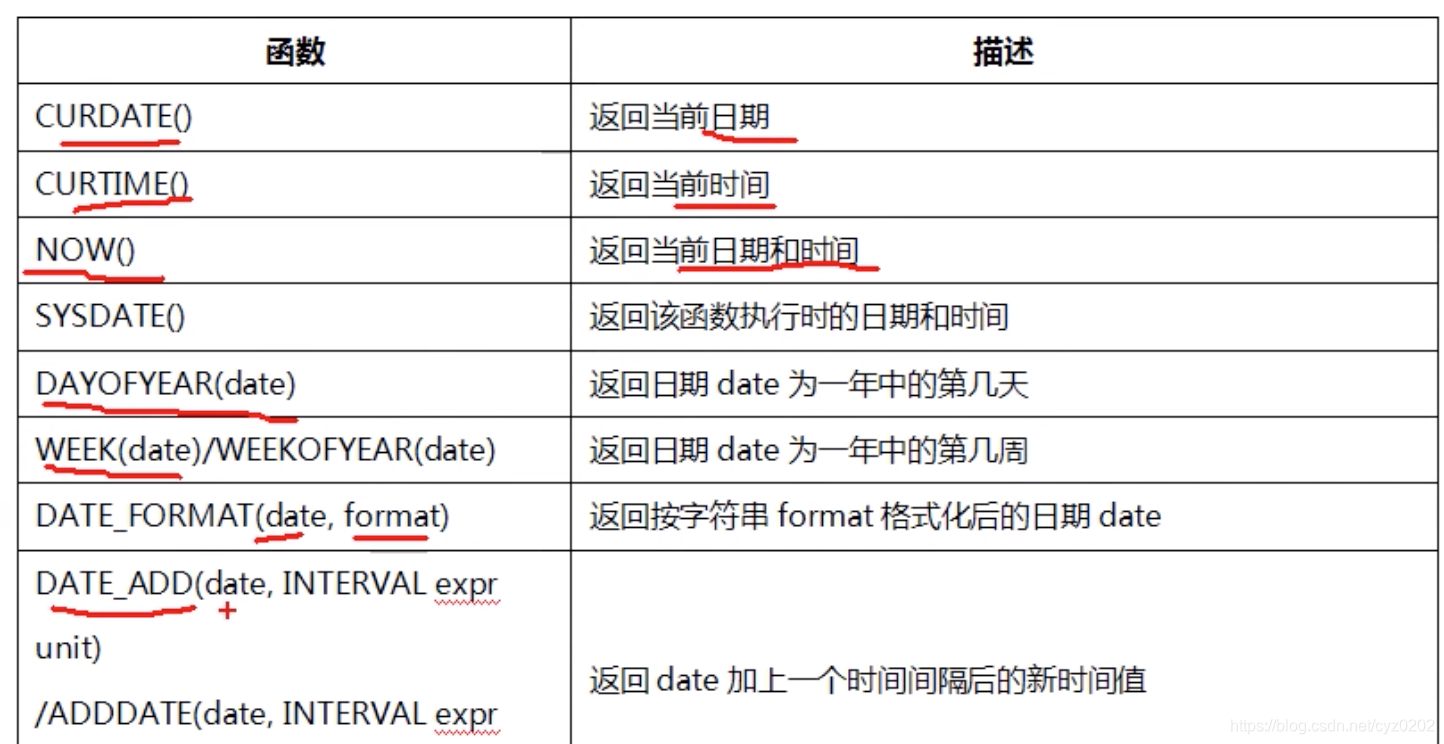
-
流程函数
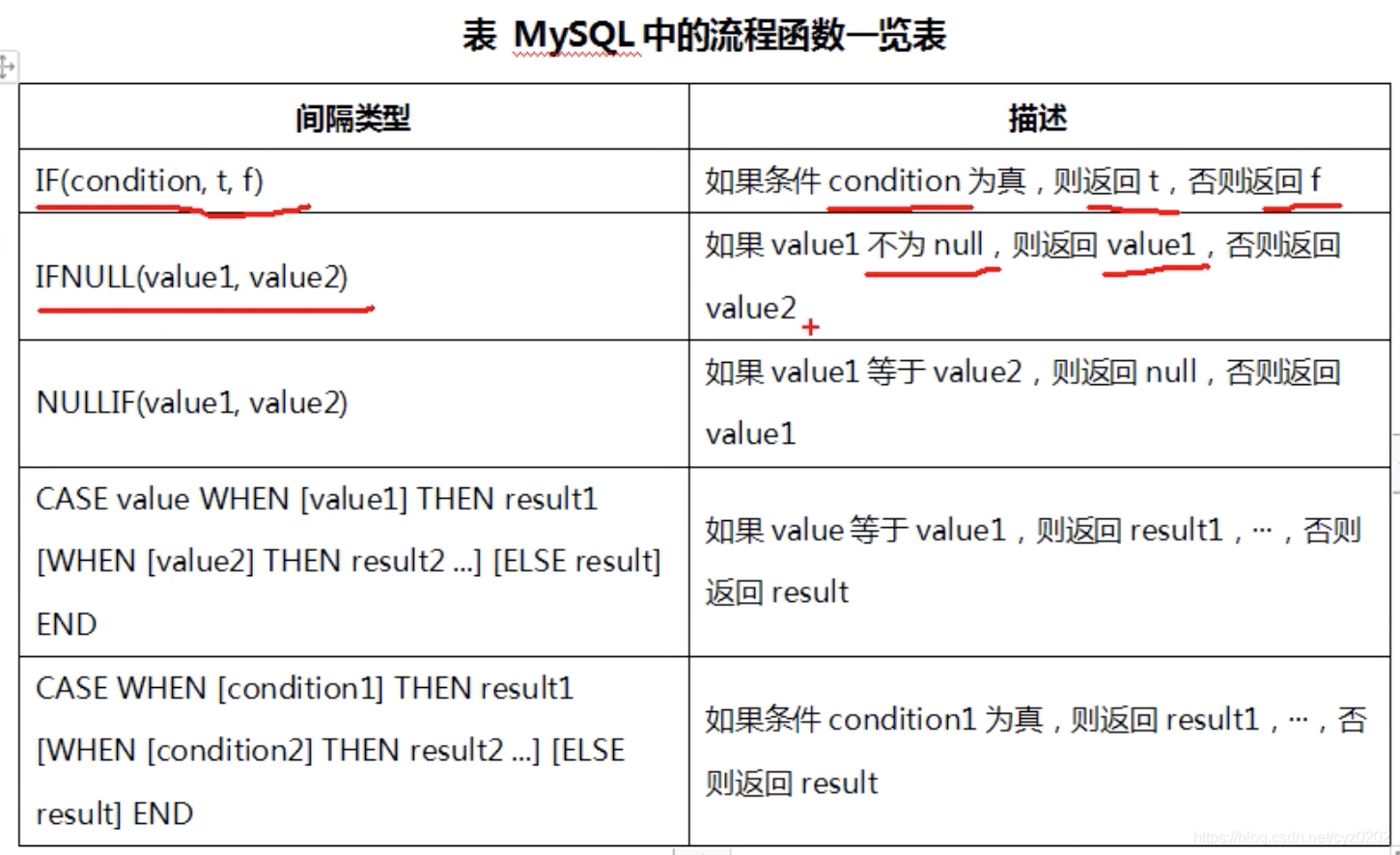
-
多行函数

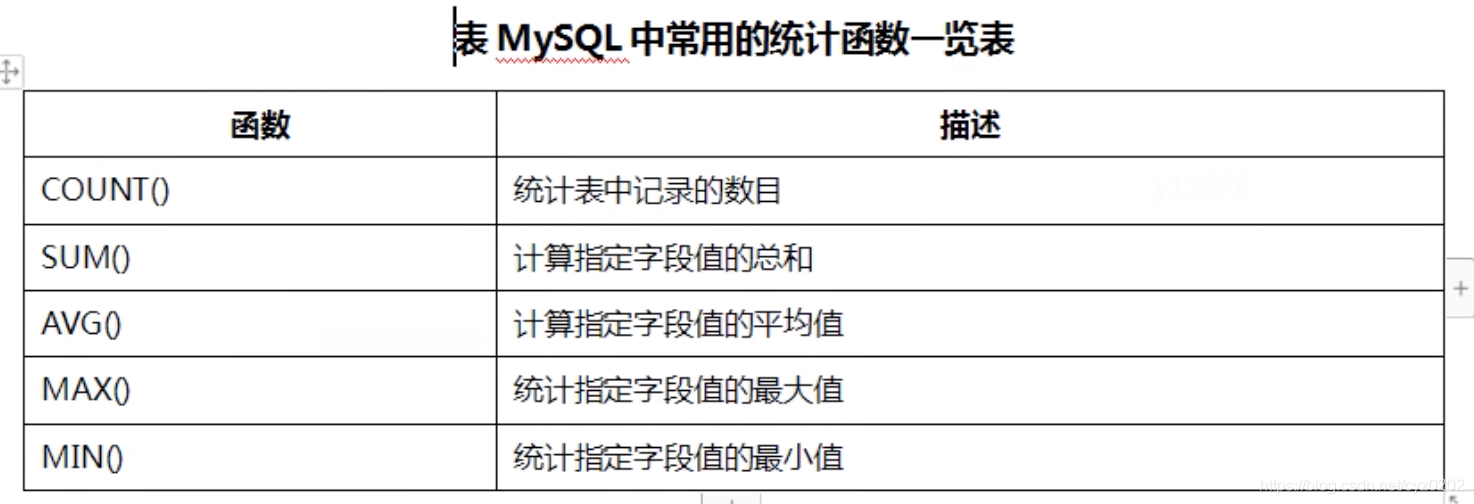
-
分组查询:group by xxx
select deptno, count(*), sum(sal), avg(sal), max(sal) # 分组函数需与deptno有关 from emp where deptno!=10 group by deptno having count(*) > 5 # 分组函数形成的限制条件需在group by后面,以having关键字开始
- 多表查询:依靠主外键
- 交叉连接查询:笛卡尔积查询
- 自然连接查询:
- 内连接查询:
- 外连接查询:左外连接、右外连接(除了相同部分还包括相应左或右部分)
- 子查询 :
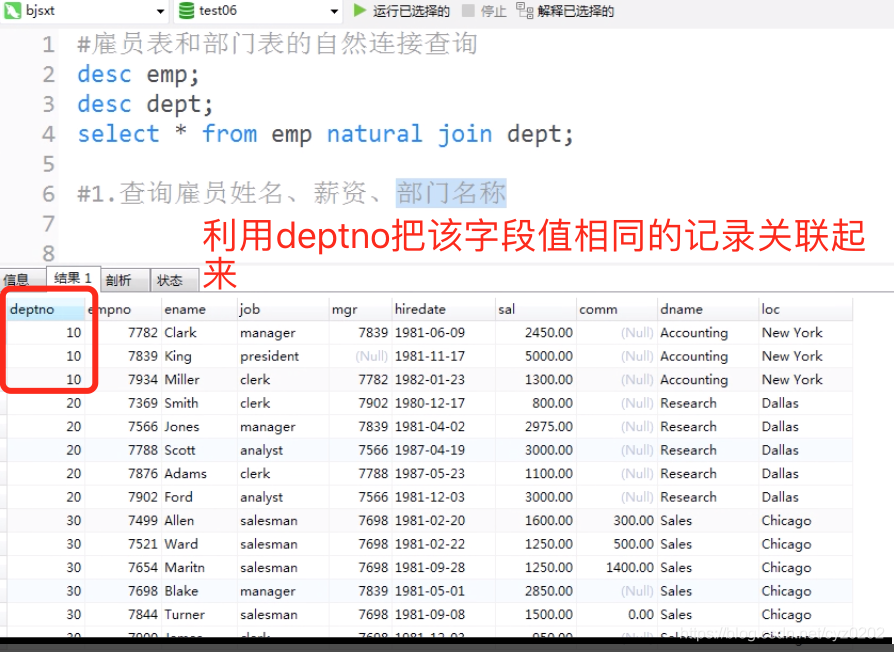
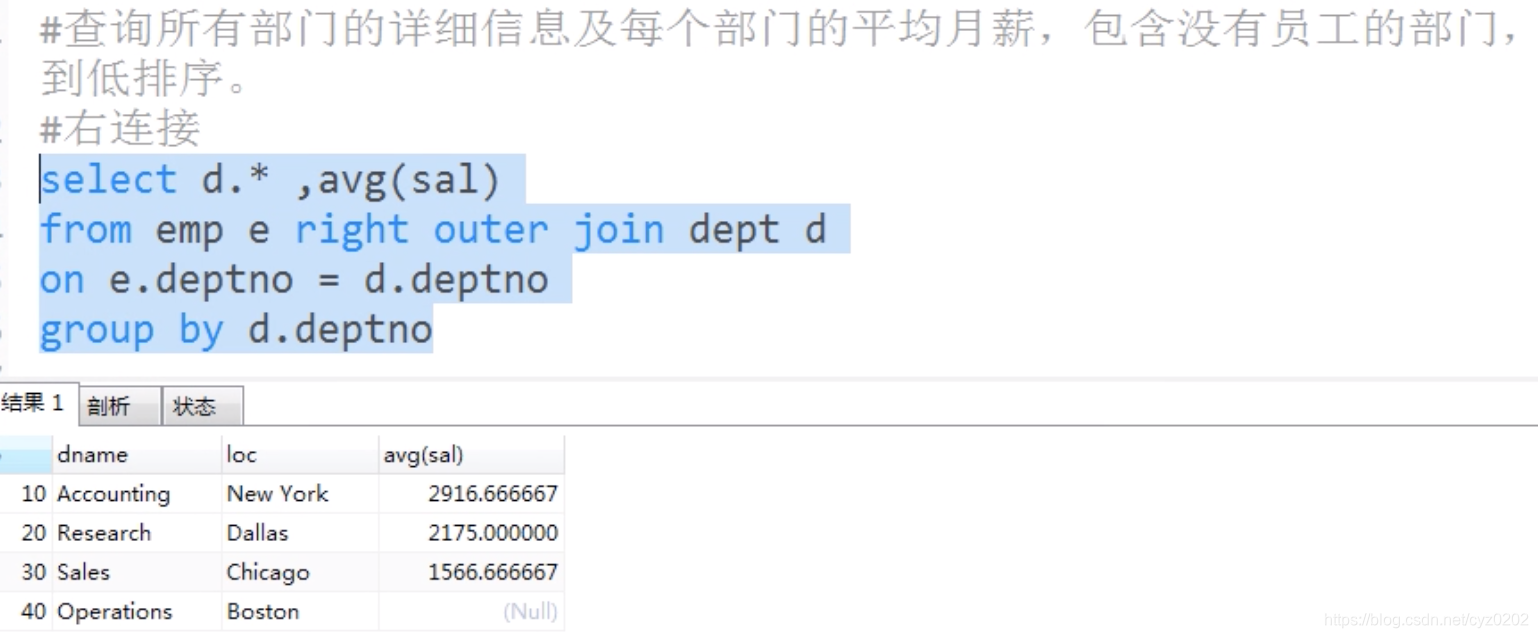
create table dept( deptno int(2) primary key, dname varchar(14), loc varchar(13) ); insert into dept values (10, "Accounting", "new york"), (20, "Research", "Dallas"); create table emp( empno int(4) primary key, ename varchar(10), job varchar(9), mgr int(4), sal decimal(7,2), deptno int(2), constraint fk_deptno foreign key(deptno) references dept(deptno) # 外键关联 ); insert into emp values (7369, "Smith", "clerk", 7902, 800, 20), (7499, "Allen", "salesman", 7698, 1600, 30); -- 交叉连接查询:笛卡尔积 select * from emp cross join dept; -- 自然连接查询:依靠关联字段(主外键),把该字段值相同的记录关联起来; select * from emp natural join dept; -- 内连接:显示符合条件的部分 select empno, ename, sal, e.deptno, dname, loc from emp as e [inner] join dept as d --[]表示可选 on e.deptno=d.deptno --指定关联字段 where d.deptno=20 -- 自连接:一个表连接自身,如下,查询员工及其mgr信息 select e.ename, e.sal, e.mgr, m.ename, m.sal from emp e, emp m -- 同一张表 on e.mgr=m.empno -- 非等值连接:等值连接在条件中使用等号,非等值连接指不使用等号的条件,代码略 -- 外连接查询:outer join,包括左外连接(包括左边所有记录)和右外连接查询(包括右边所有记录); -- 1、左外连接,左表不符合条件的记录也能显示(可用右连接实现) -- 如左表记录 "abc, worker, null, null" 会显示出来,如果用inner join则不显示 select e.ename, e.job, m.ename, m.job from emp e left join emp m on e.mgr=m.empno -- 2、右外连接,右表不符合条件的记录也能显示(可用左连接实现) -- 如 d表有40号部门,但是e表没有,通过右外连接就可以显示40部门情况,而不受限于e表(例子见下图) select d.*, avg(sal) from emp e right join dept d on e.deptno = d.deptno group by d.deptno -- 查询部门编号为30的所有职位的唯一列表,同时显示部门位置,部门号 select distinct e.job from emb e join dept d on e.deptno = d.deptno where e.deptno=30-
自然连接:结果示例,注意与上述sql表内容不完全一样(from itbaizhan)
-
右外连接(例子来自itbaizhan)
-
子查询:从select A返回的结果中select B,如查询工资高于平均工资的人员信息,需要先查询平均工资
-- ###单行子查询### -- 查询emp表中工资比员工“abc”高的员工信息 select * from emp where sal > (select sal from emp where ename="abc") -- 查询职位、部门与员工“abc”一样的员工的信息 select * from emp where (job, deptno)=(select job, deptno from emp where ename="abc") -- ###多行子查询/列子查询### -- 查询工作地点在“abc”/"def"的员工信息,注意工作地点loc在dept表,员工信息在emp表 select * from emp where deptno in (select deptno from dept where loc in ("abc", "def")) -- ANY/SOME关键字的使用 6>any(12,13,5,8) => True -- 查询emp表中员工信息,其工资低于任何一个job=“clerk”的员工的工资 select * from emp where sal < any(select sal from emp where job="clerk") -- 子查询返回多行1列结果 -- ALL关键字的使用,类似于ANY,不再举例 -- ###表子查询### -- 查询emp表中平均月薪最高的部门的编号和平均月薪 select avg(sal), deptno from emp group by deptno having avg(sal) like ( -- 返回float类型值,不能用= select max(avg_sal) -- 标量子查询(无法做到argmax功能) from ( select avg(sal) avg_sal, deptno -- 表子查询 from emp group by deptno ) e_sal ) -- 练习1:查询所有工资高于平均工资的员工的员工号、员工姓名,按工资升序排列 select e.empno, e.ename from emp e where e.sal > ( select avg(m.sal) from emp m ) order by sal -- 练习2:查询员工数不少于4的部门的信息 select d.*, dd.num from dept d, ( select count(*) num, deptno from emp group by deptno having count(*) >= 4 ) dd where d.deptno = dd.deptno -- 练习3:查询入职日期早于其上级的所有员工的编号、姓名、部门名称 select e.empno, e.ename, d.dname from emp e join dept d on e.deptno = d.deptno join emp m on e.mgr = m.empno -- 注意可以多个join where e.hiredate < m.hiredate -- 练习4:查询每个部门的员工数量、部门名称、平均工资和平均服务期限 select count(*), d.dname, avg(sal), avg(DATEDIFF(sysdate(), hiredate)/365) from emp e join dept d on e.deptno=d.deptno group by e.deptno -- 练习5:查询部门名称包含s的部门的员工人数、工资总和 select d.deptno, count(*), sum(sal) from emp e join dept d on e.deptno=d.deptno where d.dname like "%s%" group by e.deptno -

















 35万+
35万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









