




 本文探讨了开集识别任务,将其分为闭集分类和开集识别两个阶段。在闭集训练阶段,使用交叉熵损失训练编码器和分类器。在开集训练阶段,通过条件解码器训练和重建误差的EVT建模,使网络在输入与条件向量不匹配时产生较差的重构,以识别未知类。最后,通过阈值计算确定开放集识别的操作点。
本文探讨了开集识别任务,将其分为闭集分类和开集识别两个阶段。在闭集训练阶段,使用交叉熵损失训练编码器和分类器。在开集训练阶段,通过条件解码器训练和重建误差的EVT建模,使网络在输入与条件向量不匹配时产生较差的重构,以识别未知类。最后,通过阈值计算确定开放集识别的操作点。
原文链接:https://arxiv.org/abs/1904.01198
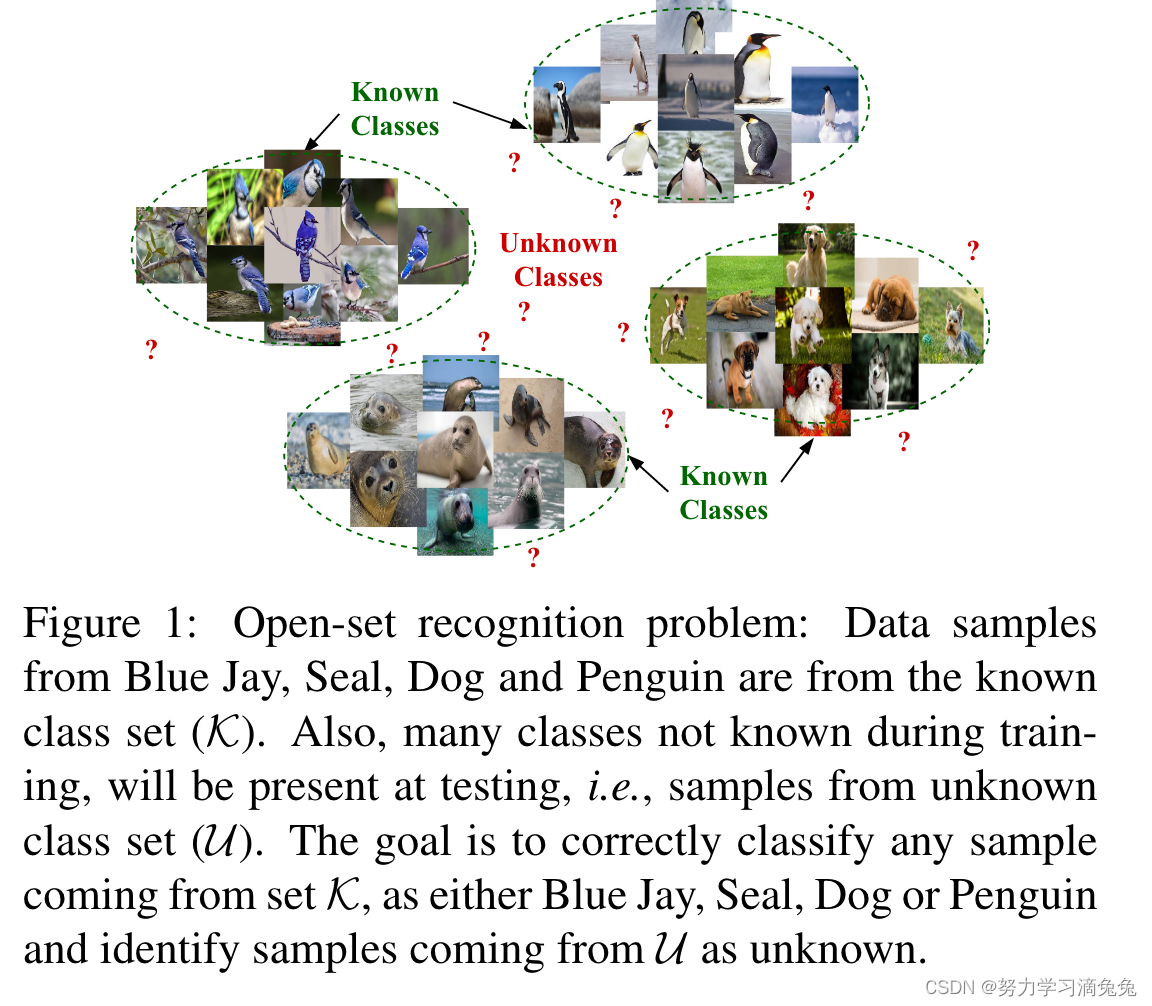
开集识别的一般场景设定如图1所示, 我们已知四类图片,但是在测试过程中,可能会出现不属于任何一类的样本,而开集识别的目标就是识别出未知类,并且对已知类正确分类。
本文将开集识别任务分成了两个子任务:闭集分类和开集识别。训练过程如图2中的1)和2)所示。
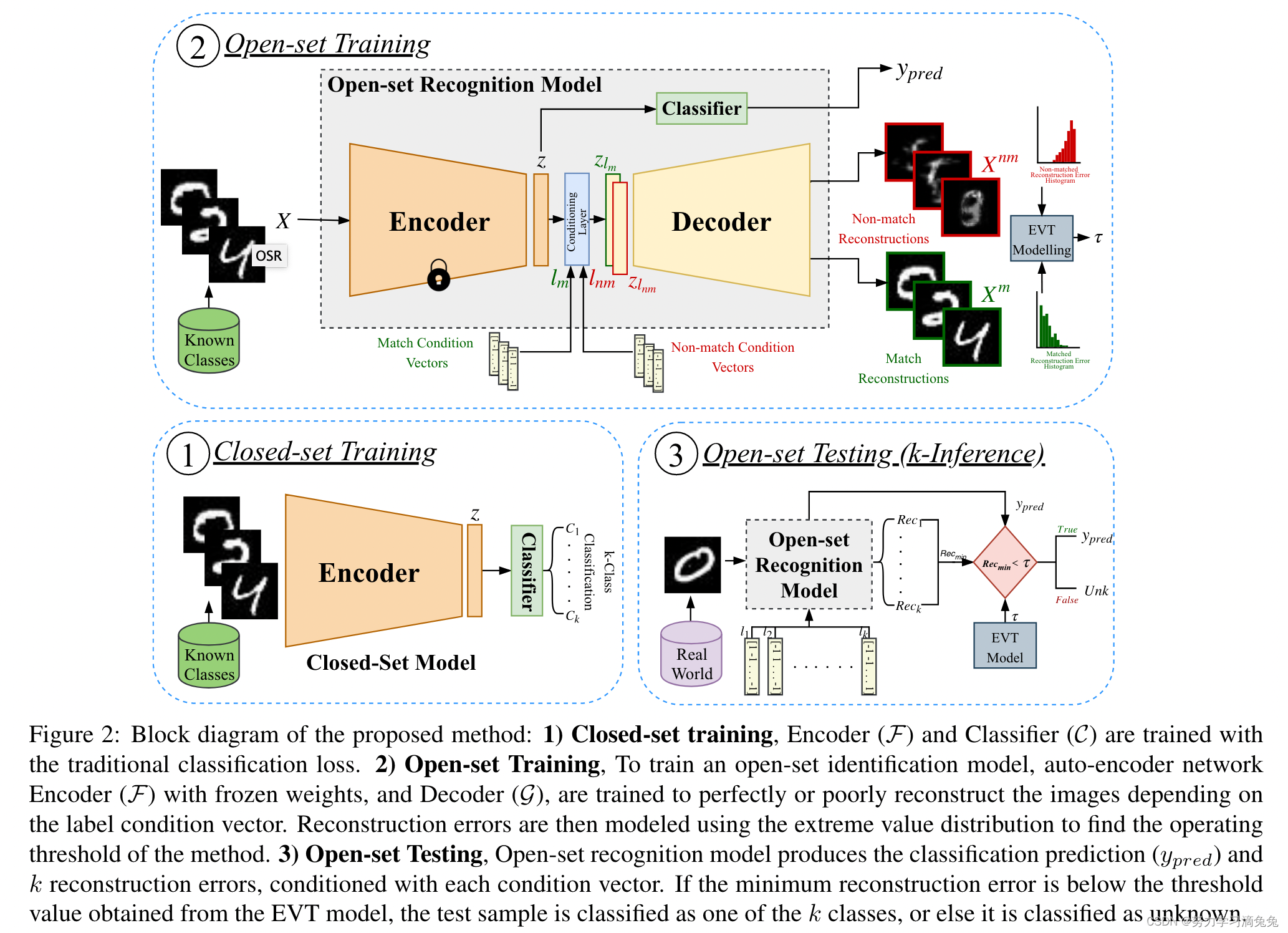
1. Closed-set Training (Stage 1)
给定一个batch的图像,以及相应的标签
。编码器(
)和分类器(
)分别具有参数
和
,使用以下交叉熵损失进行训练,
其中,是标签
的指示函数(即,一个热编码向量),
是预测概率得分向量。
是第i个样本来自第j类的概率。
2. Open-set Training (Stage 2)
在开集训练中有两个主要部分,条件解码器训练,然后是重建误差的EVT建模。在此阶段,编码器和分类器权重是固定的,在优化过程中不会改变。
2.1 Conditional Decoder Training
这里使用了视觉推断的一种方法:FiLM,FiLM层在神经网络的中间层特征上进行一个简单的fe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3831
3831



 到【灌水乐园】发言
到【灌水乐园】发言








