




论文原文:https://arxiv.org/abs/2005.13713
本文介绍了一种新的开集元学习算法(PEELER)算法,实验结果表明,PEELER在小样本和大规模识别方面都达到了最先进的开放集识别性能。
1. Introduction
开集识别目前主要的研究是在大规模环境中,使用基于大规模分类器的解决方案。这些尝试通过后处理后验类分布来识别新类,定义一个“拒绝”类,该类使用人工生成的示例或从训练类中采样的示例,或两者的组合进行训练。本文试图将开集识别推广到大规模环境之外:大规模和小样本识别。主要有三个原因:首先,在所有设置下,开集识别都是一个挑战。其次,由于标记数据的稀缺性,小样本开集识别比大规模开集识别更难解决。第三,与开集识别一样,小样本识别的主要挑战是对训练期间看不到的数据做出准确的决策。由于这使得稳健性成为少数快照体系结构的主要特征,因此这些体系结构可能也擅长于开放集识别。
在这项工作中,研究了小样本问题的一类流行解决方案的开集性能,称为元学习(ML)。ML方法用情景训练取代了传统的小批量CNN训练。通过对每个类的一个子集和一个子集示例进行随机抽样,生成一个支持和查询集,并对其应用分类损失。这将使分类任务随机化,在每个ML步骤中对嵌入进行优化,从而生成更健壮的嵌入,减少对任何特定类集的过度拟合。我们将这个想法推广到开集识别,通过在每集中随机选择一组新类,并引入一个损失,使这些类的示例的后验熵最大化。这迫使嵌入更好地解释看不见的类,在目标类区域之外产生高熵后验分布。此解决方案至少有两大好处。首先,因为它利用了最先进的方法来进行小样本学习,所以它立即将开集识别扩展到小样本问题。其次,由于ML嵌入是鲁棒的,而开集识别是泛化的,因此即使在大规模环境中,后者的性能也会提高。本文还研究了特征空间中使用的度量对开集识别性能的作用,表明特定形式的马氏距离比常用的欧几里德距离具有显著的增益。
本文的贡献如下:
- 一种新的基于ML的开集识别公式。将开集识别推广到小样本。
- 将交叉熵损失和一种新的开集损失相结合,以提高开集在大规模和小样本环境下的性能
- 一种基于高斯嵌入的ML开集识别算法。
2. Related Work
开集识别:开集识别解决的是一种测试时可能面对来自训练过程中看不到的类的样本的问题场景,目标是赋予开集分类器拒绝此类样本的机制。最早的深度学习方法之一是Scheirer等人的工作,该工作为分类器生成的Logit提出了一种极值参数再分配方法。后来的工作在分类模型或生成模型中考虑了这个问题。Schlachter等人提出了一种类内分割方法,其中使用闭集分类器将数据分割为典型和非典型子集,将开放集识别重新表述为一个传统的分类问题。G-OpenMax利用一个经过训练的生成器,从一个表示所有未知类的额外类中合成示例。Neal等人引入了反事实图像生成,其目的是生成无法分类到任何可见类的样本,为分类器训练生成额外的类。
所有这些方法都将看不见的类集减少为一个额外的类。虽然开放样本可以从不同类别中提取,并且具有显著的视觉差异,但他们假设特征提取器可以将它们全部映射到单个特征空间簇中。虽然理论上可能,但这很困难。相反,我们允许按可见类进行聚类,并将不属于这些集群的样本标记为不可见。我们相信这是一种更自然的方法来检测看不见的类。
分布外检测:与开集识别类似的问题是检测分布外(OOD)检测。通常,这是从不同的数据集检测样本,即不同于用于训练模型的分布。虽然[9]通过直接使用softmax分数解决了这个问题,但后来的工作通过提高可靠性来改进结果。这个问题不同于开集识别,因为OOD样本不一定来自看不见的类。例如,它们可能是seen类样本的扰动版本,这在对抗性攻击文献中很常见。唯一的限制是它们不属于训练分布。通常,这些样本比不可见类的样本更容易检测。在文献中,它们往往是来自其他数据集的类,甚至是噪声图像。这与开集识别不同,在开集识别中,看不见的类往往来自同一个数据集。
小样本学习:近年来出现了关于少镜头学习的广泛研究。这些方法大致可分为两个分支:基于优化和基于度量的方法。基于优化的方法通过展开反向传播过程来处理泛化问题。具体而言,Ravi等人提出了一个学习者模块,该模块经过培训可以更新到新任务。MAML及其变体提出了一种训练程序,其中参数根据二级梯度计算的损失进行更新。基于度量的方法试图比较支持样本和查询样本之间的特征相似度。Vinyals等人引入了片段训练的概念,其中训练程序旨在模拟测试阶段,该阶段与余弦距离一起用于训练循环网络。原型网络通过结合度量学习和交叉熵损失,引入了从支持集特征构建的类原型。关系网络利用神经网络隐式地探索了一对支持和查询特征之间的关系,而不是直接在特征空间上构建度量。
3. Classification tasks and meta Learning
在本节中,讨论了不同的分类设置和元学习,为在大规模和小样本设置下提出的开集识别解决方案提供基础。
3.1 Classification settings
Softmax classification
最常用的对象识别和图像分类深度学习架构是softmax分类器。这包括映射图像的嵌入到特征向量
,由多个神经网络层实现,softmax层具有线性映射,用于估计类后验概率
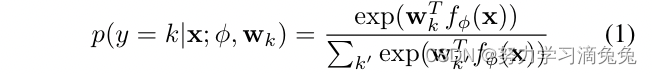
其中表示所有嵌入参数,
是一组分类器权重向量。最近的工作将度量学习与softmax分类相结合,使用距离函数实现softmax层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 942
942






 到【灌水乐园】发言
到【灌水乐园】发言







