







 本文探讨了如何利用用户行为数据提升推荐系统效果,重点介绍了UserCF、ItemCF及LFM算法,分析了它们的工作原理、优缺点及应用场景。
本文探讨了如何利用用户行为数据提升推荐系统效果,重点介绍了UserCF、ItemCF及LFM算法,分析了它们的工作原理、优缺点及应用场景。
利用用户行为数据
这一章的题目是利用用户行为数据,简而言之呢就是来探讨一下如何利用用户的点击行为、浏览行为等等数据,通过用户之间的关联,物品与物品之间的关联,来达到推荐系统的目的。主要介绍了UserCF、ItemCF这两个比较常见的算法,进而介绍了LFM以及LFM的改进。然后对他们进行了对比。
啤酒和尿布
上来就介绍了啤酒和尿布这个经典的不能再经典的故事,讲的是妇女要在家里照顾孩子,爸爸要出去买尿布,然后商家就在尿布旁边放上了啤酒,所以爸爸们买尿布的时候就会顺便买啤酒(这得多贪喝,有点扯但是话糙理不糙)。
用户行为数据简介
用户行为数据在网站上最简单的存在形式就是日志,也就是常见的log形式。比如在搜索引擎和搜索广告系统中,服务会为每次查询生成一个展示日志,其中记录了查询和返回的结果…总而言之,互联网之下,你没有隐私,你的一举一动都在你的Log里面。当然这也为后来的推荐系统利用你的行为提供了可能。
用户行为在个性化推荐系统中一般分为两类,分别是显性反馈行为和隐性反馈行为。
所谓显性反馈行为就是说用户明确对物品的喜好的行为,最简单的解释就是评分或者评价喜欢不喜欢。
而隐性反馈行为呢,指的是那些不能够明确反映用户喜好的行为。最具有代表性的就是网页浏览记录。因为你点击了一个网页并不代表你喜欢这个网页,可能是这个网页在首页推荐给你而你恰好点进去而已。。。。

按照反馈的方向,又可以分为正反馈和负反馈两类。
正反馈就是说用户喜欢该物品,负反馈就是说用户不喜欢。
用户行为分析
用户活跃度和物品流行度的分析
很多关于互联网数据的研究发现,互联网上的很多数据分布都满足一种称为Power Law的分布,这个分布在互联网领域也称长尾分布。
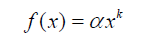
长尾分布其实很早就被统计学家注意到了。1932年,哈佛大学的语言学家Zipf在研究英文单
词的词频时发现,如果将单词出现的频率按照由高到低排列,则每个单词出现的频率和它在热门排行榜中排名的常数次幂成反比。这个分布称为Zipf定律。这个现象表明,在英文中大部分词的
词频其实很低,只有很少的词被经常使用。很多研究人员发现,用户行为数据也蕴含着这种规律。令fu(k)为对k个物品产生过行为的用户数,令fi(k)为被k个用户产生过行为的物品数。那么,fu(k)和fi(k)都满足长尾分布。也就是说: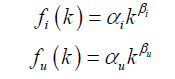
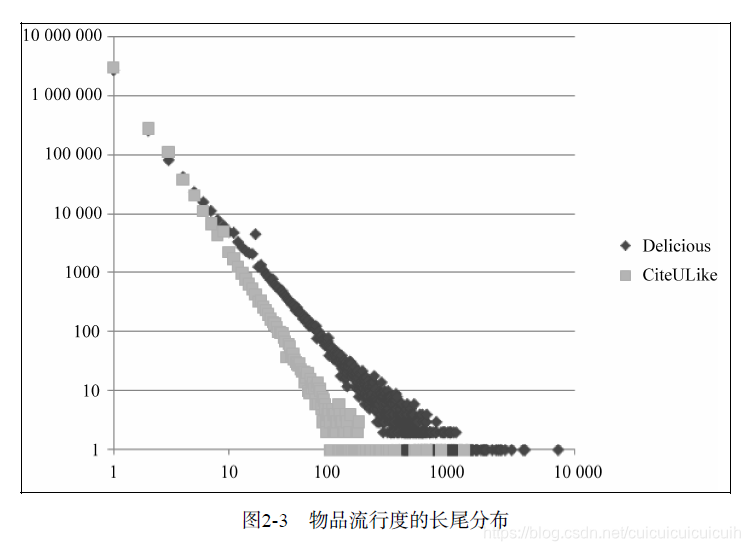
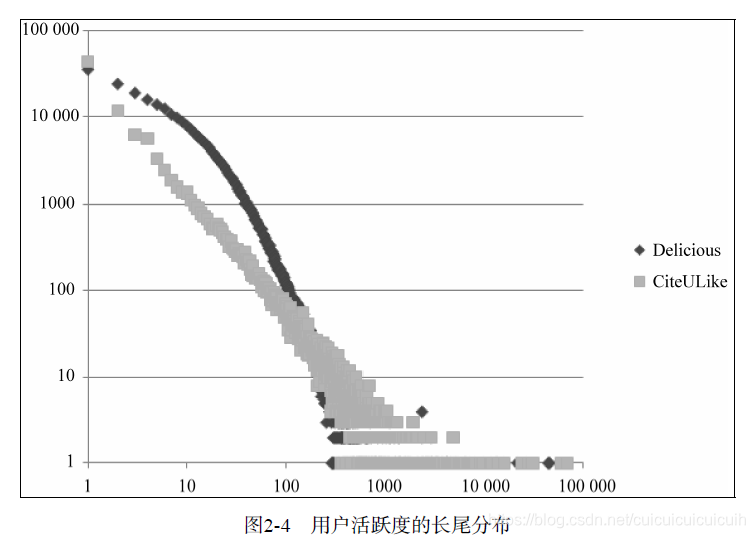
这两幅图都是双对数曲线,而长尾分布在双对数曲线上应该呈直线。这两幅图中的曲线都呈近似直线的形状,从而证明不管是物品的流行度还是用户的活跃度,都近似于长尾分布,特别是物品流行度的双对数曲线,非常接近直线。
用户活跃度和物品流行度的关系
这里就提到了一个很重要的知识了,也就是协同过滤。
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法。学术界对协同过滤算法进行了深入研究,提出了很多方法,比如基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph)等。在这些方法中,最著名的、在业界得到最广泛应用的算法是基于邻域的方法,而基于邻域的方法主要包含下面两种算法。
1、基于用户的协同过滤算法 这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
2、基于物品的协同过滤算法 这种算法给用户推荐和他之前喜欢的物品相似的物品。
评测指标
这里用到了之前提到的准确率和召回率。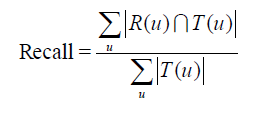
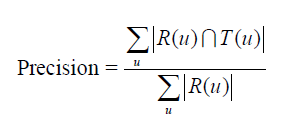
对用户u推荐N个物品(记为R(u)),令用户u在测试集上喜欢的物品集合为T(u),然后可以通过准确率/召回率评测推荐算法的精度。简单理解下,召回率就是 每个用户推荐的物品与用户u在测试集上喜欢的物品集合的交集/u在测试集上喜欢的物品集合
而准确率呢,说的就是你给我的物品 交 测试集上我喜欢的物品集合 /你退给我的所有物品。如果说准确率高了,那么就说明你推给我的大多数都是测试集上我喜欢的。
后面介绍了一个覆盖率,也就是说如果所有的物品都被推荐给至少一个用户,那么覆盖率就是100%
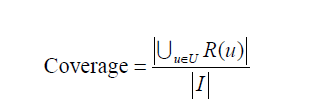
基于邻域的算法
基于邻域的算法包括两种,一种是基于用户的协同过滤算法,一种是基于物品的协同过滤算法。
基于用户的协同过滤算法
这个算法比较古老了,不夸张的说这个算法的诞生意味着推荐系统的诞生了。
书上有个例子:每年新学期开始,刚进实验室的师弟总会问师兄相似的问题,比如“我应该买什么专业书啊”、“我应该看什么论文啊”等。这个时候,师兄一般会给他们做出一些推荐。这就是现实中个性化推荐的一种例子。在这个例子中,师弟可能会请教很多师兄,然后做出最终的判断。师弟之所以请教师兄,一方面是因为他们有社会关系,互相认识且信任对方,但更主要的原因是师兄和师弟有共同的研究领域和兴趣。那么,在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
基于用户的协同过滤算法主要包括两个步骤。
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户v曾经有过正反馈的物品集合。
那么,我们可以通过如下的Jaccard公式简单地计算u和v的
兴趣相似度:

或者通过余弦相似度计算:
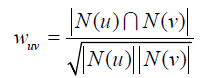
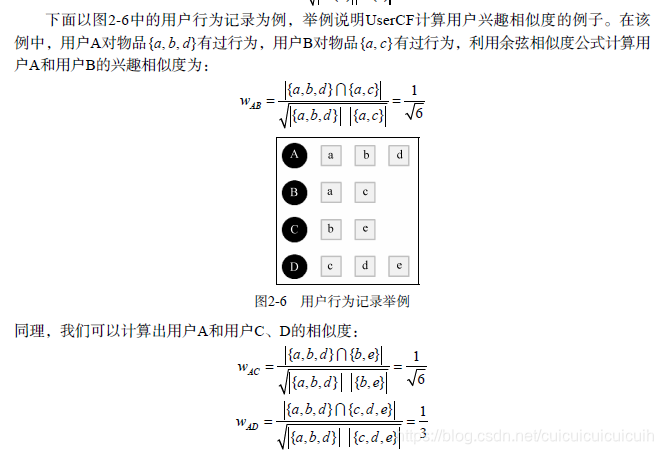
后面介绍了物品-用户的倒排表
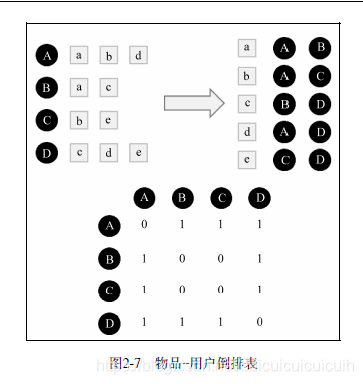
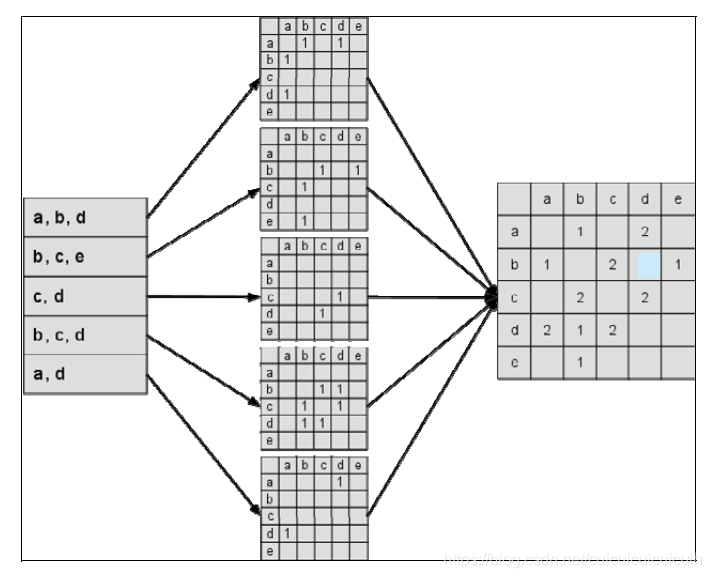
这相当于建立了一个4X4的相似度矩阵W,意思是只要是A和B有喜欢的东西是一样的,就在对应位置+1.比如A喜欢a,B也喜欢a 。W[A][B]和W[B][A]都要+1.
下面就要引出UserCF算法了。首先,UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。如下的公式度量了UserCF算法中用户u对物品i的感兴趣程度:
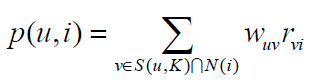
其中,S(u, K)包含和用户u兴趣最接近的K个用户,N(i)是对物品i有过行为的用户集合,wuv是用户u和用户v的兴趣相似度,rvi代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,所以所有的rvi=1。
用户相似度计算的改进
引出了User-IIF算法。因为之前的UserCF算法太过于粗糙了。
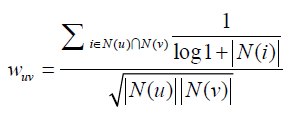
可以看到,该公式通过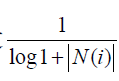 惩罚了用户u和用户v共同兴趣列表中热门物品对他们相
惩罚了用户u和用户v共同兴趣列表中热门物品对他们相
似度的影响。
基于物品的协同过滤算法
基于物品的协同过滤(item-based collaborative filtering)算法是目前业界应用最多的算法。
无论是亚马逊网,还是Netflix、Hulu、YouTube,其推荐算法的基础都是该算法
基于用户的协同过滤算法在一些网站(如Digg)中得到了应用,但该算法有一些缺点。首先,随着网站的用户数目越来越大,计算用户兴趣相似度矩阵将越来越困难,其运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系。其次,基于用户的协同过滤很难对推荐结果作出解释。因此,著名的电子商务公司亚马逊提出了另一个算法——基于物品的协同过滤算法。
基于物品的协同过滤算法(简称ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。比如,该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习》。不过,ItemCF算法并
不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。图2-9展示了亚马逊在iPhone商品界面上提供的与iPhone相关的商品,而相关商品都是购买iPhone的用户也经常购买的其他商品。
基于物品的协同过滤算法主要分为两步。
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户的历史行为给用户生成推荐列表。
如何定义物品的相似度呢?
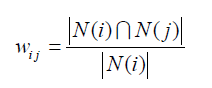
这里,分母|N(i)|是喜欢物品i的用户数,而分子 N(i) N( j) 是同时喜欢物品i和物品j的用户数。因此,上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。
上述公式虽然看起来很有道理,但是却存在一个问题。如果物品j很热门,很多人都喜欢,那么Wij就会很大,接近1。因此,该公式会造成任何物品都会和热门的物品有很大的相似度,这对于致力于挖掘长尾信息的推荐系统来说显然不是一个好的特性。为了避免推荐出热门的物品,可以用下面的公式:
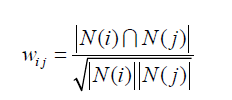
这个公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性
和UserCF算法类似,用ItemCF算法计算物品相似度时也可以首先建立用户—物品倒排表(即对每个用户建立一个包含他喜欢的物品的列表),然后对于每个用户,将他物品列表中的物品两两在共现矩阵C中加1。
在得到物品之间的相似度后,ItemCF通过如下公式计算用户u对一个物品j的兴趣:
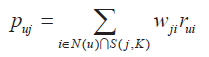
这里N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品的集合,wji是物品j和i的相似度,rui是用户u对物品i的兴趣。(对于隐反馈数据集,如果用户u对物品i有过行为,即可令rui=1。)该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
接下来ItemCF算法也得到了优化-----ItemCF-IUF,即用户活跃度对数的倒数的参数,他也认为活跃用户对物品相似度的贡献应该小于不活跃的用户。
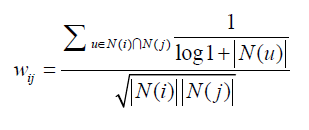
上面的公式只是对活跃用户做了一种软性的惩罚。
物品相似度的归一化
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。
其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w’:
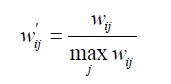
归一化的好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。
为什么要进行归一化呢??
假设物品分为两类——A和B,A类物品之间的相似
度为0.5,B类物品之间的相似度为0.6,而A类物品和B类物品之间的相似度是0.2。在这种情况下,如果一个用户喜欢了5个A类物品和5个B类物品,用ItemCF给他进行推荐,推荐的就都是B类物品,
因为B类物品之间的相似度大。但如果归一化之后,A类物品之间的相似度变成了1,B类物品之间的相似度也是1,那么这种情况下,用户如果喜欢5个A类物品和5个B类物品,那么他的推荐列
表中A类物品和B类物品的数目也应该是大致相等的。从这个例子可以看出,相似度的归一化可以提高推荐的多样性。
UserCF和ItemCF的综合比较

隐语义模型
隐语义模型是最近几年推荐系统领域最为热门的研究话题,它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品。
首先通过一个例子来理解一下这个模型。图2-16展示了两个用户在豆瓣的读书列表。

从他们的阅读列表可以看出,用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书,而用户B的兴趣比较集中在数学和机器学习方面。
那么如何给A和B推荐图书呢?
对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
还有一种方法,可以对书和物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
这个基于兴趣分类的方法大概需要解决3个问题
如何给物品进行分类?
如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
对于一个给定的类,选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在一个类中的权重?
这个方法出现了许多问题,为了解决问题,研究人员提出:为什么我们不从数据出发,自动地找到那些类,然后进行个性化推荐?于是,隐含语义分析技术(latent variable analysis)出现了。隐含语义分析技术采取基于用户行为统计的自动聚类。
接下来以LFM为例介绍隐含语义分析技术在推荐系统中的应用。
LFM通过如下公式计算用户u对物品i的兴趣:
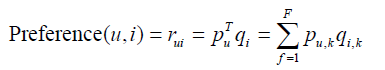
这个公式中 u,k p 和 i,k q 是模型的参数,其中 u,k p 度量了用户u的兴趣和第k个隐类的关系,而i,k q 度量了第k个隐类和物品i之间的关系。
推荐系统的用户行为分为显性反馈和隐性反馈。LFM在显性反馈数据(也就是评分数据)上解决评分预测问题并达到了很好的精度。不过本章主要讨论的是隐性反馈数据集,这种数据集的
特点是只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣)。
那么,在隐性反馈数据集上应用LFM解决TopN推荐的第一个关键问题就是如何给每个用户生成负样本。
对于这个问题,Rong Pan在文章中进行了深入探讨。他对比了如下几种方法。
对于一个用户,用他所有没有过行为的物品作为负样本。
对于一个用户,从他没有过行为的物品中均匀采样出一些物品作为负样本。
对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,保证每个用户的正负样本数目相当。
对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,偏重采样不热门的物品。
对于第一种方法,它的明显缺点是负样本太多,正负样本数目相差悬殊,因而计算复杂度很高,最终结果的精度也很差。对于另外3种方法,Rong Pan在文章中表示第三种好于第二种,而第二种好于第四种。
后来,我们发现对负样本采样时应该遵循以下原则。
对每个用户,要保证正负样本的平衡(数目相似)。
对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
一般认为,很热门而用户却没有行为更加代表用户对这个物品不感兴趣。因为对于冷门的物品,用户可能是压根没在网站中发现这个物品,所以谈不上是否感兴趣。
经过采样,可以得到一个用户—物品集K {(u,i)},其中如果(u, i)是正样本,则有 1 ui r ,否则有0 ui r 。然后,需要优化如下的损失函数来找到最合适的参数p和q:
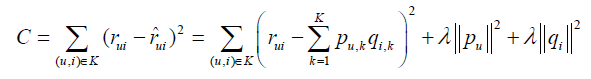
这里,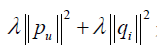 是用来防止过拟合的正则化项,λ可以通过实验获得。
是用来防止过拟合的正则化项,λ可以通过实验获得。
我们通过实验对比了LFM在TopN推荐中的性能。在LFM中,重要的参数有4个:
隐特征的个数F;
学习速率alpha;
正则化参数lambda;
负样本/正样本比例 ratio
随着负样本数目的增加,LFM的准确率和召回率有明显提高。不过当ratio>10以后,准确率和召回率基本就比较稳定了。同时,随着负样本数目的增加,覆盖率不断降低,而推荐结果的流行度不断增加,说明ratio参数控制了推荐算法发掘长尾的能力。
LFM和基于邻域的方法的比较
理论基础 LFM具有比较好的理论基础,它是一种学习方法,通过优化一个设定的指标建立最优的模型。基于邻域的方法更多的是一种基于统计的方法,并没有学习过程。
离线计算的空间复杂度假设是用户相关表,则需要O(MM)的空间,而对于物品相关表,则需要O(NN)的空间。。而LFM在建模过程中,如果是F个隐类,那么它需要的存储空间是O(F*(M+N))
离线计算的时间复杂度假设有M个用户、N个物品、K条用户对物品的行为记录。那么,
UserCF计算用户相关表的时间复杂度是O(N * (K/N)2),而ItemCF计算物品相关表的时间复杂度是O(M*(K/M)2)。而对于LFM,如果用F个隐类,迭代S次,那么它的计算复杂度
是O(K * F * S)。。但总体上,这两种算法在时间复杂度上没有质的差别。
在线实时推荐LFM算法不能进行实时推荐。
基于图的模型
这个就介绍了一个随机游走,《推荐系统与深度学习》里面还介绍了Word2vec,这个在自然语言处理里面也是非常重要的。就不展开了。总之就是想用图中两个顶点之间的关系来衡量一些指标。
下一章是冷启动的问题了,比较简单。

















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









