




 本文综述了Transformer模型在医学影像报告生成领域的应用,包括自动诊断字幕、基于检索与生成结合的方法及多种Transformer变体,如Progressive Transformer、Hierarchical和Meshed-memory Transformer等,旨在提升报告的临床准确性与语言流畅性。
本文综述了Transformer模型在医学影像报告生成领域的应用,包括自动诊断字幕、基于检索与生成结合的方法及多种Transformer变体,如Progressive Transformer、Hierarchical和Meshed-memory Transformer等,旨在提升报告的临床准确性与语言流畅性。
1.Transformers in Medical Imaging: A Survey
综述了Transformers在医学图像分割、检测、分类、重建、合成、配准、临床报告生成和其他任务中的应用。
Shamshad F, Khan S, Zamir S W, et al. Transformers in Medical Imaging: A Survey[J]. arXiv preprint arXiv:2201.09873, 2022. [源码]
2.Methods for automatic generation of radiological reports of chest radiographs: a comprehensive survey
Kaur N, Mittal A, Singh G. Methods for automatic generation of radiological reports of chest radiographs: a comprehensive survey[J]. Multimedia Tools and Applications, 2021: 1-31.
基于编码器-解码器框架的ARRG系统使用编码器从输入图像中提取特征,使用解码器生成与提取的特征对应的语言描述。使用了[编码器]-[解码器]的不同组合,例如[CNN]-[RNN]、[CNN]-[HRNN]、[CNN]-[HRNN带双字LSTM]和[CNN带GLP机制]-[HRNN带主题匹配机制]。基于编码器解码器框架的ARRG系统考虑整个图像以生成输入图像中出现的异常的句子。然而,基于注意机制的ARRG系统关注图像的一部分来生成下一个单词。还指出,同时考虑生成报告的视觉和语义特性可以提高系统的性能。这两类ARRG系统都关注生成句子的可读性,而不是它们的临床相关性。基于强化学习的ARRG系统使用奖励生成具有最大临床相关性的报告。据观察,基于临床疗效和语言质量加强模型比单独考虑提供更好的结果。然而,生成的报告有反复出现的句子。基于图的ARRG系统解决了这个问题。在基于图形的ARRG系统中,人们注意到,在生成报告时,语言模型优于RNN;具体来说,预先训练的语言模型可以提供更好的结果。
3.Diagnostic captioning: a survey
Pavlopoulos J, Kougia V, Androutsopoulos I, et al. Diagnostic captioning: a survey[J]. arXiv preprint arXiv:2101.07299, 2021.
我们提供了诊断字幕(DC)方法、公开数据集和评估措施的广泛概述。
就方法而言,目前大多数DC工作使用编码器-解码器深度学习方法,这主要是因为它们在通用(非医学)图像字幕方面取得了成功。然而,我们已经指出,DC的目标是只报告有助于医疗诊断的信息。如果显示的突出物体(例如身体器官)没有临床上重要的报告,则无需提及,这与一般图像字幕不同,其中突出物体(以及发生的动作)通常必须报告。与普通图像字幕的另一个主要区别是,医学图像的差异小得多,因此,不同患者的相应诊断文本通常非常相似,甚至完全相同。这两个因素使得基于检索的方法在DC中表现得出奇地好,这些方法可以重用来自具有相似图像的训练示例的诊断文本。也可以使用常用句子或句子模板,而不是生成它们。
出于评估目的,DC工作迄今主要依赖于源自机器翻译和摘要的单词重叠度量,而机器翻译和摘要通常无法捕捉临床正确性,正如我们也使用人工示例所证明的那样。还采用了比较标签(也被视为标签或类别,对应于医学术语或概念)的措施,这些标签是手动提取的,或者更常见的是,从系统生成的和人类编写的诊断报告中自动提取的,作为更好地捕捉临床正确性的手段。然而,当自动提取标签的工具不准确,当人类注释指南不清楚应该分配或不分配哪些标签,以及当标签不能完全捕获诊断文本中要包含的信息时,它们也可能失败。人工评估在DC很少见,可能是因为雇佣具有足够医学专业知识的评估人员的难度和成本。
在数据集方面,我们专注于仅有的两个真正代表该任务的公共可用数据集(IU X-RAY、MIMIC-CXR),首先讨论了其他公共可用数据集的严重缺陷(例如,它们可能不包含真实检查的医学图像)。我们还收集并报告了之前发表的所有DC数据集、方法和评估指标的评估结果。尽管由于使用的数据集或分割不同,这些结果通常无法直接进行比较,但它们提供了不同类型DC方法执行情况的总体指示。我们收集的结果也可能帮助其他研究人员得出与之前报道的结果更直接可比的结果。
我们认为,将从头生成诊断文本的编码器-解码器方法与基于检索的方法相结合的混合方法,即重用过去类似案例中的文本的方法,更有可能成功。
4.Deep learning in generating radiology reports: A survey
Monshi M M A, Poon J, Chung V. Deep learning in generating radiology reports: A survey[J]. Artificial Intelligence in Medicine, 2020, 106: 101878.

针对CNN+RNN结构报告生成进行综述。
5.A survey on deep learning and explainability for automatic image-based medical report generation
Messina P, Pino P, Parra D, et al. A survey on deep learning and explainability for automatic image-based medical report generation[J]. arXiv preprint arXiv:2010.10563, 2020.
6.Improving factual completeness and consistency of image-to-text radiology report generation
Miura Y, Zhang Y, Tsai E B, et al. Improving factual completeness and consistency of image-to-text radiology report generation[J]. arXiv preprint arXiv:2010.10042, 2020. [源码]
7.Hierarchical x-ray report generation via pathology tags and multi head attention
Srinivasan P, Thapar D, Bhavsar A, et al. Hierarchical x-ray report generation via pathology tags and multi head attention[C]//Proceedings of the Asian Conference on Computer Vision. 2020. [源码]
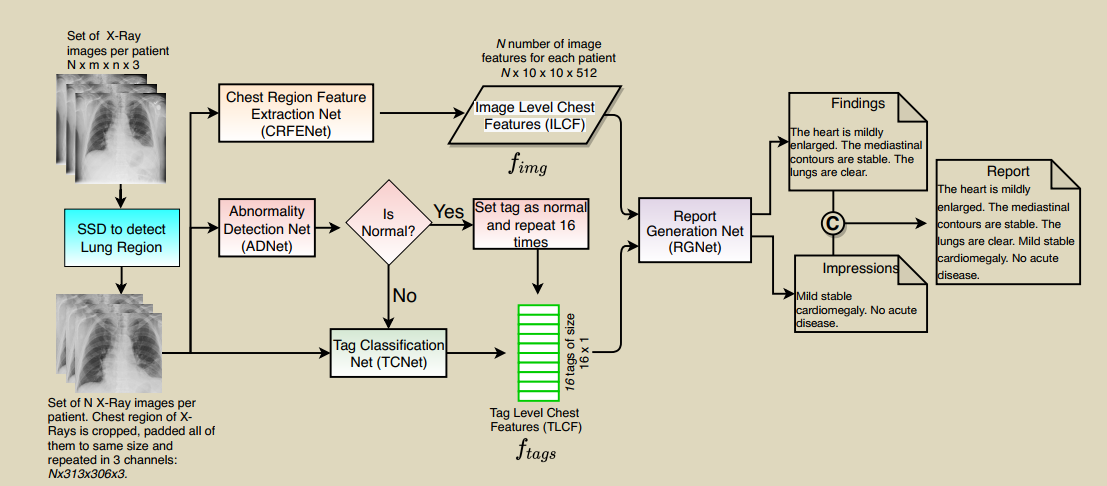
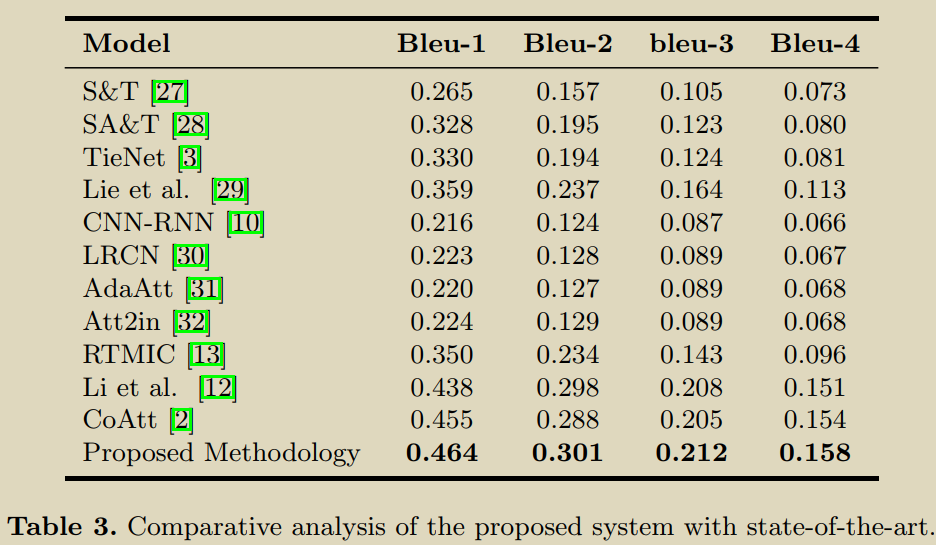
1.采用分治方法。首先,从正常患者中识别出异常患者,并生成其MTI标签嵌入。然后根据标签进行条件学习。2.为了预测报告使用一种包含两个编码器和两个解码器的Transformer。3.标签嵌入和图像特征分别使用两个编码器编码。报告的findings和impressions通过两个堆叠的解码器学习,帮助前者改进后的生成。
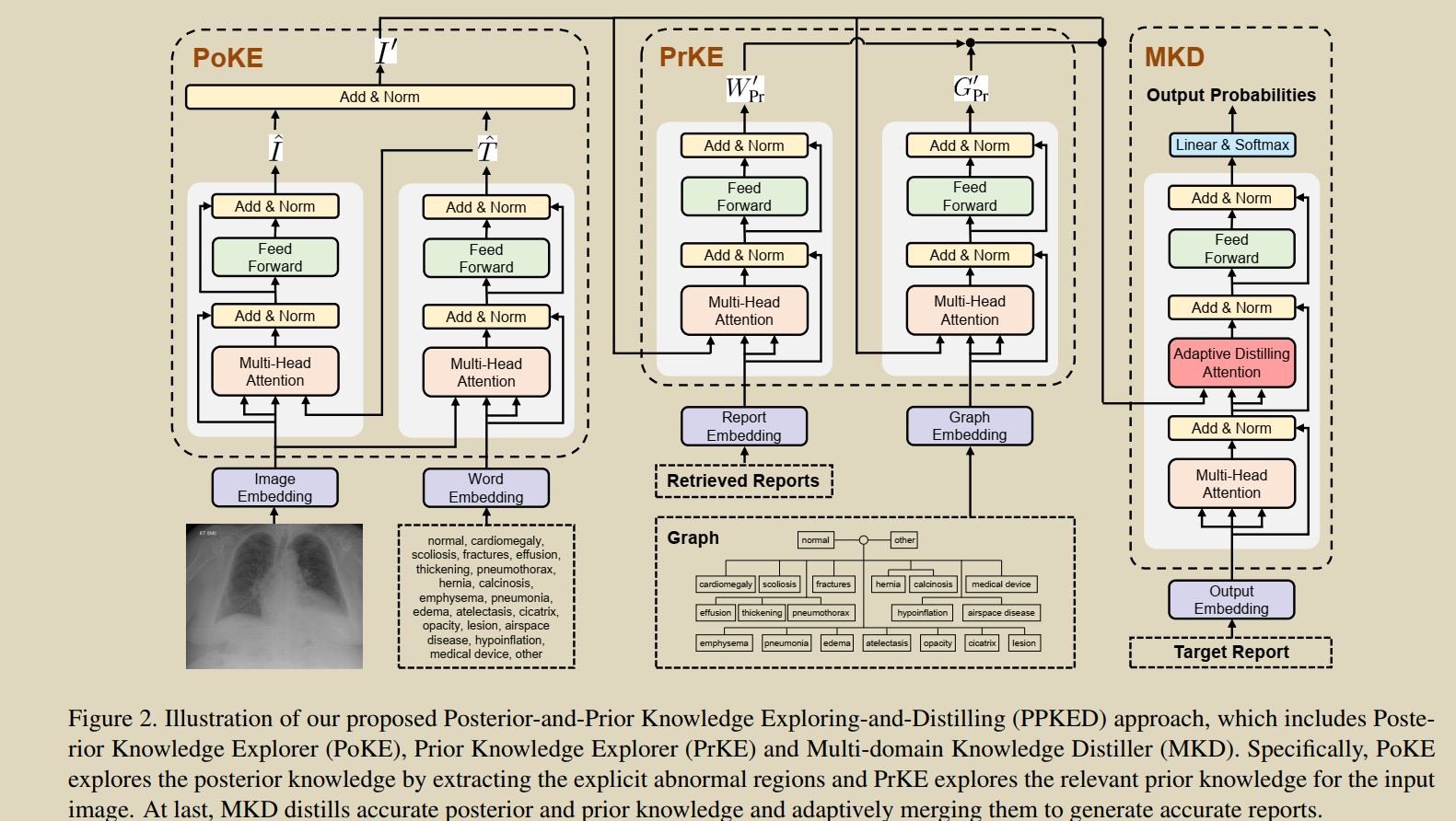
8.Exploring and distilling posterior and prior knowledge for radiology report generation
Liu F, Wu X, Ge S, et al. Exploring and distilling posterior and prior knowledge for radiology report generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13753-13762.
模拟医生先确定异常区域和疾病类型,再利用先验知识进行报告书写的过程。分为: Posterior KnowledgeExplorer (PoKE), Prior Knowledge Explorer (PrKE) 和
Multi-domain Knowledge Distiller (MKD)。PoKE探索了后验知识,提供了显式的异常视觉区域来缓解视觉数据偏倚;PrKE从先前的医学知识图谱中(医学知识)和检索先前的放射学报告(工作经验)中探索先前的知识,以减轻文本数据的偏见。探索的知识被MKD提炼出来生成最终的报告。

a. P o K E : { I , T } → I ′ PoKE : \{I, T\} \rightarrow I^{\prime} PoKE:{ I,T}→I′;
其中: T ^ = FFN ( MHA ( I , T ) ) ; I ^ = FFN ( MHA ( T ^ , I ) ) \hat{T}=\operatorname{FFN}(\operatorname{MHA}(I, T)) ; \hat{I}=\operatorname{FFN}(\operatorname{MHA}(\hat{T}, I)) T^=FFN(MHA(I,T));I^=FFN(MHA(T^,I))
I I I:输入图像 T T T:固定的异常病变(20种)词袋
b. PrKE : { I ′ , W P r } → W P r ′ ; { I ′ , G P r } → G P r ′ \operatorname{PrKE}:\left\{I^{\prime}, W_{\mathrm{Pr}}\right\} \rightarrow W_{\mathrm{Pr}}^{\prime} ; \quad\left\{I^{\prime}, G_{\mathrm{Pr}}\right\} \rightarrow G_{\mathrm{Pr}}^{\prime} PrKE:{ I′,WPr}→WPr′;{ I′,GPr}→GPr′
其中: W Pr ′ W_{\operatorname{Pr}}^{\prime} WPr′and G Pr ′ G_{\operatorname{Pr}}^{\prime} GPr′ which represent the prior knowledge relating to the abnormal regions of the input image .prior knowledge from existing radiology
report corpus and represent them as W Pr W_{\operatorname{Pr}} WPrand G Pr G_{\operatorname{Pr}} GPrrespectively
c. W P r ′ = F F N ( MHA ( I ′ , W P r ) ) G P r ′ = F F N ( MHA ( I ′ , G P r ) ) \begin{aligned} W_{\mathrm{Pr}}^{\prime} &=\mathrm{FFN}\left(\operatorname{MHA}\left(I^{\prime}, W_{\mathrm{Pr}}\right)\right) \\ G_{\mathrm{Pr}}^{\prime} &=\mathrm{FFN}\left(\operatorname{MHA}\left(I^{\prime}, G_{\mathrm{Pr}}\right)\right) \end{aligned} WPr′GPr′=FFN(MHA(I′,WPr))=FFN(MHA(I′,GPr))
d.MKD : { I ′ , W P r ′ , G P r ′ } → R \left\{I^{\prime}, W_{\mathrm{Pr}}^{\prime}, G_{\mathrm{Pr}}^{\prime}\right\} \rightarrow R { I′,WPr′,GPr′}→R.
e.Adaptive Distilling Attention (ADA)
ADA ( h t , I ′ , G P r ′ , W P r ′ ) = MHA ( h t , I ′ + λ 1 G P r ′ + λ 2 W P r ′ ) \operatorname{ADA}\left(h_{t}, I^{\prime}, G_{\mathrm{Pr}}^{\prime}, W_{\mathrm{Pr}}^{\prime}\right)=\operatorname{MHA}\left(h_{t}, I^{\prime}+\lambda_{1} G_{\mathrm{Pr}}^{\prime}+\lambda_{2} W_{\mathrm{Pr}}^{\prime}\right) ADA(ht,I′,GPr′,WPr′)=MHA(ht,I′+λ1GPr′+λ2WPr′)
λ 1 , λ 2 = σ ( h t W h ⊕ ( I ′ W I + G P r ′ W G + W P r ′ W W ) ) \lambda_{1}, \lambda_{2}=\sigma\left(h_{t} \mathrm{~W}_{h} \oplus\left(I^{\prime} \mathrm{W}_{I}+G_{\mathrm{Pr}}^{\prime} \mathrm{W}_{G}+W_{\mathrm{Pr}}^{\prime} \mathrm{W}_{W}\right)\right) λ1,λ2=σ(ht Wh⊕(I
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7927
7927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









