



 本书通过轻松幽默的方式介绍了二分查找算法,解释了其原理和优势,相较于线性查找,二分查找在查找有序列表时能显著提高效率,运行时间为对数时间。书中提供了Python代码示例,帮助读者深入理解算法实现。
本书通过轻松幽默的方式介绍了二分查找算法,解释了其原理和优势,相较于线性查找,二分查找在查找有序列表时能显著提高效率,运行时间为对数时间。书中提供了Python代码示例,帮助读者深入理解算法实现。


普通程序员,不学算法,也可以成为大神吗?对不起,这个,绝对不可以。
可是算法好难啊~~看两页书就想睡觉……所以就不学了吗?就一直当普通程序员吗?
如果有一本算法书,看着很轻松……又有代码示例……又有讲解……
怎么会有那样的书呢?哎呀,最好学了算法人还能变得很萌……
这个……要求是不是太高了呀?哈哈,有的书真的能满足所有这些要求哦!
最近程序员弟弟就买了一本这么个算法书,没两天就寄给了我,说“姐,这本书非常适合你看,太简单啦,必须要看完哦”
他寄的就是这本非常卡通的算法书—《算法图解》。

下面就来给大家分享一下书籍里是怎么讲二分查找这个知识点的。
二分查找
假设要在电话簿中找一个名字以K打头的人,(现在谁还用电话簿!)可以从头开始翻页,直到进入以K打头的部分。但你很可能不这样做,而是从中间开始,因为你知道以K打头的名字在电话簿中间。

又假设要在字典中找一个以O打头的单词,你也将从中间附近开始。
现在假设你登录Facebook。当你这样做时,Facebook必须核实你是否有其网站的账户,因此必须在其数据库中查找你的用户名。如果你的用户名为karlmageddon,Facebook可从以A打头的部分开始查找,但更合乎逻辑的做法是从中间开始查找。
这是一个查找问题,在前述所有情况下,都可使用同一种算法来解决问题,这种算法就是二分查找。

二分查找是一种算法,其输入是一个有序的元素列表(必须有序的原因稍后解释)。如果要查找的元素包含在列表中,二分查找返回其位置;否则返回null。
下图是一个例子。

下面的示例说明了二分查找的工作原理。我随便想一个1~100的数字。

你的目标是以最少的次数猜到这个数字。你每次猜测后,我会说小了、大了或对了。
假设你从1开始依次往上猜,猜测过程会是这样。

这是简单查找,更准确的说法是傻找。每次猜测都只能排除一个数字。如果我想的数字是99,你得猜99次才能猜到!
更佳的查找方式
下面是一种更佳的猜法。从50开始。

小了,但排除了一半的数字!至此,你知道1~50都小了。接下来,你猜75。

大了,那余下的数字又排除了一半!使用二分查找时,你猜测的是中间的数字,从而每次都将余下的数字排除一半。接下来,你猜63(50和75中间的数字)。

这就是二分查找,你学习了第一种算法!每次猜测排除的数字个数如下。

不管我心里想的是哪个数字,你在7次之内都能猜到,因为每次猜测都将排除很多数字!
假设你要在字典中查找一个单词,而该字典包含240 000个单词,你认为每种查找最多需要多少步?

如果要查找的单词位于字典末尾,使用简单查找将需要240 000步。使用二分查找时,每次排除一半单词,直到最后只剩下一个单词。

因此,使用二分查找只需18步——少多了!一般而言,对于包含n个元素的列表,用二分查找最多需要log2n步,而简单查找最多需要n步。
对数
你可能不记得什么是对数了,但很可能记得什么是幂。log10100相当于问“将多少个10相乘的结果为100”。答案是两个:10 × 10 = 100。因此,log10100 = 2。对数运算是幂运算的逆运算。
对数是幂运算的逆运算
本书使用大O表示法(稍后介绍)讨论运行时间时,log指的都是log2。使用简单查找法查找元素时,在最糟情况下需要查看每个元素。因此,如果列表包含8个数字,你最多需要检查8个数字。而使用二分查找时,最多需要检查log n个元素。如果列表包含8个元素,你最多需要检查3个元素,因为log 8 = 3(23 = 8)。如果列表包含1024个元素,你最多需要检查10个元素,因为log 1024 = 10(210 =1024)。

下面来看看如何编写执行二分查找的Python代码。这里的代码示例使用了数组。如果你不熟悉数组,也不用担心,下一章就会介绍。你只需知道,可将一系列元素存储在一系列相邻的桶(bucket),即数组中。这些桶从0开始编号:第一个桶的位置为#0,第二个桶为#1,第三个桶为#2,以此类推。
函数binary_search接受一个有序数组和一个元素。如果指定的元素包含在数组中,这个函数将返回其位置。你将跟踪要在其中查找的数组部分——开始时为整个数组。
low = 0high = len(list) - 1

你每次都检查中间的元素。
mid = (low + high) / 2 ←---如果(low + high)不是偶数,Python自动将mid向下取整。guess = list[mid]
如果猜的数字小了,就相应地修改low。
if guess < item: low = mid + 1
如果猜的数字大了,就修改high。完整的代码如下。
def binary_search(list, item): low = 0 (以下2行)low和high用于跟踪要在其中查找的列表部分 high = len(list)—1
while low <= high: ←-------------只要范围没有缩小到只包含一个元素, mid = (low + high) / 2 ←-------------就检查中间的元素 guess = list[mid] if guess == item: ←-------------找到了元素 return mid if guess > item: ←-------------猜的数字大了 high = mid - 1 else: ←---------------------------猜的数字小了 low = mid + 1 return None ←--------------------没有指定的元素
my_list = [1, 3, 5, 7, 9] ←------------来测试一下!print binary_search(my_list, 3) # => 1 ←--------------------别忘了索引从0开始,第二个位置的索引为1print binary_search(my_list, -1) # => None ←--------------------在Python中,None表示空,它意味着没有找到指定的元素
运行时间
每次介绍算法时,我都将讨论其运行时间。一般而言,应选择效率最高的算法,以最大限度地减少运行时间或占用空间。

回到前面的二分查找。使用它可节省多少时间呢?简单查找逐个地检查数字,如果列表包含100个数字,最多需要猜100次。如果列表包含40亿个数字,最多需要猜40亿次。换言之,最多需要猜测的次数与列表长度相同,这被称为线性时间(linear time)。
二分查找则不同。如果列表包含100个元素,最多要猜7次;如果列表包含40亿个数字,最多需猜32次。厉害吧?二分查找的运行时间为对数时间(或log时间)。下表总结了我们发现的情况。
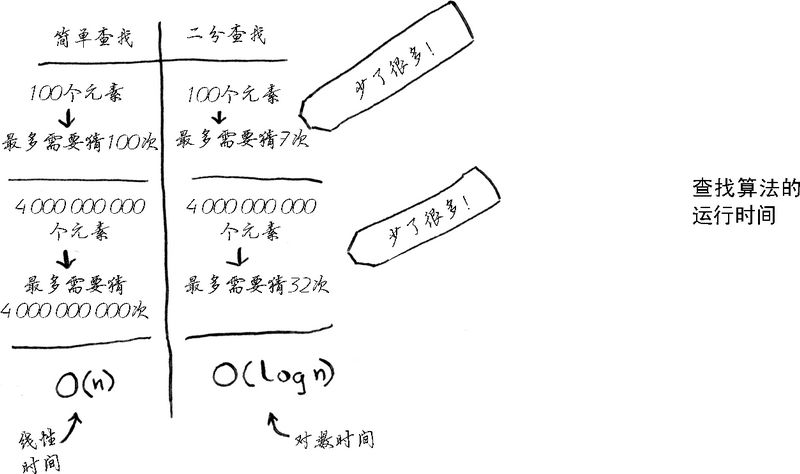
以上内容来自《算法图解》

《算法图解》
扫码查看详情

编辑推荐:
本书示例丰富,图文并茂,以让人容易理解的方式阐释了算法,旨在帮助程序员在日常项目中更好地发挥算法的能量。书中的前三章将帮助你打下基础,带你学习二分查找、大O表示法、两种基本的数据结构以及递归等。余下的篇幅将主要介绍应用广泛的算法,具体内容包括:面对具体问题时的解决技巧,比如,何时采用贪婪算法或动态规划;散列表的应用;图算法;K最近邻算法。
【END】
扫码加入码书群
码书群,是一个可以为你推荐书籍的交流群,在这里,你可以和不同技术的人进行交流,不知道选择什么样的技术书籍学习,也可在群里咨询哦,学习或者工作压力比较大,也可以在群里聊些轻松的话题,也可以在群里咨询物流信息~




















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









