



使用的是Linux服务器环境复现VAD,本人小白,文章内容是学习过程中的记录,供大家参考~
复现步骤
1. 创建虚拟环境
conda create -n vad python=3.8 -y
conda activate vad2. 安装pytorch和gcc
这里使用官方文档的conda install -c omgarcia gcc-5会报错,找不到对应的gcc
考虑到文档中要求的是gcc版本>=5,我这里直接使用conda install -c conda-forge gcc安装的gcc版本为9.,因此直接这样安装了
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install -c conda-forge gcc3. 安装其它包
pip install mmcv-full==1.4.0
pip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
pip install timm
pip install nuscenes-devkit==1.1.94. 克隆VAD包,并进入
git clone https://github.com/hustvl/VAD.git
cd VAD5. 安装mmdet3d
这里使用官方文档里的python setup.py develop报错,于是使用mmdetection3d官方推荐的安装命令pip install -v -e . --default-timeout=3600,参考的是这篇文章自驾小白VAD复现(一)——mmdetection3d编译安装踩坑
# 在刚刚进入的VAD文件夹中
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout -f v0.17.1
pip install -v -e . --default-timeout=36006. 安装requirements.txt里的其它包
一开始没有检查requirements,导致evaluation时报错,发现是缺少similaritymeasures模块导致。于是回来补上requirements里的包。
将requirements.txt文件里的包列举格式改一下(每一行都改成absl-py==1.3.0格式),之后使用批量安装。
pip install -r requirements.txt
安装过程中aidisdk==0.12.0和readline==8.2出现问题,后者进行了单独安装,但只能安到6.2.4.1版本,前者搜不太到,目前还没有安,又一次跑了test.py,看一看能不能跑通。
7. 准备预训练模型
wget用于从网络上下载资源,没有指定目录,下载资源回默认为当前目录。
# 在VAD文件夹下
mkdir ckpts
cd ckpts
wget https://download.pytorch.org/models/resnet50-19c8e357.pth8. 准备数据集
下载nuScenes数据集,并把数据集放在VAD/data/nuscenes目录下,另外需要将nuScenes数据集中的can_bus文件夹单独拿出来放在VAD/data/can_bus目录下
9. 开跑
先尝试跑tiny的e2e
python -m torch.distributed.run --nproc_per_node=8 --master_port=2333 tools/train.py projects/configs/VAD/VAD_tiny_e2e.py --launcher pytorch --deterministic --work-dir outputs修改记录:
① 报错:TypeError: FormatCode() got an unexpected keyword argument 'verify'
将"/home/ps/anaconda3/envs/vad/lib/python3.8/site-packages/mmcv/utils/config.py" 的L496的 text, _ = FormatCode(text, style_config=yapf_style, verify=True) 中的verify参数删除。
② 报错:NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL ,unhandled cuda error, NCCLversion 2.7.8
使用nvidia-smi命令查看了服务其中安装了4个GPU,因此将训练命令改成了单卡训练
③ 报错:AttributeError: module 'distutils' has no attribute 'version'
将 "/home/ps/anaconda3/envs/vad/lib/python3.8/site-packages/torch/utils/tensorboard/__init__.py" 的 “LooseVersion = distutils.version.LooseVersion” 改为 “ from packaging.version import Version as LooseVersion ”
10. 直接使用预训练参数进行评估(这里跑的是VAD_tiny)
自己训练时间太久,因此选择直接使用预训练参数进行evaluation。
要把VAD_tiny_e2e.py中的L14-15改为
img_norm_cfg = dict(
mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)在readme.md的model里下载VAD_base.pth和VAD_tiny.pth并放在ckpts文件夹下,使用这条命令进行复现
CUDA_VISIBLE_DEVICES=0 python tools/test.py projects/configs/VAD/VAD_tiny_e2e.py ckpts/VAD_tiny.pth --launcher none --eval bbox --tmpdir tmp
报错记录:
① 报错:AttributeError: 'numpy.int64' object has no attribute 'intersects',参考Issue#29,安装Shapely即可解决
pip install Shapely=1.8.5② 之前还有一个报错,没有及时记录,记不太清了
结果: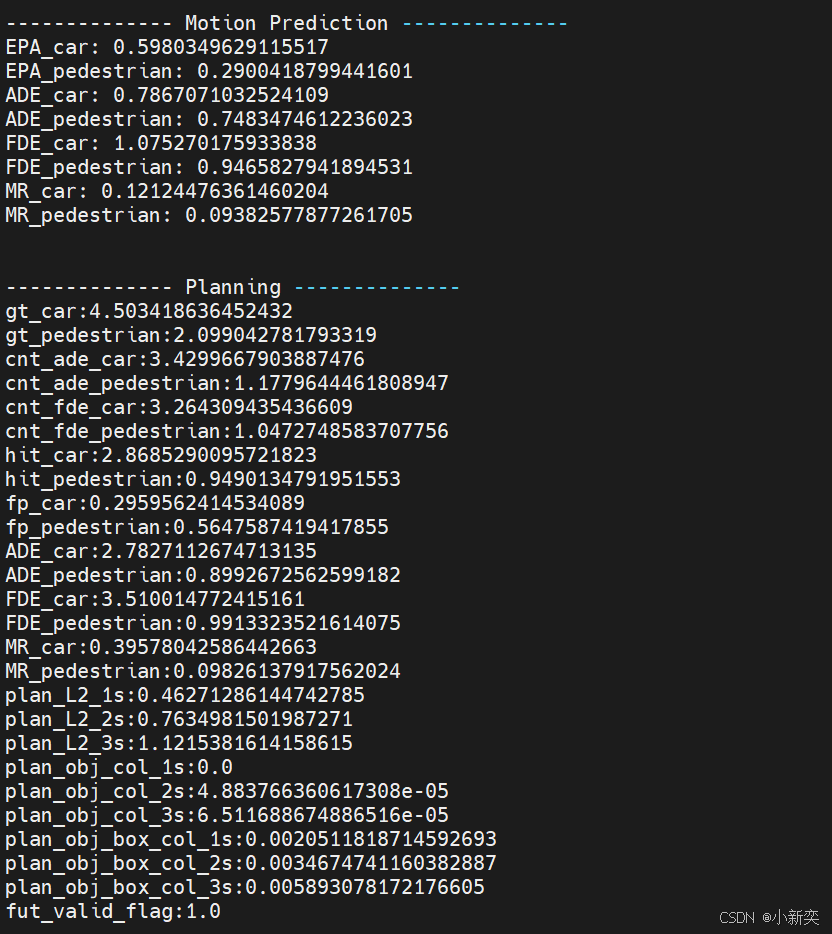
与论文中的数据基本一致
命令记录
关于文件的操作
TIPS:./或什么也不加表示相对路径,从当前文件夹开始算;/开头则为绝对路径
权限不够时在命令前面加sudo
创建文件夹
mkdir 文件夹名删除文件
# 删除文件
rm 文件名
# 删除文件夹
rm -r 文件夹名复制文件
新文件路径如果具体到复制的文件,则会按照新给的文件名命名复制后的文件;如果只给到已有文件夹,则复制后的文件文件名称不变(复制文件夹同理)
# 复制文件
cp 原文件路径 新文件路径
#复制文件夹
cp -r 原文件夹路径 新文件夹路径查找文件
# locate会返回整个文件系统带有pattern的文件
locate 文件名/想要查找的内容
# find会返回当前目录(或给定目录下)带有pattern的文件
find -name 想要查找的内容还有很多其它的命令行参数用法,具体参考:Linux locate命令教程 和 Linux下find命令详解
查看某目录信息
ls 目录的路径
# 查看更详细的信息添加-l
ls -l 目录的路径软链接
ln -s [源文件或目录] [目标文件或目录]类似于构造一个超链接,注意软链接具有同步性,一旦在目标位置创建了软链接,源文件和链接文件将保持同步。
其它操作
查看磁盘工作情况
top查看服务器连接GPU情况
nvidia-smiVAD代码阅读
VAD/tools/train.py
完整代码见 VAD/tools/train.py
首先是导入了一堆包,之后设置了命令行参数,整理换行后如下:
def parse_args():
parser = argparse.ArgumentParser(description='Train a detector')
parser.add_argument('config', help='train config file path')
parser.add_argument('--work-dir', help='the dir to save logs and models')
parser.add_argument('--resume-from', help='the checkpoint file to resume from')
parser.add_argument('--no-validate', action='store_true', help='whether not to evaluate the checkpoint during training')
group_gpus = parser.add_mutually_exclusive_group()
group_gpus.add_argument('--gpus', type=int, help='number of gpus to use (only applicable to non-distributed training)')
group_gpus.add_argument('--gpu-ids', type=int, nargs='+', help='ids of gpus to use (only applicable to non-distributed training)')
parser.add_argument('--seed', type=int, default=0, help='random seed')
parser.add_argument('--deterministic', action='store_true', help='whether to set deterministic options for CUDNN backend.')
parser.add_argument('--options', nargs='+', action=DictAction, help='override some settings in the used config')
parser.add_argument('--cfg-options', nargs='+', action=DictAction, help='override some settings in the used config')
parser.add_argument('--launcher', choices=['none', 'pytorch', 'slurm', 'mpi'], default='none', help='job launcher')
parser.add_argument('--local_rank', type=int, default=0)
parser.add_argument('--autoscale-lr', action='store_true', help='automatically scale lr with the number of gpus')
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
if args.options and args.cfg_options:
raise ValueError('--options and --cfg-options cannot be both specified, --options is deprecated in favor of --cfg-options')
if args.options:
warnings.warn('--options is deprecated in favor of --cfg-options')
args.cfg_options = args.options
return args此处 train_eval.md 中的训练指令为
python -m torch.distributed.run --nproc_per_node=8 --master_port=2333
tools/train.py projects/configs/VAD/VAD_base.py --launcher pytorch
--deterministic --work-dir path/to/save/outputs
从tools/train.py开始真正调取train.py中定义的命令行参数,projects/configs/VAD/VAD_base.py是必须包含的config文件,后续代码中的config都是指它。我们这里使用VAD_base_e2e.py作为config文件进行后续解读,见 VAD/projects/configs/VAD/VAD_base_e2e.py 。
main函数里大段的是对命令行参数的解读,不仔细看了,因为主要是想了解一下模型到底是怎么训练的。
L111完成了config文件的选择和接入
cfg = Config.fromfile(args.config)L222-226完成了build_model,build_model是从 mmdet3d.models 中import的
model = build_model(
cfg.model,
train_cfg=cfg.get('train_cfg'),
test_cfg=cfg.get('test_cfg'))
model.init_weights()后面到L255有一个custom_train_model,是在 VAD/projects/mmdet3d_plugin/VAD/apis/train.py 中定义的,进去看发现用的是.mmdet_train的custom_train_detector。
# VAD/projects/mmdet3d_plugin/VAD/apis/train.py
custom_train_model(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)在同一个目录下打开 VAD/projects/mmdet3d_plugin/VAD/apis/mmdet_train.py 查看 custom_train_detector 的定义。去除掉一些准备工作,主要拎出来三部分:
L51:这一部分使用的是从 projects.mmdet3d_plugin.datasets.builder 中导入的 build_dataloader
# VAD/projects/mmdet3d_plugin/VAD/apis/mmdet_train.py
data_loaders = [
build_dataloader(
ds,
cfg.data.samples_per_gpu,
cfg.data.workers_per_gpu,
# cfg.gpus will be ignored if distributed
len(cfg.gpu_ids),
dist=distributed,
seed=cfg.seed,
shuffler_sampler=cfg.data.shuffler_sampler, # dict(type='DistributedGroupSampler'),
nonshuffler_sampler=cfg.data.nonshuffler_sampler, # dict(type='DistributedSampler'),
) for ds in dataset
]L89-121:构建optimizer和runner,均是从 mmcv.runner 中导入的
# VAD/projects/mmdet3d_plugin/VAD/apis/mmdet_train.py
optimizer = build_optimizer(model, cfg.optimizer)
if 'runner' not in cfg:
cfg.runner = {
'type': 'EpochBasedRunner',
'max_epochs': cfg.total_epochs
}
warnings.warn('config is now expected to have a `runner` section, please set `runner` in your config.', UserWarning)
else:
if 'total_epochs' in cfg:
assert cfg.total_epochs == cfg.runner.max_epochs
if eval_model is not None:
runner = build_runner(
cfg.runner,
default_args=dict(
model=model,
eval_model=eval_model,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta))
else:
runner = build_runner(
cfg.runner,
default_args=dict(
model=model,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta))
L194:用runner的run指令启动训练过程
# VAD/projects/mmdet3d_plugin/VAD/apis/mmdet_train.py
runner.run(data_loaders, cfg.workflow)很好奇build_model是从哪里找到config文件里所谓的type的model的,该方法来自mmdet3d,但追溯过去是mmdet.model.builder里的方法,使用的是Registry机制(并不是很懂这是什么,挖个坑后面写)。
config里面的type都是在注册表中已注册的类,一部分是已经在mmdet.models里面封装好的,另外一部分是自己定义的,比如 'VAD' 和 'VADHead‘ 等,具体目录在projects/mmdet3d_plugin/VAD中,其中在定义的时候有 @DETECTORS.register_module() ,即完成了注册。
下面来根据config文件的内容来拆解模型代码:
VAD/projects/mmdet3d_plugin/VAD/VAD.py
config文件里的model最外面一层是type='VAD',即VAD.py里面的VAD类(该文件里就只定义了这一个类),它是一个MVXTwoStageDetector的子类,注意到其参数中就有img_backbone, img_neck, pts_bbox_head等。
首先看forward函数(在pyTorch中,默认从forward函数开始执行,而无需显式调用),有一个根据return_loss的分支,我们先来看forward_train。
def forward_train(self,
points=None,
img_metas=None,
gt_bboxes_3d=None,
gt_labels_3d=None,
map_gt_bboxes_3d=None,
map_gt_labels_3d=None,
gt_labels=None,
gt_bboxes=None,
img=None,
proposals=None,
gt_bboxes_ignore=None,
map_gt_bboxes_ignore=None,
img_depth=None,
img_mask=None,
ego_his_trajs=None,
ego_fut_trajs=None,
ego_fut_masks=None,
ego_fut_cmd=None,
ego_lcf_feat=None,
gt_attr_labels=None
):
"""Forward training function.
Args:
points (list[torch.Tensor], optional): Points of each sample.
Defaults to None.
img_metas (list[dict], optional): Meta information of each sample.
Defaults to None.
gt_bboxes_3d (list[:obj:`BaseInstance3DBoxes`], optional):
Ground truth 3D boxes. Defaults to None.
gt_labels_3d (list[torch.Tensor], optional): Ground truth labels
of 3D boxes. Defaults to None.
gt_labels (list[torch.Tensor], optional): Ground truth labels
of 2D boxes in images. Defaults to None.
gt_bboxes (list[torch.Tensor], optional): Ground truth 2D boxes in
images. Defaults to None.
img (torch.Tensor optional): Images of each sample with shape
(N, C, H, W). Defaults to None.
proposals ([list[torch.Tensor], optional): Predicted proposals
used for training Fast RCNN. Defaults to None.
gt_bboxes_ignore (list[torch.Tensor], optional): Ground truth
2D boxes in images to be ignored. Defaults to None.
Returns:
dict: Losses of different branches.
"""
len_queue = img.size(1)
prev_img = img[:, :-1, ...]
img = img[:, -1, ...]
prev_img_metas = copy.deepcopy(img_metas)
# prev_bev = self.obtain_history_bev(prev_img, prev_img_metas)
# import pdb;pdb.set_trace()
prev_bev = self.obtain_history_bev(prev_img, prev_img_metas) if len_queue > 1 else None
img_metas = [each[len_queue-1] for each in img_metas]
img_feats = self.extract_feat(img=img, img_metas=img_metas)
losses = dict()
losses_pts = self.forward_pts_train(img_feats, gt_bboxes_3d, gt_labels_3d,
map_gt_bboxes_3d, map_gt_labels_3d, img_metas,
gt_bboxes_ignore, map_gt_bboxes_ignore, prev_bev,
ego_his_trajs=ego_his_trajs, ego_fut_trajs=ego_fut_trajs,
ego_fut_masks=ego_fut_masks, ego_fut_cmd=ego_fut_cmd,
ego_lcf_feat=ego_lcf_feat, gt_attr_labels=gt_attr_labels)
losses.update(losses_pts)
return losses第一部分是对图像的处理和图像元的复制,不详细看了
img_feats = self.extract_feat(img=img, img_metas=img_metas)之后这一行从图像中提取特征,使用了extract_feat函数,extract_feat调用extract_img_feat,来看一下这个函数。
def extract_img_feat(self, img, img_metas, len_queue=None):
"""Extract features of images."""
B = img.size(0)
if img is not None:
# input_shape = img.shape[-2:]
# # update real input shape of each single img
# for img_meta in img_metas:
# img_meta.update(input_shape=input_shape)
if img.dim() == 5 and img.size(0) == 1:
img.squeeze_()
elif img.dim() == 5 and img.size(0) > 1:
B, N, C, H, W = img.size()
img = img.reshape(B * N, C, H, W)
if self.use_grid_mask:
img = self.grid_mask(img)
img_feats = self.img_backbone(img)
if isinstance(img_feats, dict):
img_feats = list(img_feats.values())
else:
return None
if self.with_img_neck:
img_feats = self.img_neck(img_feats)
img_feats_reshaped = []
for img_feat in img_feats:
BN, C, H, W = img_feat.size()
if len_queue is not None:
img_feats_reshaped.append(img_feat.view(int(B/len_queue), len_queue, int(BN / B), C, H, W))
else:
img_feats_reshaped.append(img_feat.view(B, int(BN / B), C, H, W))
return img_feats_reshaped主要就是使用img_backbone和img_neck对图像特征进行了提取,之后又reshape了一下。img_backbone和img_neck在config文件中可以找到,分别使用的是ResNet和FPN,如前面所说的,这两个都是mmdet.models中封装好的,无需自己再定义。
回到forward_train,提取完特征之后开始计算loss,最后返回的也是losses,使用的是forward_pts_train函数。
losses = dict()
losses_pts = self.forward_pts_train(img_feats, gt_bboxes_3d, gt_labels_3d,
map_gt_bboxes_3d, map_gt_labels_3d, img_metas,
gt_bboxes_ignore, map_gt_bboxes_ignore, prev_bev,
ego_his_trajs=ego_his_trajs, ego_fut_trajs=ego_fut_trajs,
ego_fut_masks=ego_fut_masks, ego_fut_cmd=ego_fut_cmd,
ego_lcf_feat=ego_lcf_feat, gt_attr_labels=gt_attr_labels)
losses.update(losses_pts)
return losses来看一看forward_pts_train,发现是调用了两次pts_bbox_head来计算loss,pts_bbos_head在config文件中给出,是VADHead,在VAD_head.py中定义。
def forward_pts_train(self,
pts_feats,
gt_bboxes_3d,
gt_labels_3d,
map_gt_bboxes_3d,
map_gt_labels_3d,
img_metas,
gt_bboxes_ignore=None,
map_gt_bboxes_ignore=None,
prev_bev=None,
ego_his_trajs=None,
ego_fut_trajs=None,
ego_fut_masks=None,
ego_fut_cmd=None,
ego_lcf_feat=None,
gt_attr_labels=None):
"""Forward function'
Args:
pts_feats (list[torch.Tensor]): Features of point cloud branch
gt_bboxes_3d (list[:obj:`BaseInstance3DBoxes`]): Ground truth
boxes for each sample.
gt_labels_3d (list[torch.Tensor]): Ground truth labels for
boxes of each sampole
img_metas (list[dict]): Meta information of samples.
gt_bboxes_ignore (list[torch.Tensor], optional): Ground truth
boxes to be ignored. Defaults to None.
prev_bev (torch.Tensor, optional): BEV features of previous frame.
Returns:
dict: Losses of each branch.
"""
outs = self.pts_bbox_head(pts_feats, img_metas, prev_bev,
ego_his_trajs=ego_his_trajs, ego_lcf_feat=ego_lcf_feat)
loss_inputs = [
gt_bboxes_3d, gt_labels_3d, map_gt_bboxes_3d, map_gt_labels_3d,
outs, ego_fut_trajs, ego_fut_masks, ego_fut_cmd, gt_attr_labels
]
losses = self.pts_bbox_head.loss(*loss_inputs, img_metas=img_metas)
return lossesVAD/projects/mmdet3d_plugin/VAD/VAD_head.py
这是一个大部头啊,有新活儿了,有空接着读,再来这里更新

















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









