






本文来源公众号“数据派THU”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/beeTxfeRmuAR8F_N_aMwLA
当您在对话框中输入“一只戴着宇航员头盔的猫,在火星上追逐一个发光的毛线球”,几十秒后,一段高清、流畅且充满故事感的短视频便诞生了——这不再是科幻电影的桥段,而是当下AI视频生成技术带来的现实。以 Vidu、Sora 等为代表的下一代模型,正在开启一个“想象力直接可视化”的新纪元。

本篇短文将使用简单的语言为您介绍AI视频生成模型背后的数学原理。
核心技术:如何教会AI“理解”并“模拟”动态世界?
与传统的图像生成不同,视频生成的核心挑战在于理解和创造连贯的动态。这背后主要依赖于两大技术支柱:
一. 扩散模型(Diffusion Model):这是当前主流图像和视频生成的“发动机”。其工作原理类似一个“去噪”的学习过程:AI首先学习如何将一张清晰的图片逐步添加噪声,直到变成完全随机的噪点;然后,它再反向学习如何从一堆噪点中,一步步“去噪”并重建出符合文本描述的清晰画面。视频生成则是在此基础上,要求AI在时间和空间两个维度上进行同步“去噪”,从而保证每一帧画面都清晰,且帧与帧之间过渡自然。
在数学上:
扩散过程可以形式化为一个马尔可夫链:
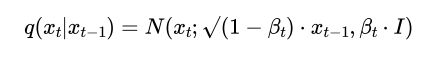
其中x_0是原始数据(清晰的视频帧序列),x_T是纯高斯噪声。β_t是预设的噪声调度参数,控制着每一步添加的噪声量。
逆向过程则是学习如何“去噪”:
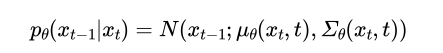
模型需要学习参数θ,以预测在每一步如何从带噪声的数据x_t恢复出更清晰的数据x_{t-1}。
训练目标简化为最小化:
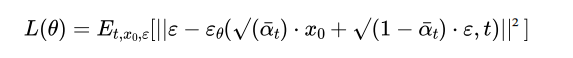
其中ε是随机噪声,ε_θ是模型学习的噪声预测函数。这个看似简单的目标函数——预测添加的噪声——却被证明是学习数据分布p(x_0)的高效途径。
二. Transformer架构:如果说扩散模型是“画笔”,那么Transformer就是理解用户指令并规划绘画步骤的“大脑”。尤其是像Vidu采用的 U-ViT 等创新架构,能够将视频的时空信息(空间上的像素、时间上的帧序列)统一处理,从而更深刻地理解物体运动、物理规律(如重力、流体)和镜头语言(如推拉摇移)。这使得模型生成的视频不再是简单的“动图”,而是具备了初步的物理真实性和电影感。
新一代模型可以说是从“玩具”到“工具”产生了量变到质变的升级,新一代模型之所以引发震动,是因为它们实现了几个关键突破:
1. 时空一致性:早期的AI视频中,物体常常会“闪烁”或变形。新模型能确保主角在整个视频中保持外观稳定,背景也连贯统一。
2. 对物理世界的模拟:AI开始“理解”常识。打碎的杯子不会自动复原,汽车转弯时车身会倾斜,水花的飞溅符合流体力学——这些隐性的知识被编码在模型的参数中。
3. 长视频与复杂叙事:从生成2-4秒的片段,到能够制作长达一分钟、包含多个场景切换和复杂情节的短片,AI正逐步掌握“讲故事”的能力。
在数学上,标准的ViT将图像分割为N个Patch,每个Patch获得一个空间位置编码P_spatial。对于视频,U-ViT引入了联合时空位置编码:
![]()
其中(i, j)是空间坐标,t是时间坐标。
在架构上,ViT长距离依赖建模:通过自注意力机制,模型可以同时关注:
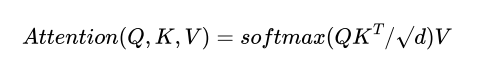
其中Q, K, V包含了所有时空位置的信息,使模型能够理解“狐狸的足迹在前一帧留下,需要在后一帧继续延伸”这样的时空逻辑。
总的来说,AI视频生成模型的背后有着以下的基础要素:
1. 物理规律的隐式学习:当模型在数百万个视频片段上训练时,它通过梯度下降最小化重建损失,实际上在隐式地学习物理规律的统计表征。例如,通过观察足够多的水流动画,模型学习到流体力学的近似解,尽管它并不“知道”纳维尔-斯托克斯方程。
2. 训练数据的“隐式知识库”:模型的能力边界由其训练数据决定。一个优秀的视频生成模型通常在包含数亿视频片段的数据库上训练,这些数据形成了一个高维语义流形。
3. 数学视角上来看所使用的训练数据和要预测生成的数据,即这些所有可能的视频构成了一个极高维的空间(对于16帧的1080p视频,维度超过1亿)。但真实视频只占据这个空间中的一个极低维的流形。扩散模型的训练过程,本质上是学习这个流形的几何结构。
4. 提示词工程的数学解释:当用户输入提示词时,实际上是在这个高维流形中指定了一个“语义子空间”。模型的任务是从这个子空间中采样出最可能的数据点(视频)。这也解释了为什么提示词越精确,生成效果越好——因为子空间的约束更严格,采样更确定。
另一方面,也需要注意到AI视频生成模型的背后有着以下的局限性:
当前模型表现的“物理理解”本质上是统计规律的外推,而非基于第一性原理的物理模拟。例如,当模型生成“玻璃破碎”的场景时,是基于学习的方法:模型回忆起训练数据中数千个玻璃破碎的片段,提取出碎片运动方向、速度分布、反射光变化的统计模式;而并非是基于物理模拟的方法:即需要求解材料应力、断裂力学的偏微分方程组。因此当前模型的优势在于效率极高(推理只需一次前向传播),而劣势在于可能会违反物理定律(尤其在训练数据未覆盖的边缘情况中)。
从信息论角度看,AI视频生成是一个条件熵最小化的过程:
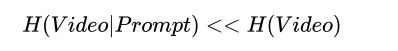
其中H表示熵(不确定性)。好的提示词大幅降低了输出的条件熵,使生成内容更可控。
然而,最佳创作往往发生在确定性与随机性的平衡点上:
完全确定性(温度参数T→0):输出单调、重复
完全随机性(T→∞):输出无意义、混乱
当前研究的核心挑战之一,就是找到这个“创造力甜点”,让模型既能遵循指令,又能产生令人惊喜的合理创新。
展望和审视这项技术时,我们也需要注意到它的价值和风险:
这项技术会带来诸多的便利和变革:
1. 内容创作民主化:个人创作者、小团队能以极低的成本和门槛,制作出以往需要专业团队才能完成的视频素材、动画短片或广告创意。
2. 加速创新循环:电影、游戏、广告的创意可视化将变得即时,大大缩短从灵感到原型的过程。
3.新型交互体验:结合VR/AR,未来我们或许可以凭描述就生成一个沉浸式的虚拟场景进行游览或社交。
然而,随之而来的挑战和风险也同样巨大:深度伪造(Deepfake)带来的信任危机、版权归属的模糊、对传统影视行业就业的冲击,以及能耗问题,都是技术发展路上必须严肃面对的课题。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 5656
5656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









