




本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/hOQOokG56C99kImrsPAWuw

论文链接:https://arxiv.org/pdf/2512.14614
项目链接:https://3d-models.hunyuan.tencent.com/world
demo链接:https://3d.hunyuan.tencent.com/sceneTo3D

亮点直击
WorldPlay,一个针对通用场景的实时、长期一致的世界模型。
双重动作表示:提出了一种结合离散键盘输入和连续摄像机姿态的双重动作表示方法。既实现了对用户输入的鲁棒控制,又提供了精确的空间位置信息,解决了传统方法在控制精度和训练稳定性上的不足。
重建上下文记忆和时间重构:为了解决长期几何一致性的挑战,WorldPlay 引入了重建上下文记忆机制,它动态地从历史帧中重建上下文。
上下文强制:一种新颖的蒸馏方法,旨在解决内存感知模型在实时生成中常见的误差累积和分布不匹配问题。确保了蒸馏过程的有效性,使得学生模型在保持实时速度的同时,能够有效利用长程信息并防止误差漂移。
这些创新共同使得 WorldPlay 能够实现实时、交互式的视频生成,并在长期生成过程中保持卓越的几何一致性。
总结速览
解决的问题
WorldPlay 旨在解决当前实时交互式世界模型中的一个根本性挑战:如何在兼顾实时生成速度的同时,保持长期几何一致性。现有的方法往往难以同时实现这两点,例如,一些方法为了追求速度而牺牲了在场景重访时的一致性,而另一些方法虽然能保持一致性,但由于复杂的内存机制而无法实现实时交互。此外,传统的位置编码在处理长序列时可能导致长程信息衰减和外推伪影,进一步加剧了几何一致性的挑战。
提出的方案
WorldPlay 提出了一个流式视频扩散模型,通过自回归预测未来的视频帧或块,以响应用户输入。其核心方案是利用三项关键创新来解决速度与一致性的权衡问题,确保模型在实时交互中保持长期几何连贯性。
应用的技术
-
双重动作表示 (Dual Action Representation) :结合了离散按键输入(提供鲁棒、适应尺度的运动)和连续摄像机姿态(提供精确空间位置以进行记忆检索),解决了各自方法的局限性。
-
重建上下文记忆 (Reconstituted Context Memory):通过两阶段过程动态重建记忆上下文,包括捕获短期运动的时间记忆和防止长期几何漂移的空间记忆,后者采样自非相邻的过去帧,并由几何相关性分数指导。
-
时间重构 (Temporal Reframing) :针对 RoPE 中远距离 token 影响减弱的问题,该技术动态地为所有上下文帧重新分配位置编码,使其与当前帧保持固定的、小的相对距离,从而使几何重要的过去帧保持影响力。
-
上下文强制 (Context Forcing) :一种专为内存感知模型设计的蒸馏方法。它通过在蒸馏过程中对齐教师模型和学生模型之间的记忆上下文,解决了因分布不匹配导致的性能下降,使得学生模型能在少量步去噪下实现实时生成,同时保持长期记忆并缓解误差累积。
-
分块自回归生成:将全序列视频扩散模型微调为分块自回归模型,以实现无限长交互式生成。
达到的效果
-
实时交互性:能够以24 FPS 的速度生成 720p 的流式视频,实现低延迟的交互式体验。
-
卓越的长期几何一致性:在用户控制和场景重访时,模型能保持场景的连贯性和稳定性,解决了以往模型中常见的几何不一致问题。
-
强大的泛化能力:在多样化的真实世界和风格化世界场景中展现出显著的泛化能力,无论是第一人称还是第三人称视角。
-
多功能应用支持:支持3D重建、文本驱动的动态世界事件触发(可提示事件)以及视频续写等多种应用。
-
解决了误差累积问题:通过上下文强制等机制,有效缓解了自回归模型在长序列生成中常见的误差累积问题。
方法
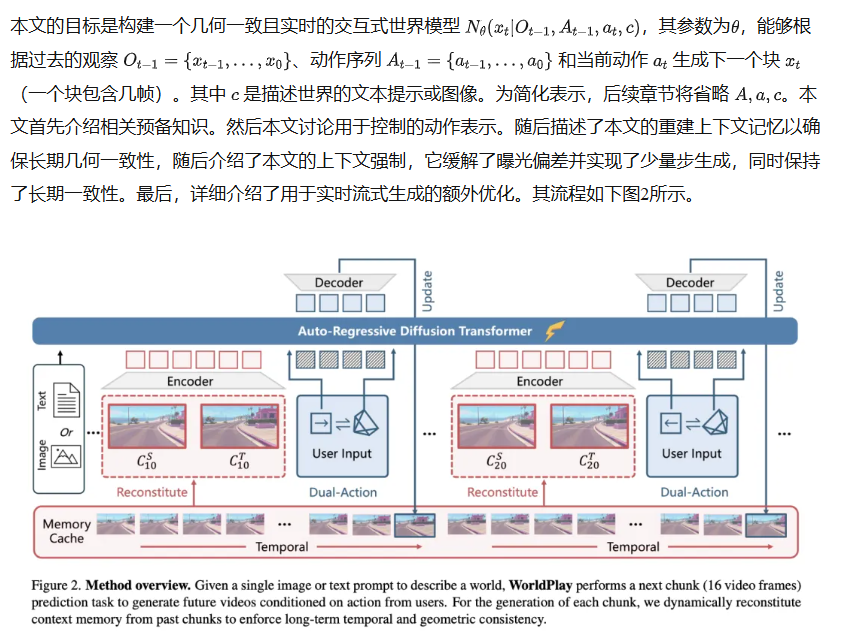
用于控制的双重动作表示
现有方法使用键盘和鼠标输入作为动作信号,并通过MLP或注意力块注入动作控制。这使得模型能够学习跨不同尺度场景(例如非常大和非常小的场景)的物理上合理的运动。然而,它们难以提供精确的先前位置以进行空间记忆检索。相比之下,摄像机姿态(旋转矩阵和转换向量)提供了精确的空间位置,有助于精确控制和记忆检索,但仅使用摄像机姿态进行训练由于训练数据中的尺度差异而面临训练稳定性的挑战。为了解决这个问题,本文提出了如下图3所示的双重动作表示,它结合了两者的优点。
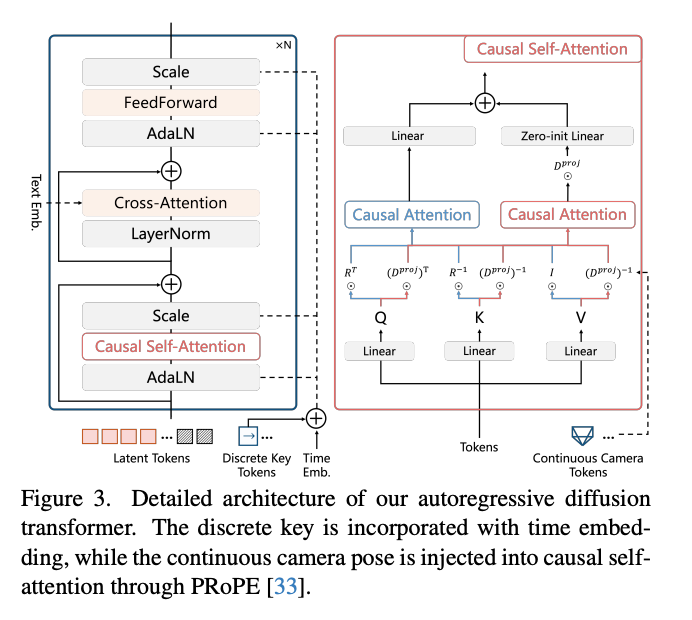
这种设计不仅为记忆模块缓存了空间位置,而且实现了鲁棒和精确的控制。具体来说,本文采用PE和零初始化MLP来编码离散按键,并将其并入时间步嵌入中,然后用于调制DiT块。对于连续摄像机姿态,本文利用相对位置编码,即PRoPE,它比常用的光线图具有更大的泛化能力,将完整的摄像机视锥体注入到自注意力块中。原始自注意力计算如公式(2)所示:

用于一致性的重建上下文记忆

一旦记忆上下文被重建,挑战就转移到如何应用它们来强制一致性。有效使用检索到的上下文需要克服位置编码中的一个根本缺陷。使用标准RoPE(如上图4b所示),当前块与过去记忆之间的距离随时间无限增长。这种不断增长的相对距离最终可能超过RoPE中训练的插值范围,导致外推伪影。更关键的是,对这些早已过去的空间记忆的感知距离不断增长会削弱它们对当前预测的影响。为了解决这个问题,本文提出了时间重构(如上图4c所示)。本文放弃了绝对时间索引,并动态地为所有上下文帧重新分配新的位置编码,建立与当前帧固定的、小的相对距离,无论它们实际的时间间隔如何。这种操作有效地将重要的过去帧在时间上“拉近”,确保它们保持影响力,并实现鲁棒的外推以实现长期一致性。
上下文强制

具有实时延迟的流式生成
本文通过一系列优化增强了上下文强制,以最小化延迟,在8个H800 GPU上实现了24 FPS、720p分辨率的交互式流媒体体验。
DiT和VAE的混合并行方法。 与复制整个模型或在时间维度上适应序列并行性的传统并行方法不同,本文的并行方法结合了序列并行性和注意力并行性,将每个完整块的 token 分配到不同的设备上。这种设计确保了生成每个块的计算工作负载均匀分布,显著减少了每个块的推理时间,同时保持了生成质量。
流式部署和渐进式解码。 为了最小化首帧时间并实现无缝交互,本文采用NVIDIA Triton Inference Framework的流式部署架构,并实现了渐进式多步VAE解码策略,以更小的批次解码和流式传输帧。在从DiT生成潜在表示后,帧会逐步解码,允许用户在后续帧仍在处理时观察生成的内容。这种流式管道确保了即使在不同的计算负载下也能实现平滑、低延迟的交互。
量化和高效注意力。 此外,本文采用了全面的量化策略。具体来说,本文采用了Sage Attention、浮点量化和矩阵乘法量化来提高推理性能。此外,本文还使用KV-cache机制用于注意力模块,以消除自回归生成过程中的冗余计算。
实验
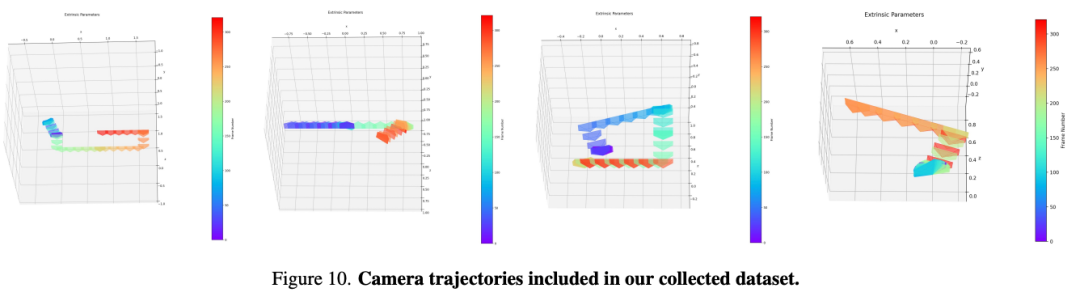
本文将WorldPlay模型在一个大规模、多样化的数据集上进行了训练,该数据集包含约320K高质量视频样本,这些样本来源于真实世界录像和合成环境。数据集包括真实世界动态、真实世界3D场景(DL3DV)、合成3D场景(UE渲染)和模拟动态(游戏视频录制),并且经过精心筛选和处理,以确保动作标注的准确性和训练的稳定性。数据集中的摄像机轨迹如下图10所示,具有复杂多样的特点,包括大量重访轨迹,这有助于模型学习精确的动作控制和长期几何一致性。
评估协议:
-
测试集: 600个测试案例,来源于DL3DV、游戏视频和AI生成图像,涵盖多种风格。
-
短期设置: 使用测试视频中的摄像机轨迹作为输入姿态。生成的视频帧直接与真实(Ground-Truth, GT)帧进行比较,以评估视觉质量和摄像机姿态准确性。
-
长期设置: 使用各种自定义循环摄像机轨迹来测试长期一致性,这些轨迹旨在强制重访。每个模型沿着自定义轨迹生成帧,然后沿着相同的路径返回,通过比较返回路径上的生成帧与初始通过期间生成的对应帧来评估指标。
-
评估指标: LPIPS、PSNR、SSIM用于衡量视觉质量; 和 用于量化动作准确性。
基线方法:
-
无记忆动作控制扩散模型: CameraCtrl [16]、SEVA [80]、ViewCrafter [77]、Matrix-Game 2.0 [17] 和 GameCraft [31]。
-
有记忆动作控制扩散模型: Gen3C [52] 和 VMem [32]。
主要结果:
-
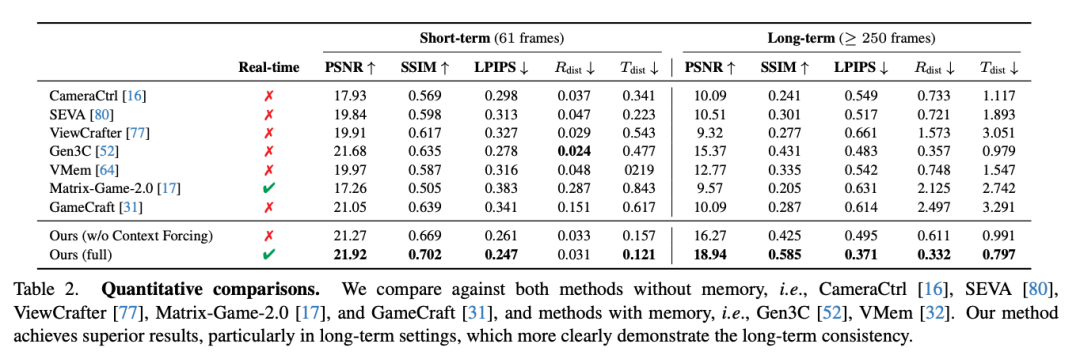
定量结果:如下表2所示,在短期方案中,WorldPlay在视觉保真度上表现出色,并保持了有竞争力的控制精度。在更具挑战性的长期方案中,WorldPlay仍然更稳定并取得了最佳性能。在长期几何一致性方面,Matrix-Game-2.0 [17] 和 GameCraft [31] 由于缺乏记忆机制而表现不佳。尽管VMem [32] 和 Gen3C [52] 采用显式3D缓存来保持一致性,但它们受深度精度和对齐的限制,难以实现鲁棒的长期一致性。受益于重建上下文记忆,WorldPlay实现了改进的长期一致性。此外,通过上下文强制,WorldPlay进一步防止了误差累积,从而获得了更好的视觉质量和动作准确性。
-
定性结果:如下图6所示,WorldPlay在长期一致性和视觉质量方面取得了最先进的成果,涵盖了第一人称和第三人称的真实和风格化世界等多种场景。Gen3C中使用的显式3D缓存对中间输出的质量高度敏感,并受深度估计精度的限制。相比之下,WorldPlay的重建上下文记忆通过更鲁棒的隐式先验保证了长期一致性,实现了卓越的场景泛化能力。Matrix-Game-2.0和 GameCraft由于缺乏记忆而无法支持自由探索。此外,它们在第三人称场景中泛化能力不佳,使得在场景中控制智能体变得困难,限制了其适用性。相反,WorldPlay成功地将其效能扩展到这些场景,并保持了高视觉保真度和长期几何一致性。
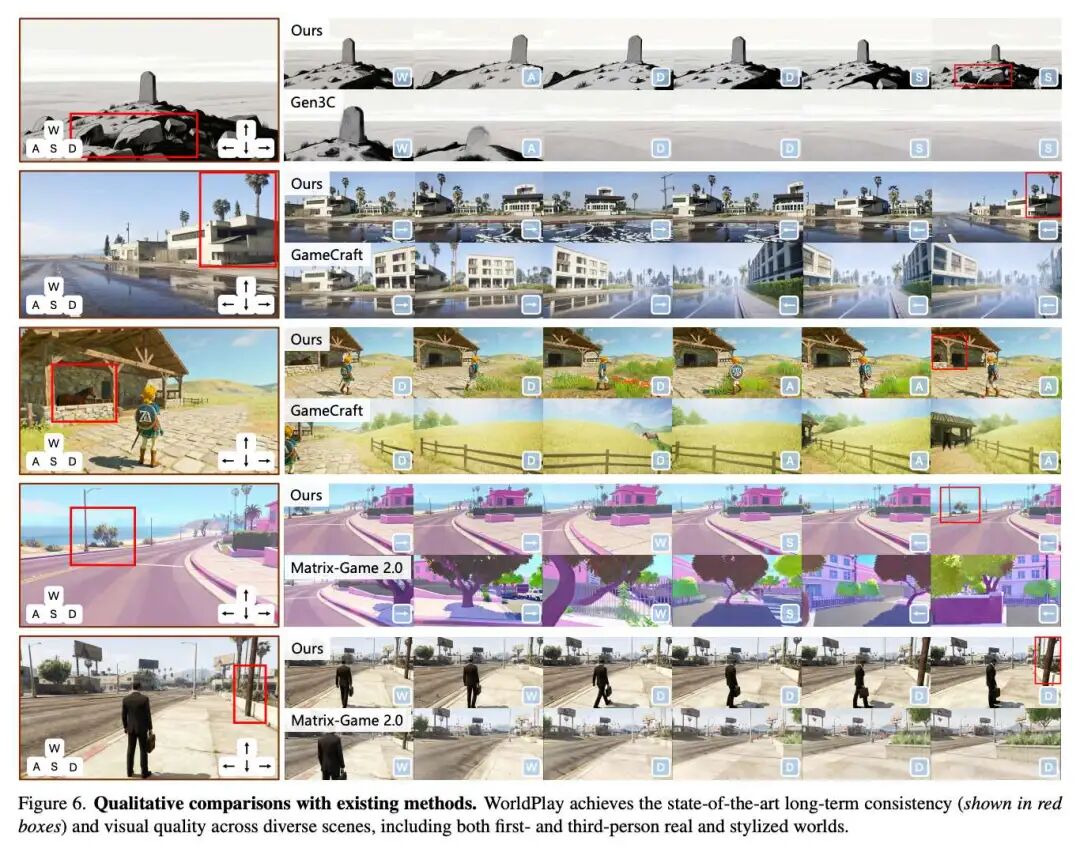
消融实验:
-
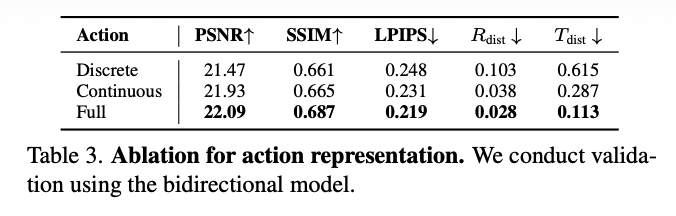
动作表示:如下表3所示,验证了所提出的双重动作表示的有效性。仅使用离散按键作为动作信号,模型难以实现精细控制,导致 和 指标性能不佳。使用连续摄像机姿态虽然结果更好,但由于尺度差异,收敛更困难。通过采用双重动作表示,本文实现了最佳的整体控制性能。
-
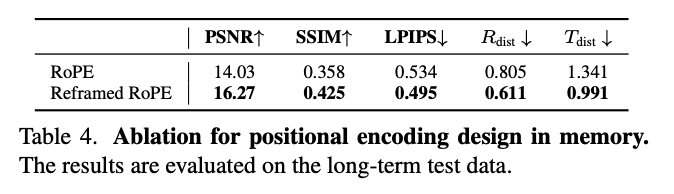
RoPE设计:如下表4所示,展示了不同RoPE设计在记忆机制中的定量结果,表明重构RoPE优于朴素的对应物,尤其是在视觉指标上。如下图7上半部分所示,RoPE更容易发生误差累积。它还增加了记忆和预测块之间的距离,导致几何一致性较弱,如下图7下半部分所示。

-
上下文强制:为验证记忆对齐的重要性,本文训练教师模型时遵循 [74],其中记忆是在潜在级别而非块级别选择。虽然这可能减少教师模型中的记忆上下文数量,但也会在教师模型和学生模型之间引入失调的上下文,导致如上图8a所示的崩溃结果。此外,对于过去的块 ,本文尝试遵循 [68] 中的推理时间策略,将历史块自回滚作为上下文。然而,这可能导致双向扩散模型提供不准确的分数估计,因为它使用干净的块作为记忆进行训练。因此,这种差异引入了如下图8b所示的伪影。本文通过从真实视频中采样获取历史块,这产生了如下图8c所示的优越结果。

-
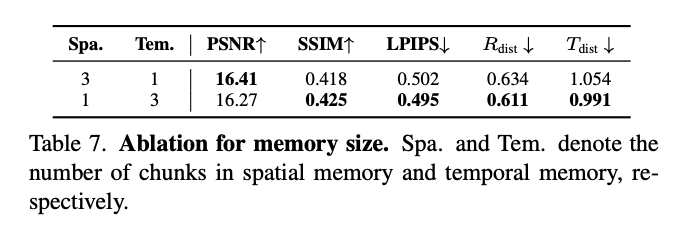
记忆大小消融:如下表7所示,评估了不同记忆大小的效果。使用更大的空间记忆大小略微提高了PSNR指标,而更大的时间记忆大小更好地保留了预训练模型的时间连续性,从而获得了更好的整体性能。此外,更大的空间记忆大小可能会显著增加教师模型的记忆大小,因为相邻块的空间记忆可能完全不同,而它们的时间记忆重叠。这不仅增加了训练教师模型的难度,也对蒸馏提出了挑战。
应用:
-
3D重建:如上图1d和下图17所示,受益于长期几何一致性,WorldPlay可以集成3D重建模型以生成高质量点云。

-
可提示事件:如下图9和上图1e以及下图16上半部分所示,WorldPlay支持文本交互来触发动态世界事件,用户可以随时提示以响应性地改变正在进行的流。


-
视频续写:如上图16下半部分所示,WorldPlay可以生成与给定初始视频片段在运动、外观和光照方面高度一致的后续内容,从而实现稳定的视频续写,有效地扩展原始视频,同时保持时空一致性和内容连贯性。
VBench和用户研究:
-
VBench评估:如下图14所示,WorldPlay在VBench的多项指标上表现出色,尤其在一致性、运动平滑度和场景泛化能力等关键方面取得了突出成果。
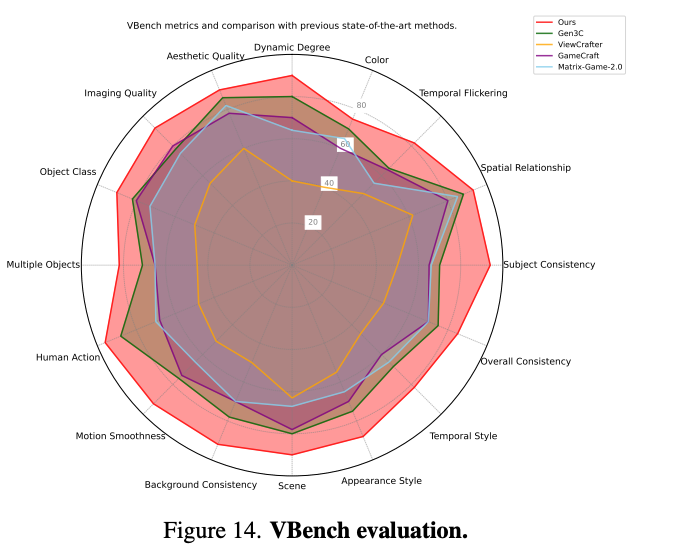
-
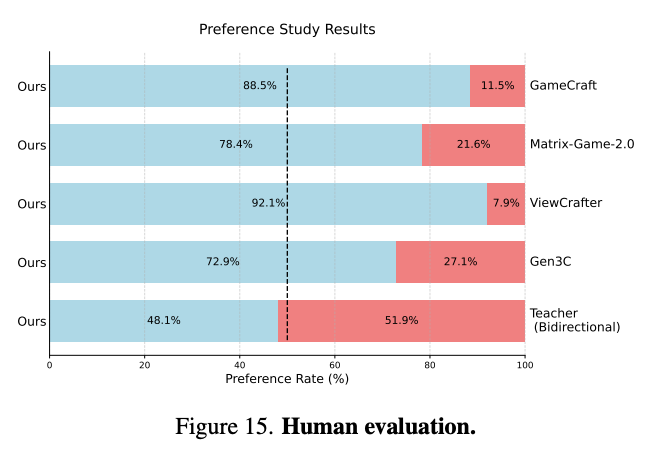
用户研究:如下图15所示,通过对30名评估员进行的用户研究表明,WorldPlay在视觉质量、控制准确性和长期一致性等所有评估指标上均优于其他基线模型,充分证明了WorldPlay在实时交互和长期一致性方面的能力。
结论
WorldPlay是一个强大的世界模型,具有实时交互性和长期几何一致性。它赋能用户能够做到:
-
卓越的几何一致性:WorldPlay通过重建上下文记忆和时间重构机制,有效地解决了传统世界模型中场景重访时出现的几何不一致问题,即使在长期生成中也能保持环境的稳定和连贯。
-
实时的交互性:利用上下文强制蒸馏方法和一系列优化技术(如混合并行、流式部署、渐进式解码、量化和高效注意力),WorldPlay实现了24 FPS的720p视频生成,为用户提供了沉浸式的实时交互体验。
-
强大的泛化能力:在包含真实世界和合成数据的多样化大规模数据集上进行训练,使得WorldPlay能够广泛应用于第一人称和第三人称场景,以及各种风格的世界,包括3D重建和文本驱动的动态事件。
-
创新的核心技术:双重动作表示融合了离散按键和连续摄像机姿态的优点,实现了精确而鲁棒的控制。重建上下文记忆动态管理和重构历史帧,克服了长程信息衰减。上下文强制通过对齐教师模型和学生模型的记忆上下文,有效缓解了误差累积和分布不匹配问题。
总的来说,WorldPlay在实时交互式世界建模领域取得了显著进展,为未来具身智能、游戏开发和虚拟环境构建等应用奠定了坚实基础。
参考文献
[1] WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









