




本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/NXLoBghCr2i_8Sjh--O8LQ

📋 本文概要
DETR类目标检测器存在一个核心痛点:多个可学习的目标Query在训练过程中会低效地“内卷”,争相预测同一个物体,造成计算资源浪费。
本文提出的Route-DETR通过一种创新的自适应成对路由机制,在解码器的自注意力层中动态区分并引导Query间的竞争与协作关系。该方法在多个主流DETR变体上实现了一致的性能提升,例如在COCO数据集上,基于ResNet-50的DINO模型mAP提升了 +1.7%,基于Swin-L Backbone 的模型达到了 57.6% mAP 的SOTA水平。
❓ 主要解决哪些问题?
在目标检测领域,DETR及其变体以其优雅的端到端设计(无需手工设计的NMS后处理)而闻名。然而,其训练过程存在一个固有的效率瓶颈:Query竞争。
现状分析与致命缺陷
传统的DETR模型初始化一组可学习的Query,它们通过解码器与图像特征交互,逐步收敛到最终的检测框。理想情况下,每个Query负责一个独特的物体。但现实是,在训练初期,多个Query的预测框常常会重叠在同一个前景物体上。由于DETR采用一对一标签分配(一个GT框只分配给一个Query),最终只有一个“幸运”的Query能成功匹配并学习到该物体,其他定位同样良好的Query则被强制归类为背景。这就导致了严重的计算冗余——大量Query在反复优化一个它们最终“无权”检测的目标。
场景举例与核心难点
想象一个自动驾驶场景,摄像头前方有多辆汽车。DETR解码器中的多个Query可能都被吸引到同一辆车上进行精细定位,而忽略了其他车辆。这不仅浪费了计算力,还可能因为“内耗”而延迟了对其他关键目标的发现,在实时性要求极高的场景下是致命的。
这个问题的核心难点在于,标准的自注意力机制是对称且无差别的。它平等地处理所有Query对,无法感知哪些Query正在“内卷”(竞争同一目标),哪些Query应该“分工合作”(探索不同区域)。以前的方法多着眼于提前选择或终止Query,但并未从根本上改变Query间的交互逻辑。
🚀 本文的原理与方法
Route-DETR的核心思想是:在解码器的自注意力层中,引入一个可学习的、非对称的注意力偏置矩阵 ,来动态地引导Query间的交互。这个偏置不是固定的,而是根据Query对的实时状态(相似度、置信度、几何信息)计算出来的。
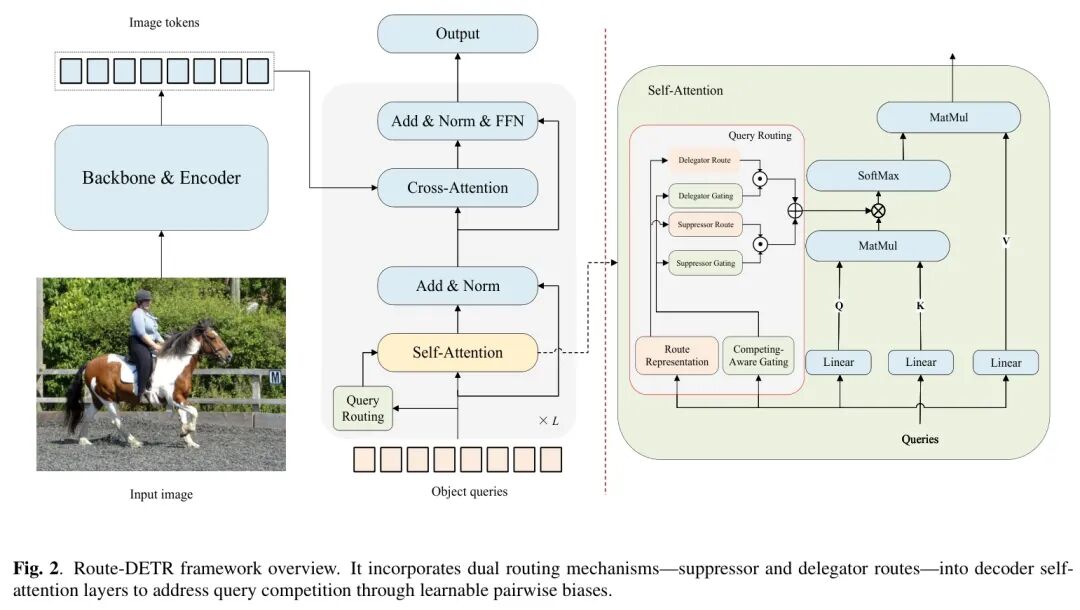
图2
图:Route-DETR整体架构。它在标准DETR解码器的自注意力模块中,引入了一个自适应路由模块,根据Query描述符生成路由偏置B,从而修改注意力图。
💡 低秩成对路由表示

💡 竞争感知成对门控

💡 注意力偏置整合与修改的自注意力
为了确保抑制和委托产生相反的效果,作者对两种路由的强度进行了符号化参数化:

💡 双分支训练策略

图:DETR中Query竞争示意图与Route-DETR的双分支训练。训练时,辅助分支引入路由偏置B来引导Query专业化;推理时只使用干净的主分支,零开销。
为了稳定训练并保证推理零开销,作者采用了巧妙的双分支训练策略。
-
• 主分支:使用标准的、未修改的自注意力机制。它确保模型主干能稳定收敛。
-
• 辅助分支:使用集成了路由偏置 B 的修改版自注意力。

📊 实验结果与分析
🏆 SOTA对比
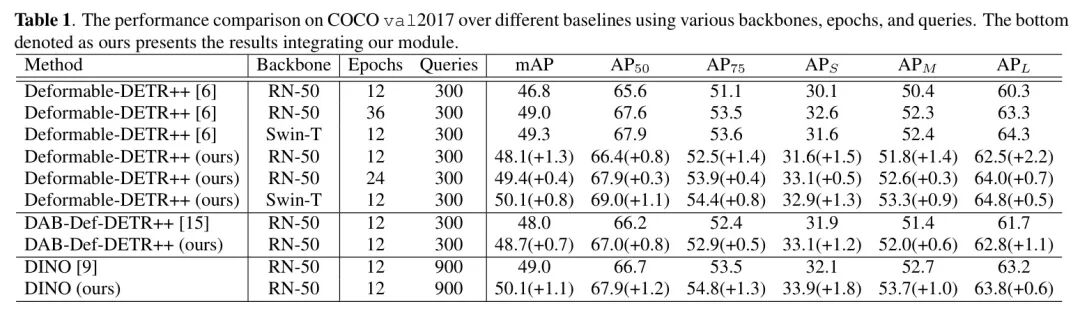
表1
表:在COCO val2017上的目标检测结果。Route-DETR在多种Backbone和DETR变体上均带来稳定提升。
如表1所示,Route-DETR展现出强大的泛化能力:
-
• 在Deformable-DETR++上:使用ResNet-50训练12个epoch,mAP从 46.8% 提升至 48.1%(+1.3%)。更显著的是,其24个epoch的结果(49.4%)已接近甚至超过了原模型36个epoch的结果(49.0%),这意味着训练效率提升了约1/3。
-
• 在中大型目标上提升明显:在ResNet-50上,中等目标 提升1.4%,大型目标 提升2.2%。这说明路由机制能有效缓解Query在显著目标上的“扎堆”现象。
-
• 架构无关性:在DAB-Def-DETR++和DINO等不同变体上,mAP分别提升0.7%和1.1%,证明了其作为通用增强模块的潜力。
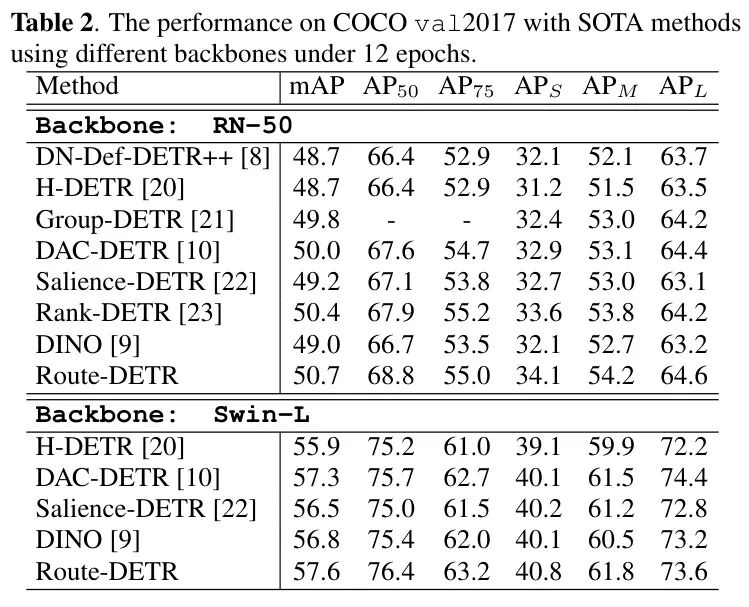
表2
表:与最先进方法的对比。Route-DETR结合DINO取得了新的SOTA性能。
如表2所示,当Route-DETR与强大的DINO基线结合,并采用更先进的训练策略时,产生了质的飞跃:
-
• 在ResNet-50上,mAP从 49.0% 大幅提升至 50.7%(+1.7%)。
-
• 在强大的Swin-L Backbone 上,Route-DETR达到了 57.6% 的mAP,超越了同期优秀工作如DAC-DETR(57.3%)和Salience-DETR(56.5%),确立了新的SOTA。
🔬 泛化到实例分割
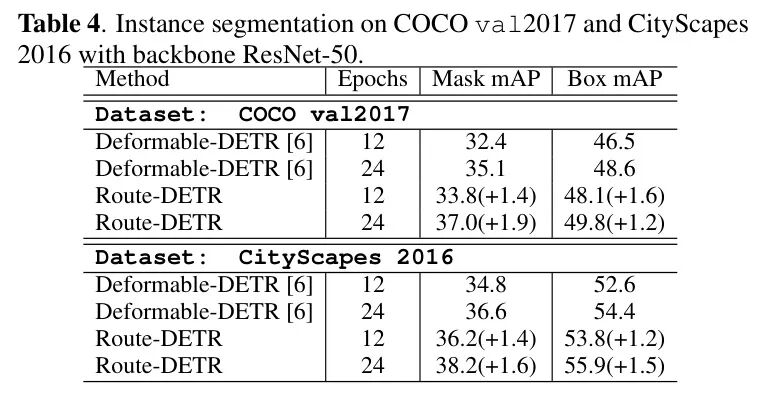
表4
表:在COCO和Cityscapes数据集上的实例分割结果。
为了验证其泛化性,作者将Route-DETR应用于实例分割任务(在检测头基础上增加一个掩码预测头)。表4结果显示:
-
• 在COCO数据集上,12 epoch训练时,掩码mAP提升 1.4%(32.4% → 33.8%);24 epoch时提升 1.9%(35.1% → 37.0%)。
-
• 在Cityscapes数据集上同样有约 1.4-1.6% 的稳定提升。
-
• 边界框mAP也同步提升,这表明路由机制优化的是Query的通用表征能力,受益的是所有下游任务。
⚖️ 局限性与未来展望
尽管Route-DETR取得了显著成功,但仍有一些值得探讨的局限性和未来方向:
-
1. 计算开销与参数:虽然推理零开销,但训练时由于要计算路由表示、低秩矩阵和门控,会增加一定的计算和内存负担。低秩设计缓解了这一问题,但对于超大规模模型,仍需评估其扩展性。
-
2. 门控机制的普适性:当前的门控信号(相似度、置信度、几何面积)在目标检测任务中设计精巧,但若迁移到其他任务(如视频理解、3D检测),可能需要设计新的、任务相关的门控描述符。
-
3. 失败案例分析:论文未详细展示路由机制失效的情况。可以推测,在物体极度密集、遮挡严重的场景下(如人群),Query间的竞争关系可能异常复杂,当前的门控模型可能不足以做出最优路由决策。
-
4. 未来方向:
-
• 自适应路由调度:可以探索更动态的路由调度策略,例如在训练不同阶段调整路由强度或类型。
-
• 扩展到其他Transformer架构:将这种成对路由思想应用于视觉Transformer(ViT)的编码器或其他多模态Transformer中,以管理不同Token或模态间的交互。
-
• 可解释性研究:可视化学习到的路由偏置矩阵 ,分析模型在何时何地做出了“抑制”或“委托”的决策,能进一步增强我们对Transformer内部工作机制的理解。
-
总之,Route-DETR通过一种优雅且高效的方式,首次在DETR框架内显式地建模并引导了Query间的竞争关系,不仅提升了性能与效率,也为理解与改进基于Query的视觉模型提供了新的思路。
参考
ROUTE-DETR: PAIRWISE QUERY ROUTING IN TRANSFORMERS FOR OBJECT DETECTION
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









