




本文来源公众号“我爱计算机视觉”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/xMVKxOL9OCaPMUO7Ds5uWA
自诞生以来,CLIP 就凭借其强大的零样本学习和跨模态理解能力,成为了视觉语言模型领域的基石。然而,这位“优等生”也有自己的烦恼:它擅长把握图像和文本的“全局大意”,却常常在“细枝末节”上犯迷糊。比如,它可能知道图片里有只熊,但分不清熊是在河里还是在河边;能认出这是一个男人,但搞不清是真人还是雕像。
为了解决这一问题,来自华中科技大学和字节跳动等机构的研究者们提出了一个名为 SuperCLIP 的新框架。它的核心思想出奇地简单:在 CLIP 的训练过程中,额外加入一个轻量级的分类任务,从而“强迫”模型去关注文本中描述的那些细粒度语义信息。这种“简单却有效”的改进,不仅显著提升了模型在各种任务上的性能,而且几乎不增加额外的计算开销。

-
论文标题:SuperCLIP: CLIP with Simple Classification Supervision
-
作者:Weiheng Zhao, Zilong Huang, Jiashi Feng, Xinggang Wang
-
机构:华中科技大学,字节跳动
-
论文地址:https://openreview.net/pdf?id=EeIEvZlmVg
-
代码仓库:https://github.com/hustvl/SuperCLIP
-
录用会议:NeurIPS 2025
CLIP的“软肋”:只看宏观,不究细节
我们知道,CLIP 的成功在于它通过对比学习(contrastive learning)将海量的图像和文本对齐到一个统一的特征空间。它学习的目标是让匹配的“图-文”对在特征空间里相互靠近,不匹配的则相互远离。
这种模式的问题在于,它只关心图像和文本在全局语义上是否匹配,而忽略了文本中包含的丰富细节。比如,“一个男人坐在长椅上”和“一个男人站在长椅旁”,对于CLIP来说,这两段描述和同一张图片的全局相似度可能都很高,导致模型难以学会区分“坐”和“站”这两个动作。

论文中的上图直观地展示了 CLIP 在细粒度辨别上的不足。无论是物体的状态(雕像 vs. 真人)、空间关系(内部 vs. 外部),还是具体动作(坐 vs. 站),CLIP 都表现得不尽如人意,而该文提出的 SuperCLIP 则能准确地进行区分。
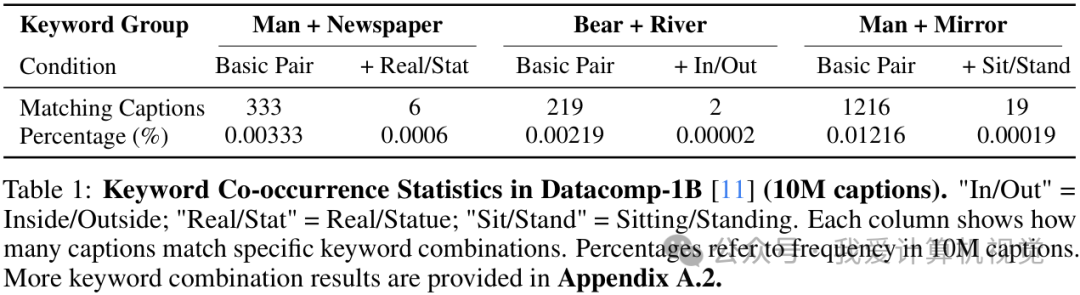
研究者们进一步分析了大规模数据集(如 DataComp-1B)后发现,能够体现这种细粒度差异的“关键词组合”在数据集中本身就非常稀疏。例如,包含“男人”和“报纸”的标题有333个,但同时包含“真人/雕像”这种状态描述的标题就锐减到了6个。这种数据稀疏性,使得依赖“负样本”进行对比学习的 CLIP 很难学到这些细微差别。
SuperCLIP 的“妙计”:化繁为简的分类监督
为了让模型“看见”这些细节,SuperCLIP 的设计堪称优雅而简洁。它没有对 CLIP 的核心架构大动干戈,而是在其图像编码器(Vision Encoder)之上,增加了一个极其轻量级的线性分类层(Linear Layer)。
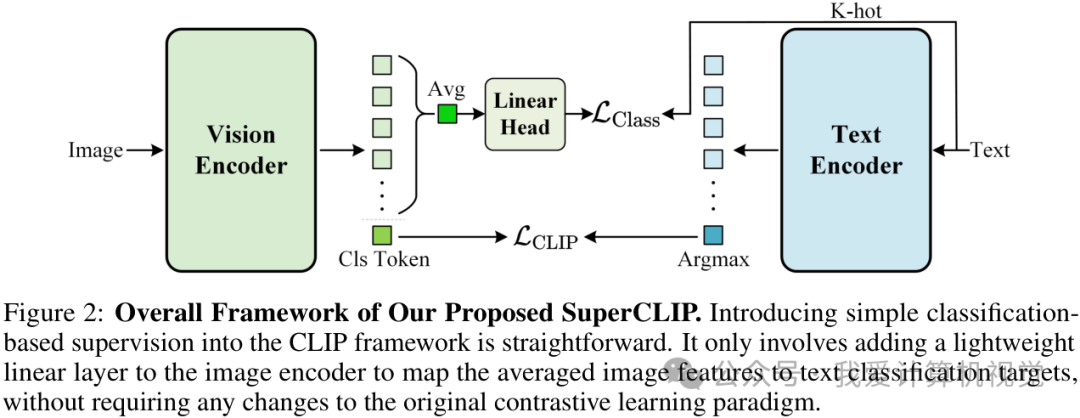
这个新任务的目标是什么呢?答案就藏在与图像配对的文本标题里。具体来说,SuperCLIP 将每个文本标题进行分词,把这些词元(tokens)直接当作图像分类任务的“标签”。这样一来,图像编码器不仅要学习与整个文本匹配,还必须学会识别出图像中与各个“标签”(即文本中的单词)相对应的视觉特征。
整个训练目标函数可以表示为:
其中, 是原始的对比学习损失,而 就是新增的分类损失。通过这个简单的加法,SuperCLIP 将全局的对比学习和局部的分类学习结合起来,引导视觉编码器从文本的所有单词中恢复丰富的监督信号,从而实现更精细的图文对齐。
这种方法最大的优势在于:
-
无需额外标注:分类任务的“标签”直接来自原始的文本数据,完全免费。
-
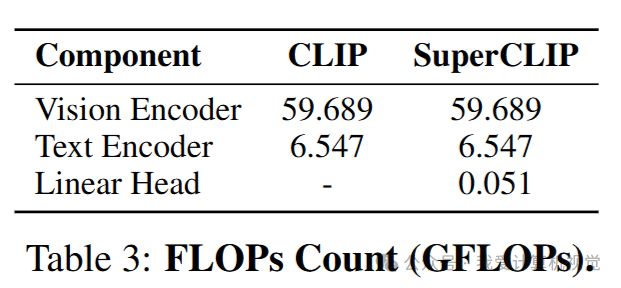
计算开销极低:新增的线性层带来的额外计算量微乎其微。论文指出,对于 L 尺寸的模型,FLOPs 仅增加 0.077%。
全面提升的实验效果
SuperCLIP 的有效性在大量实验中得到了验证。无论是在零样本图像分类、图文检索,还是纯视觉任务上,它都取得了超越原始 CLIP 的性能。
跨尺寸、跨任务的稳定增益
研究者在不同模型尺寸(Base 和 Large)和不同数据规模(512M 和 12.8B)下进行了对比。结果显示,SuperCLIP 全面胜出。
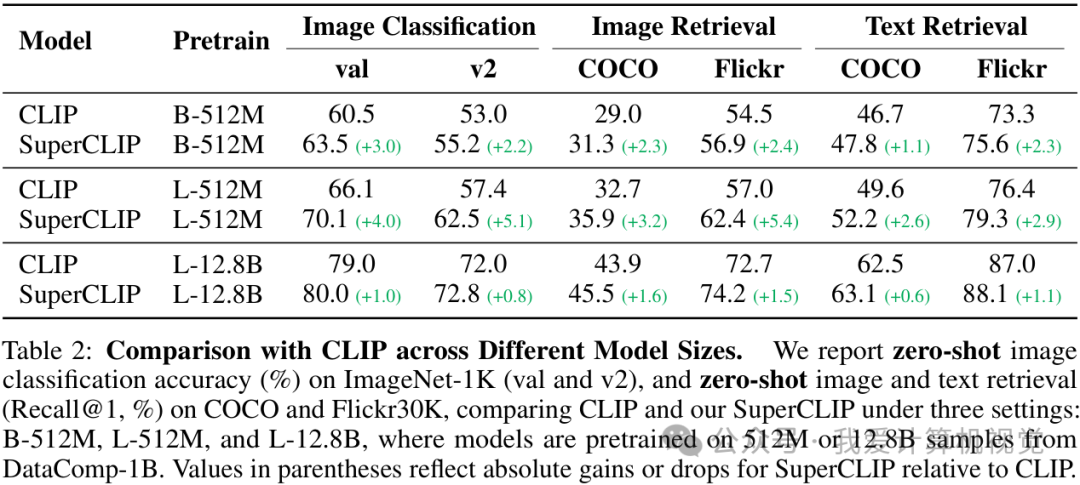
如上表所示,以 L-512M 设置为例,SuperCLIP 在 ImageNet-1K 上的零样本分类准确率提升了 5.1%,在 Flickr30K 上的图像检索 Recall@1 提升了 5.4%。即使在 12.8B 的超大规模数据上,SuperCLIP 依然能带来稳定的性能增益。
更好的泛化性和鲁棒性
SuperCLIP 的思想不仅适用于 CLIP,也能无缝迁移到其他 CLIP-style 的框架(如 SigLIP 和 FLIP)上,同样带来了显著的性能提升。这证明了其方法的普适性。
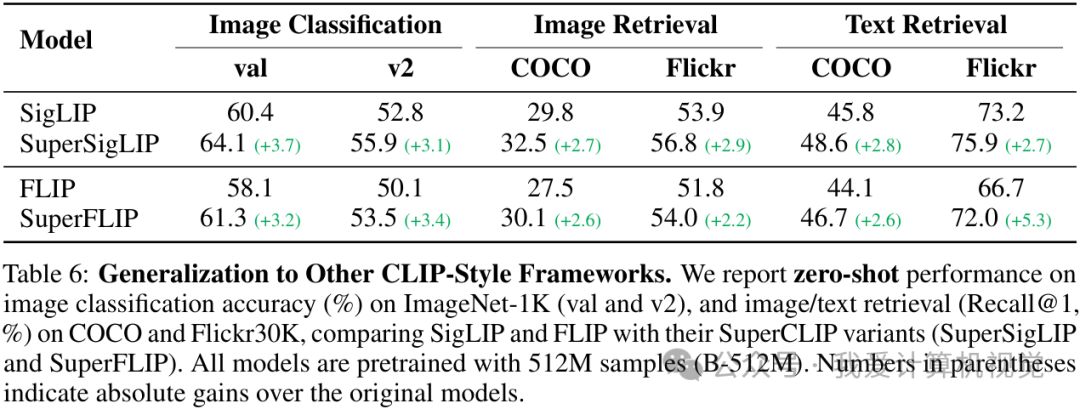
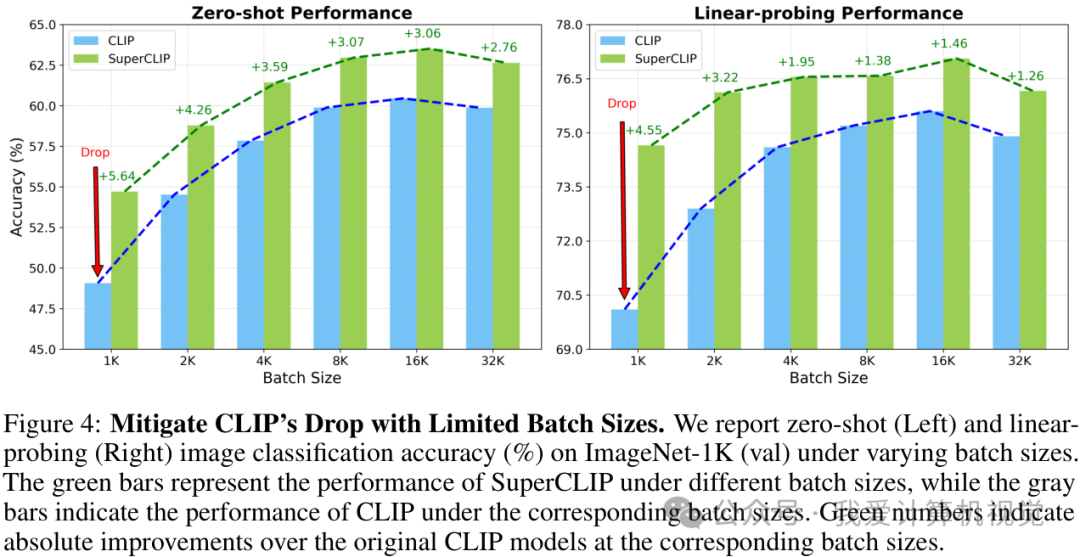
更有趣的是,SuperCLIP 还缓解了 CLIP 的一个著名“痛点”:对大批量(large batch size)训练的依赖。由于分类损失本身与批量大小无关,SuperCLIP 在小批量训练设置下依然能保持优异性能,而此时的 CLIP 性能已大幅下降。这无疑为资源受限的研究者和开发者带来了福音。
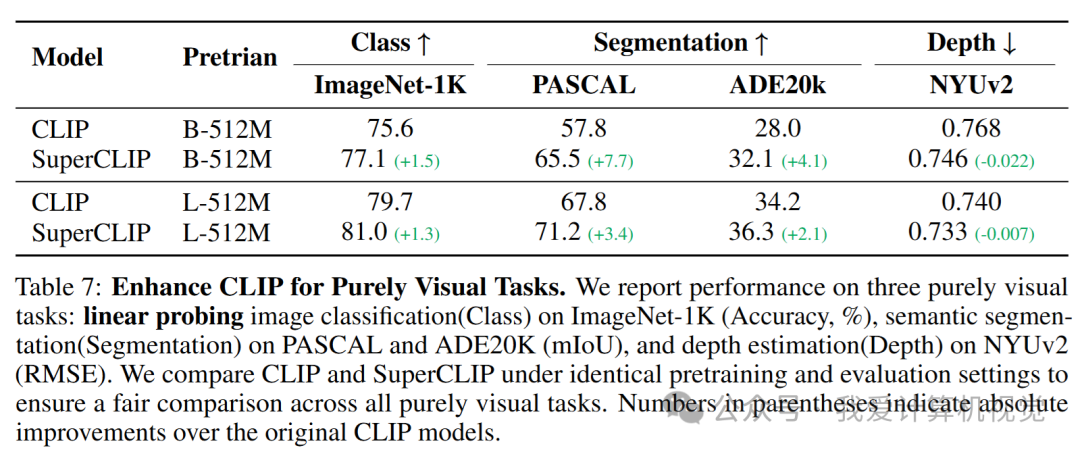
实验还表明,SuperCLIP 训练出的视觉编码器在纯视觉任务(如语义分割、深度估计)上也表现更佳,证明其学到的视觉表征质量更高。
写在最后
总而言之,SuperCLIP 提出了一种极为简单而高效的方法,通过引入一个轻量级的分类监督任务,成功地让 CLIP 学会了关注文本中的细粒度语义信息。它不仅在多个基准测试中取得了全面且显著的性能提升,还解决了 CLIP 对大批量训练的依赖问题,同时保持了极低的计算开销。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









