 jina-reranker-v3多语言文档重排解析
jina-reranker-v3多语言文档重排解析





本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/lhzp9FOk7SL_T-ynxzTPHw
jina-reranker-v3 是一个参数量达 0.6B 的多语言文档重排器,引入了一种新颖的“后发先至”的交互架构。与 ColBERT 采用多向量匹配的单独编码不同,该模型在同一上下文窗口内对查询和文档执行因果自注意力机制,从而在从每个文档的最后一个标记提取上下文嵌入之前实现丰富的跨文档交互。
https://jina.ai/models/jina-reranker-v3/
模型基于 Qwen3-0.6B 构建,拥有 28 个 Transformer 层和一个轻量级 MLP 投影器(1024→512→256),可在 131K 标记上下文中同时处理多达 64 个文档。该模型实现了 61.94 nDCG-10 的行业领先性能,同时比生成式列表式重排器小 10 倍。
模型效果
jina-reranker-v3可在多语言检索基准测试中提供最先进的性能。这款 0.6B 参数的文档重排器引入了一种新颖的last but not late交互方式,它采用了一种与现有方法截然不同的方法。
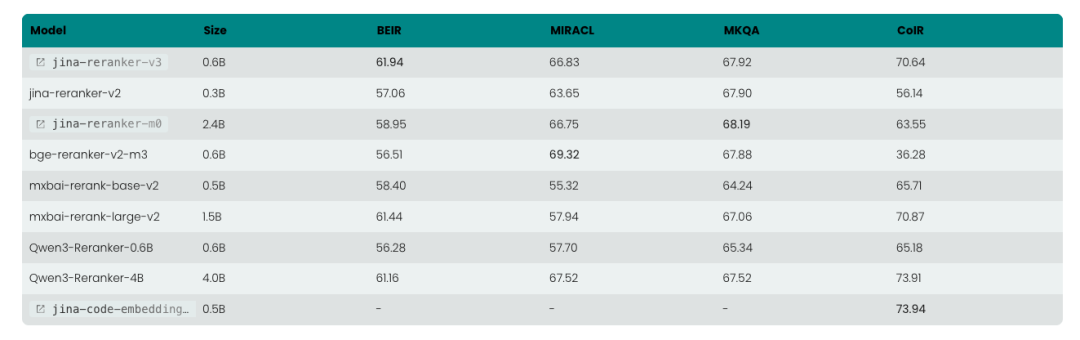
jina-reranker-v3 以listwise方式工作:它在单个上下文窗口内的查询和所有候选文档之间应用因果注意力机制,从而在从每个文档的最终词元中提取上下文 向量模型 之前实现丰富的跨文档交互。我们的新模型在 BEIR 上实现了 61.94 nDCG@10,优于 Qwen3-Reranker-4B,同时体积缩小了 6 倍。
排名靠前的位置显示出极好的稳定性。排名 1-10 的方差最小,无论输入顺序如何,最相关的文档始终排名靠前。这对于 nDCG@10 和类似的 top-k 指标至关重要。不相关的文档始终位于底部,从而在相关内容和不相关内容之间形成清晰的分隔。
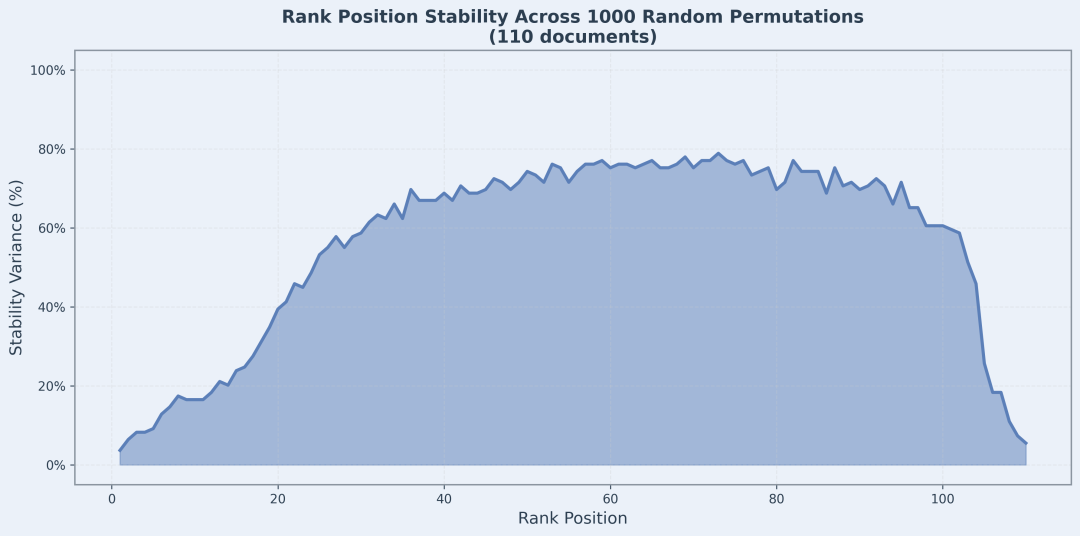
中间部分显示了显著的位置交换,这是预期且可以接受的。该模型使用因果自注意力,并根据序列中它们之前出现的内容对不同的上下文信息进行编码。
模型架构
jina-reranker-v3 构建于 Qwen3-0.6B 主干之上,这是一个仅解码器的 Transformer 模型,具有因果自注意力机制。该模型同时处理多个文档和查询,在指定的词元位置提取上下文 向量模型,以实现高效的相似性计算。

模型的训练目标函数由多个损失函数组合而成,具体为:
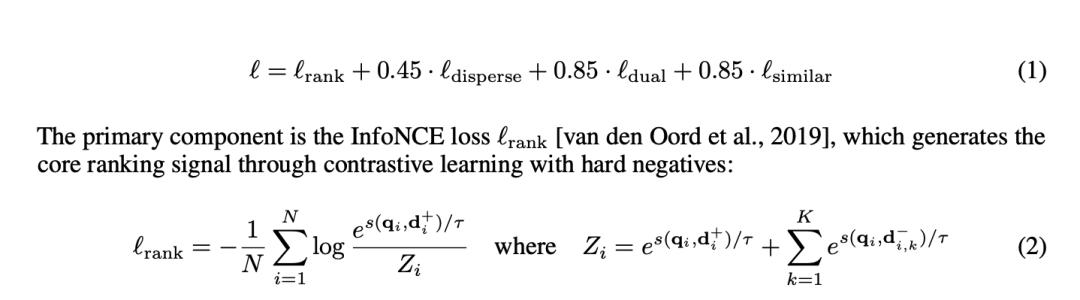
-
InfoNCE损失(ℓrank):这是核心的排名信号,通过对比学习和硬负样本生成排名信号。它计算查询和正样本文档之间的相似度得分与查询和负样本文档之间的相似度得分的对比损失,以此来优化模型对文档相关性的判断。
-
分散损失(ℓdisperse):用于防止表示坍塌,通过最大化文档嵌入之间平均成对余弦距离来增强嵌入的多样性,避免模型将所有文档嵌入映射到相似的向量空间位置,从而提高模型对不同文档的区分能力。
-
双匹配损失(ℓdual):与InfoNCE损失的计算方式相同,但它是从序列开头的查询标记计算查询嵌入。这强制查询到文档和文档到查询的相似性分数之间的一致性,增强了排名的鲁棒性。
-
相似性损失(ℓsimilar):通过文本增强技术为每个输入文档创建一个增强副本,并将原始文档及其增强版本视为正样本对,其他文档作为负样本。这鼓励模型为语义等价的文档生成一致的嵌入表示,即使它们的表面形式因增强而有所不同,有助于保持文档级别的语义一致性。
采用多阶段训练方法
模型的训练分为三个阶段,每个阶段都有其特定的目标和优化策略:
-
第一阶段:基础专业化:从预训练的Qwen3-0.6B模型开始,使用LoRA微调,同时训练针对不同领域的特定配置。模型处理包含每个查询16个文档(1个正样本和15个负样本)的训练序列,每个文档被截断或填充到768个标记,最大总序列长度为12288个标记。训练数据来自多个不同领域的数据集,包括多语言覆盖的BGE-M3、代码检索的Cornstack以及针对生物医学和指令遵循等特定领域的数据集。
-
第二阶段:上下文和硬负样本挖掘:这一阶段结合了上下文扩展和全面的鲁棒性优化。一方面,通过使用像MLDR这样的数据集,将单个文档的长度扩展到8192个标记,以增强对长文档的理解;另一方面,将每个查询的负样本文档数量从15个增加到45个,同时保持总序列长度在131K标记以内。同时,跨系统的硬负样本挖掘通过针对英语性能、多语言检索、代码理解和长文档处理等特定优化,确保模型的鲁棒性。训练系统地从多个检索系统(如BGE、Jina、GTE和E5-Large)中挖掘硬负样本,每个查询最多有25个负样本,使用非常低的温度参数(0.05),使用的关键数据集包括MS-MARCO、mMARCO以及特定领域的合成问答对。
-
第三阶段:模型集成和优化:在最后阶段,通过线性模型合并将前一阶段训练的多个特定领域的模型结合起来。每个特定领域的模型根据领域的重要性和性能贡献加权的专业知识,合并权重根据领域的重要性和性能在0.25到0.65之间变化。这种方法使得最终模型能够在保持架构效率的同时,利用不同领域的知识。
超参数调整
在不同阶段,模型的超参数会根据训练目标和数据特点进行调整。例如:
-
在基础阶段,使用较高的学习率(5e-5)和大量的负样本(15个负样本)。
-
在上下文扩展阶段,由于处理的序列长度增加到8K,因此大幅减少批量大小(从60减少到6),同时使用较为保守的学习率(6e-6)。
-
不同领域的特定要求会导致损失权重的调整。例如,分散损失通常设置为0.45,双匹配损失在0.65到0.85之间变化,相似性损失则稳定在0.75到0.85之间,具体取决于特定领域的需要。
提示词组成
给定一个查询和一组候选文档,jina-reranker-v3 使用专门的 提示词 模板处理重排任务,该模板支持在单个前向传递中进行跨文档交互。输入构造遵循特定格式:
<|im_start|>system
You are a search relevance expert who can determine
a ranking of passages based on their relevance to the query.
<|im_end|>
<|im_start|>user
I will provide you with k passages, each indicated by a numerical identifier.
Rank the passages based on their relevance to query: [QUERY]
<passage id="1">
[DOCUMENT_1]<|doc_emb|>
</passage>
<passage id="2">
[DOCUMENT_2]<|doc_emb|>
</passage>
...
<passage id="k">
[DOCUMENT_k]<|doc_emb|>
</passage>
<query>
[QUERY]<|query_emb|>
</query>
<|im_end|>
<|im_start|>assistant
<think></think>
查询在输入结构中出现两次——一次在开头用于任务指令,一次在结尾用于最终注意力处理。这种双重放置使最终查询位置能够通过因果注意力关注所有前面的文档。两个关键的特殊词元标记了 向量模型 提取位置:<|doc_emb|> 词元放置在每个文档之后,以标记文档 向量模型 提取点,而 <|query_emb|> 词元放置在最终查询之后,以标记查询 向量模型 提取点。这些 向量模型 通过共享的因果自注意力机制捕获局部文档语义和全局跨文档上下文。
我们将这种查询-文档交互称为 "last but not late"。 它是 "last",因为 <|doc_emb|> 被放置为每个文档的最后一个词元。它是 "not late",因为与 ColBERT 等后期交互模型(在多向量匹配之前单独编码文档)不同,我们在前向传递期间在同一上下文窗口中启用查询-文档和文档-文档交互。
最后,一个带有 ReLU 激活函数的两层 MLP 投影器将 1024 维的隐藏状态映射到 256 维的排序空间。相关性评分是通过计算投影后的查询 向量模型 和每个投影后的文档 向量模型 之间的余弦相似度来计算的。这将为输入集中的每个文档生成一个相关性分数。
使用方法
from transformers import AutoModel
model = AutoModel.from_pretrained(
'jinaai/jina-reranker-v3',
dtype="auto",
trust_remote_code=True,
)
model.eval()
query = "What are the health benefits of green tea?"
documents = [
"Green tea contains antioxidants called catechins that may help reduce inflammation and protect cells from damage.",
"El precio del café ha aumentado un 20% este año debido a problemas en la cadena de suministro.",
"Studies show that drinking green tea regularly can improve brain function and boost metabolism.",
"Basketball is one of the most popular sports in the United States.",
"绿茶富含儿茶素等抗氧化剂,可以降低心脏病风险,还有助于控制体重。",
"Le thé vert est riche en antioxydants et peut améliorer la fonction cérébrale.",
]
# Rerank documents
results = model.rerank(query, documents)
# Results are sorted by relevance score (highest first)
for result in results:
print(f"Score: {result['relevance_score']:.4f}")
print(f"Document: {result['document'][:100]}...")
print()THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









