






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/CUKrqaZgk2a0njz64BhNDQ

精简阅读版本
本文主要解决了什么问题
-
1. 大规模自监督视觉模型训练成本过高:如DINOv2等模型虽然性能优越,但其训练依赖大量计算资源,限制了其在学术界和工业界的可复现性和应用。
-
2. 自监督模型在现实场景中的鲁棒性不足:尽管SSL模型在干净数据上表现良好,但在面对常见图像损坏(如噪声、模糊、亮度变化等)时鲁棒性不足,尤其在安全关键型应用中(如自动驾驶、医疗影像)表现不佳。
-
3. 缺乏在有限资源下兼顾效率与鲁棒性的训练方法:当前的SSL方法要么强调性能,要么强调鲁棒性,但难以在训练效率与鲁棒性之间取得平衡。
本文的核心创新是什么
-
1. 提出FastDINOv2:一种基于频率引导的课程学习策略:
-
• 第一阶段使用低频信息(通过图像下采样)进行预训练,加速模型收敛。
-
• 第二阶段引入全分辨率图像,并结合高斯噪声 Patch 增强,提升模型对高频损坏的鲁棒性。
-
-
2. 揭示课程学习导致的高频特征偏差现象:
-
• 作者发现低频训练会使模型偏向于学习高频特征,从而增强对低频损坏的鲁棒性,但削弱了对高频损坏的鲁棒性。
-
-
3. 提出频谱平衡机制:
-
• 通过结合低频课程与高斯噪声 Patch 增强,实现对不同频率损坏的均衡鲁棒性,避免单一增强策略带来的频段偏倚。
-
-
4. 实验验证在多个任务上的有效性:
-
• 在线性分类、实例识别、语义分割等任务中验证了FastDINOv2的性能和鲁棒性,并扩展到ViT-B和ImageNet-1K数据集。
-
结果相较于以前的方法有哪些提升
-
1. 训练效率显著提升:
-
• 在ImageNet-1K上使用ViT-B/16,预训练时间减少1.6倍,FLOPs减少2.25倍。
-
• 内存消耗在训练初期大幅降低(9.47GB vs. Baseline 的33.5GB)。
-
-
2. 鲁棒性提升:
-
• 在ImageNet-C基准测试中,FastDINOv2在保持与Baseline相当的鲁棒性的同时,对多种损坏(如高斯噪声、散焦模糊)表现更好。
-
• 通过课程学习和噪声增强的组合,模型在低频、中频和高频损坏上实现了更均衡的性能。
-
-
3. 多任务性能保持或提升:
-
• 在线性分类任务中,FastDINOv2在200个epoch即达到Baseline 250个epoch的准确率。
-
• 在实例识别和语义分割任务中,模型在加速训练后仍保持甚至提升性能。
-
局限性总结
-
1. 训练阶段切换策略固定:
-
• 当前方法在训练的前75%使用低频图像,后25%切换到全分辨率图像,这一切换时间表是固定的,可能在不同训练设置下并非最优。
-
-
2. 局部增强策略的局限性:
-
• 高斯噪声 Patch 虽然增强了对高频损坏的鲁棒性,但在某些中频损坏(如弹性变换、缩放模糊)上效果有限。
-
-
3. 未探索与其他增强策略的结合:
-
• 作者仅结合了课程学习和高斯噪声 Patch,未尝试将其与对抗训练、CutOut等其他增强策略结合,未来可进一步探索。
-
-
4. 频率分析依赖已有方法:
-
• 对模型频率偏差的分析基于已有傅里叶分析方法,尚未提出新的频域建模方式。
-
深入阅读版本
导读
大规模视觉基础模型如DINOv2通过利用庞大的架构和训练数据集展现出令人印象深刻的性能。然而,许多场景要求从业者复现这些预训练解决方案,例如在私有数据、新模态上,或仅仅出于科学探究的需求——这目前对计算资源提出了极高的要求。因此,作者提出了一种针对DINOv2的新型预训练策略,该策略同时加速了收敛性,并作为副产品增强了其对常见损坏的鲁棒性。FastDINOv2包括频率过滤课程(先学习低频信息)和高斯噪声 Patch 增强。应用于在ImageNet-1K上训练的ViT-B/16主干网络,FastDINOv2在将预训练时间和FLOPs分别减少了1.6倍和2.25倍的同时,仍能在损坏基准测试(ImageNet-C)中达到与 Baseline 模型相当的鲁棒性,并保持具有竞争力的线性检测性能。这种效率和鲁棒性的双重优势使得大规模自监督基础建模更加可行,同时为通过数据课程和增强来提升自监督学习模型鲁棒性的新探索打开了大门。
代码: https://github.com/KevinZ0217/fast_dinov2
1 引言
DINOv2 [22] 和 CLIP [25] 等基于视觉Transformer(ViT) Backbone 网络 [11] 构建的模型,在性能、泛化能力乃至上游鲁棒性 [39] [24] 方面取得了显著成果。这些进步主要源于自监督学习(SSL)——一种模型通过解决 Agent 任务(例如对比匹配、预测 Mask 块)从无标签数据中学习有用表示的范式,而非依赖成本高昂的人工标注 [12]。SSL 的吸引力在于其能够利用网络上庞大的、不断增长的原生图像资源;通过在数据本身中发现结构,SSL 能够生成能够有效迁移到下游任务(如分类、目标检测和分割)的特征,其性能往往与甚至超过完全监督学习的结果 [9] [13]。
然而,复制这些最近的突破通常需要巨大的计算资源:例如在数十亿图像上训练数百个epoch的大型ViT变体(如ViT-G)[4],多GPU集群以及复杂的优化方案。这种资源壁垒可能使许多学术实验室和初创公司将最先进的SSL技术拒之门外,限制了可复现性和进一步创新。此外,尽管预训练的SSL模型在干净基准测试上经常表现出色,但针对真实世界分布偏移的鲁棒性——常见的损坏、传感器噪声、天气影响——对于医疗成像[2][30]或自动驾驶[4]等安全关键应用仍然至关重要。尽管一些研究表明与监督预训练相比,SSL可以提高鲁棒性[18][3][21],但大多数SSL方法并未明确优化鲁棒性,而现有的鲁棒预训练往往增加了计算需求[26][35]。
特别是,近期的大规模自监督学习模型仅在训练规模达到极端程度时才会表现出涌现式鲁棒性:例如,DINOv2及相关方法需要ViT-B模型参数量超过8600万,以及规模相似的LVD-142M和LAION-5B等数据集[28],才能获得较强的抗损坏能力。这种规模驱动的鲁棒性在原则上具有吸引力,但在实践中对无法获得大规模计算资源的科研行人而言成本过高。因此,迫切需要设计计算高效的SSL训练方法,同时仍能提供鲁棒性保证。
为解决这一差距,作者提出了一种用于DINOv2预训练的两阶段课程,该课程既能加速收敛,又能增强对基于频率的损坏的鲁棒性——所有这一切都不依赖于过大的模型或数据集。FastDINOv2源于这样的观察:高频和低频损坏会污染图像的不同频段,而数据驱动的课程可以在不同的训练阶段引导学习强调或淡化特定的频段。训练课程包括两个阶段:
阶段1 - 低频训练。作者首先对图像进行下采样,强调其低频分量。这促使模型快速学习广泛、粗略的特征,并加速在干净数据上的收敛。
阶段2 - 全分辨率与高频增强。随后作者过渡到全分辨率输入,同时引入高斯噪声 Patch ,即随机图像块被噪声替换。这迫使模型学习对高频扰动的不变性,并提高鲁棒性。
通过广泛的实验,FastDINOv2不仅实现了更快的收敛速度,而且在具有不同规模的模型和数据集上表现出更高的鲁棒性。这项工作表明,鲁棒性并非极端规模下的必然产物,而是可以通过精心设计的课程学习和增强技术构建到SSL(自监督学习)中的。作者相信这为更易于访问、可复现和鲁棒的自监督训练打开了大门。
总之,作者的贡献如下:
-
• 作者对使用低频数据课程预训练的模型进行了全面的鲁棒性和频率分析——这是一个尚未充分探索的方向。作者识别出这种训练方案引入的低频偏差,并提出高斯噪声 Patch 作为增强鲁棒性的补充数据增强方法。
-
• 所提出的课程通过使用DINOv2和ViT-B Backbone 网络,加速了在ImageNet-1K [27]上的收敛速度,将预训练时间缩短了1.66x,FLOPs减少了2.25x,同时保持了匹配的鲁棒性和具有竞争力的干净线性检测精度。
2 相关工作
基于频率引导的课程学习
通过将示例从易到难排序,课程学习在随机梯度下降下实现了收敛速度的单调增加[34]。同时已被证明,理想的课程可以有效地平滑优化景观,而不改变全局最小值的位置[14]。因此,有效地定义难度 Level 对于强大的课程至关重要。基于梯度的深度网络训练首先系统地拟合目标函数的低频分量,随着训练的进行逐渐捕获高频特征[36]。对于视觉Transformer而言,特别是多头自注意力机制充当低通滤波器,衰减高频信号同时保留低频分量[23]。
计算机视觉中的由粗到精范式首先在信息量减少的图像中训练模型,然后在它们的全分辨率对应图像上进行训练。因此,自然地将图像中的低频分量定义为简单示例,而同时包含低频和高频特征的完整图像则定义为更困难的示例。从傅里叶的角度来看,自然图像内容集中在低频域[37],因此下采样在减少计算成本的同时保留了大部分信息。一些工作将小图像或低频分量纳入训练流程以加速ViT收敛:RECLIP[19]将此课程应用于预训练CLIP,而EfficientTrain [33]将其推广到各种基于ViT的模型,包括MoCo [15]和MAE [16]。然而,这种方法对模型鲁棒性的影响尚不清楚。此外,作为一种通用方法,EfficientTrain 在DINO [7]上评估了它,但没有观察到收敛速度的提升。在本文中,作者重新审视了应用于DINOv2的课程学习。除了训练收敛的加速外,作者还发现这种数据课程意外地使模型偏向高频信息。
频率偏差与鲁棒性-精度权衡
鲁棒性研究通常采用频域视角来考察图像损坏与频谱的对应关系[37]。在自然图像中,低频分量占主导地位,承载大部分结构信息,因此高频损坏(如高斯噪声或快门噪声)主要破坏边缘等精细细节,而低频损坏(如对比度偏移、亮度变化或雾气)则改变更广泛的模式。近期研究探讨了将噪声建模为数据增强策略的一部分的必要性,以此证明使用此类损坏来提升下游鲁棒性的合理性[31]。不同的数据增强会引入频率偏差,从而增强对特定损坏的鲁棒性,但同时也暴露出不同的优势和劣势[8]。例如,高斯噪声增强能增强对高频扰动的鲁棒性,产生低频偏差的模型,但通常会导致对运动模糊或高斯模糊等中频失真的性能下降[37]。类似地,CutOut[10]增强通过遮盖图像区域来强调高频线索(如边缘或纹理),促使模型依赖易受噪声或模糊损坏的特征,从而限制鲁棒性提升。另一方面,对抗训练则使模型偏向低频特征,增强对某些扰动的抵抗力,但会损害对低频损坏的性能[38][6]。尽管这些增强具有特定优势,但它们往往通过优先考虑某些频段而牺牲其他频段,从而影响泛化能力。在本工作中,作者通过整合高斯噪声 Patch [20],将噪声应用于局部图像块,以平衡对高频损坏的鲁棒性与在干净图像上保持精度的能力。这种方法补充了作者数据课程的低频偏差,促进模型在整个频谱上的均衡发展,尽管需要仔细评估以减轻对中频损坏的潜在弱点。
3 FastDINOv2:快速鲁棒预训练的配方
本节介绍了所提出的课程学习流程。从宏观角度来看,该流程通过结构化的学习课程逐步引入高频特征。此外,将高斯噪声 Patch 纳入训练过程以增强鲁棒性。
3.1 低频特征提取

3.2 基于频率的课程学习
训练课程学习[5]通过先在简单样本上进行逐步训练,再推进到更复杂的样本,从而提升模型性能。在FastDINOv2中,作者将图像的低频分量——代表粗略的大规模模式——定义为较容易的样本,逐步过渡到由原始图像表示的更难样本。作者的课程由两个阶段组成。在前75%的训练周期内,模型仅在这些低频分量上进行训练。随后,作者通过重置Adam优化器的训练动态来应用重启机制。在第二阶段,作者在剩余周期内对包含低频和高频信息的原始图像训练DINOv2。为确保训练稳定性,作者在两个阶段中都保持固定的批处理大小。

4 实验
4.1 数据集与训练设置
数据集为加快实验进程,作者主要使用ImageNet-100 [32],它是ImageNet1K [27]的一个子集。训练集由ImageNet-1K中随机选取的100个类别组成,每个类别包含前500张图像。类似地,验证集包含原始验证集中相应的100个类别,每个类别包含50张图像。这总共产生了50,000张训练图像和5,000张验证图像。为进行鲁棒性评估,作者使用ImageNet-100-C,它源自ImageNet-C [17],用于评估模型对常见损坏的抵抗力。作者在所有损坏 Level 和类型中保持ImageNet-100验证集的图像选择完全一致。此外,作者使用ADE20K进行语义分割任务。最后,作者将方法扩展到完整的ImageNet-1K,并在ImageNet-C上评估鲁棒性。
ImageNet-100实验模型与训练细节
在ImageNet-100实验中,作者使用ViT-S/16作为DINOv2 Backbone 网络,总批大小为40,分布在4个GPU上(每个GPU 10个)。第一阶段训练中大型批大小的实验见附录A.1。作者采用插值位置嵌入来适应两个训练阶段之间的图像分辨率变化。应用不同嵌入大小的带或不带插值的位置嵌入的结果见附录A.2。作者训练 Baseline 模型500个epoch,训练课程实验200个epoch,确保 Baseline 收敛到最优性能。所有ImageNet-100实验使用固定的epoch长度为1250次迭代。对于ImageNet-1K实验,作者使用ViT-B/16,总批大小为512(每个GPU 128个),epoch长度为2500次迭代。 Baseline 和FastDINOv2在ImageNet-1K上的训练epoch分别为250和200。遵循官方DINOv2实现,作者使用基于批大小的平方根学习率缩放的AdamW优化器,得到基础学习率为7.9x10^-4。对于线性 Prob 评估,作者使用批大小为128,总迭代次数为12.5k。所有训练运行分布在4个L40S GPU上,评估使用A6000或A5500 GPU。
4.2 线性检测揭示快速收敛且不牺牲精度
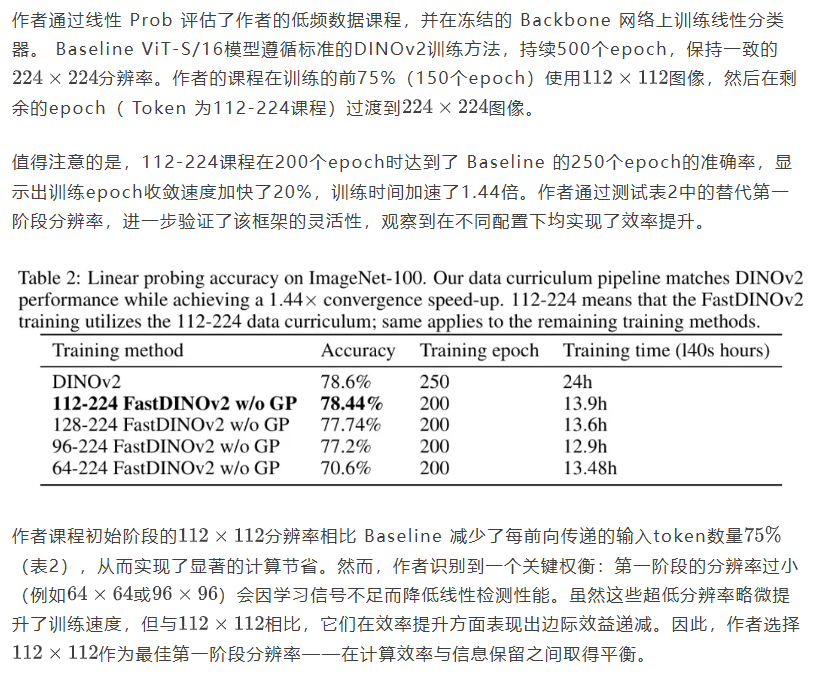
4.3 数据课程引发高频特征偏差
前文已分析课程设计及其训练加速效益,本节将研究低频数据课程对模型在常见损坏情况下的鲁棒性影响。以ImageNet-C作为损坏鲁棒性基准,作者通过保留ImageNet-100验证集中的相应类别和图像来构建ImageNet100-C。
作者的评估协议仅使用冻结主干网络的干净ImageNet-100验证数据训练线性分类器,然后在损坏的ImageNet-100-C图像上测试这些分类器。这确保了模型和分类器在训练过程中都不会遇到损坏数据。作者计算所有损坏类型和严重程度下的平均错误率,以量化鲁棒性。
在表3中,作者的课程训练模型相较于 Baseline 模型,对低频损坏表现出更强的鲁棒性,这表明它们在分类过程中更依赖于高频特征。这种现象的出现是因为在后期训练阶段的高频暴露迫使模型发展对这些组件的不变表示,从而增强了模型对高频损坏的敏感性。结果证实,作者的课程训练策略引入了高频偏差——这是该训练策略的一个有趣产物。
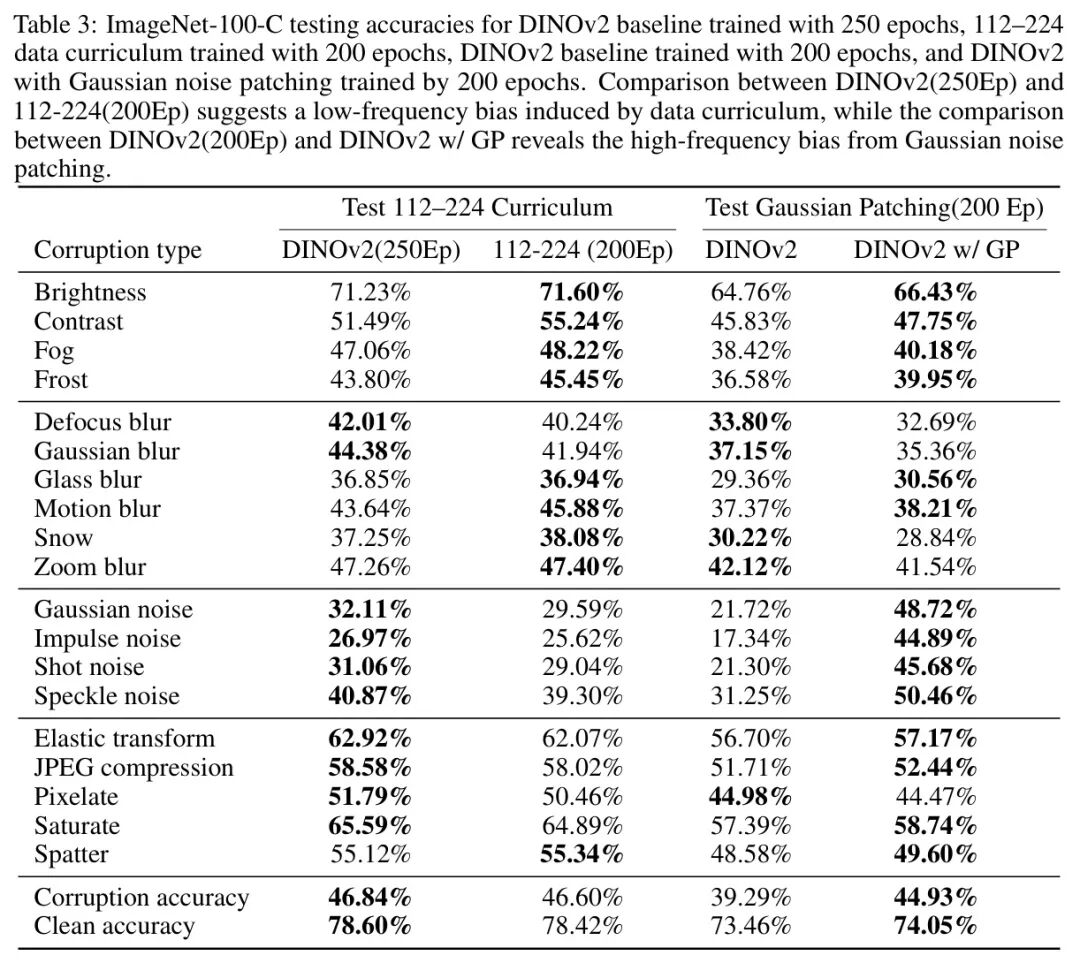
为了更好地解释这种鲁棒性的变化,作者根据其主导频率特征,按照傅里叶分析方法[37],将腐败类型在表3中进行分组。
-
• 低频污染:亮度、对比度、雾、霜
-
• 中频扰动:运动模糊、散焦模糊、玻璃模糊、高斯模糊、雪花、变焦模糊
-
• 高频失真:高斯噪声、脉冲噪声、散粒噪声、斑点噪声
-
• 混合效果:弹性变换、JPEG压缩、像素化、饱和度增强、泼溅效果
4.4 谱平衡:结合课程学习和噪声 Patch
基于训练课程中观察到的高频特征偏差,作者展示了高斯噪声 Patch 这种低频偏差增强方法如何抵消这种效应。重要的是,整合这些方法既能保留各自的优点,又能解决各自的局限性。
作者识别出高斯噪声增强[1]是一种引入低频偏差的方法,其通过增强对高频噪声污染的鲁棒性得到验证。然而,其直接应用由于过度强调低频而降低了清洁准确率。高斯噪声 Patch 通过在保留清洁区域的同时选择性地应用局部噪声注入来缓解这一问题,从而保持判别性特征学习。
当仅应用于课程的高分辨率阶段时,这种混合方法实现了均衡的鲁棒性提升。如表4所示,大多数损坏类型表现出增强的鲁棒性,仅出现轻微的减少,这些减少局限于特定的中频失真(例如,缩放模糊、弹性变换)和高频伪影(例如,像素化)。值得注意的是,组合方法消除了单独应用中观察到的冲突漏洞,与单独使用任何一种技术相比,显著提高了对散焦模糊和高斯模糊的鲁棒性。
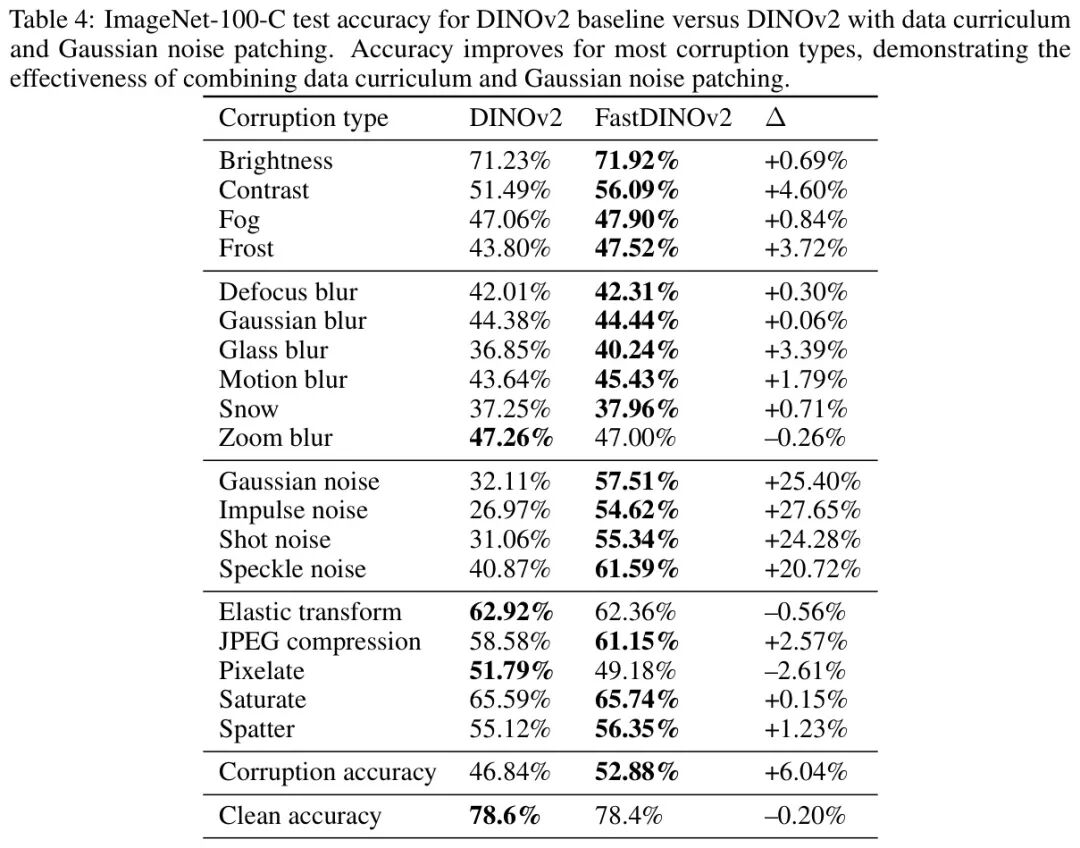
这种协同效应源于互补的频率交互:课程早期低分辨率训练构建了稳健的低频表示,而后续的高斯噪声块处理则减轻了对人工高频模式的过拟合。这种整合实现了频谱平衡,确保频率域不会过度主导特征编码。
这些发现强调了增强策略与课程阶段相匹配的重要性。尽管对于某些数据污染类型仍然存在权衡,但该框架为平衡频谱偏差同时保持核心模型性能提供了一种途径。
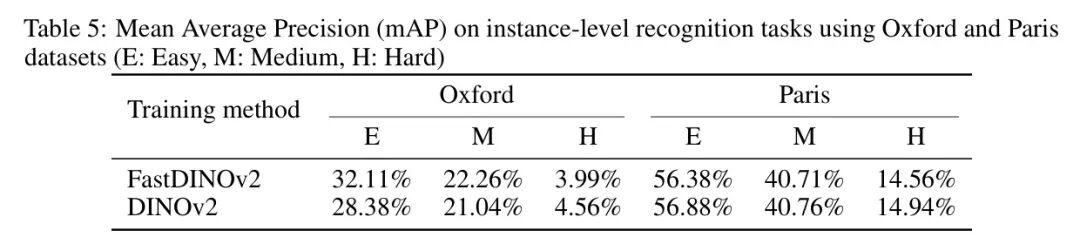
4.5 实例识别表明实例级有效性
基于线性 Prob 所展现的性能,作者进一步通过实例识别任务在实例级上评估FastDINOv2。具体而言,作者在牛津和巴黎数据集上评估了三个难度 Level ,并在表5中报告了平均精度均值(mAP)。在牛津数据集上,FastDINOv2在简单划分上比DINOv2提高了3.73%,在中等划分上提高了1.22%,但在困难划分上略有下降。在巴黎数据集上,两个模型的性能相当。这些结果表明,FastDINOv2不仅加速了收敛,而且在各种任务上提升了性能。
4.6 语义分割表明像素级性能完整无损
第4.2节和第4.5节表明FastDINOv2在保持线性 Prob 的同时实现了更快的收敛,并提升了实例识别精度,证明了图像和实例级任务依然具有优势。然而,由于语义分割需要细粒度的像素理解,作者需要验证FastDINOv2——该方法将训练时间的75%用于低频特征——是否仍能在此类任务上表现良好。为此,作者使用ADE20K进行了语义分割实验。作者冻结了使用作者课程训练的DINOv2主干网络,仅训练一个2层卷积解码器,并使用平均IoU(mIoU)和平均类别精度(mAcc)指标进行性能评估。表6表明,作者的112-224课程与高斯 Patch 匹配的分割性能(mIoU/mAcc)仅需200个epoch即可达到DINOv2 Baseline 的水平。尽管初始阶段进行了低频训练,第二阶段成功恢复了分割任务所需的细粒度像素理解能力。

4.7 基于频率的分析和Grad-CAM可视化解释
除了使用ImageNet-100-C和线性检测进行评估外,作者还探索了不同的训练范式是否会影响模型在所有频段中的误差敏感性——不仅限于ImageNet-100-C中的频段——以及模型在预测时优先考虑的区域。为此,作者根据[37]中的方法生成了Grad-CAM可视化[29]和傅里叶频谱 Heatmap 。
4.8 扩展到 ViT-B 和 ImageNet-1K:平衡效率与鲁棒性
为验证可扩展性,作者将框架扩展至ViT-B架构和ImageNet-1K预训练。基准DINOv2模型采用标准协议预训练200个周期,而作者的FastDINOv2方法结合112-224的渐进式训练策略,并在同等数量的周期内应用高斯噪声块处理——其中150个周期用于下采样输入,随后50个周期进行全分辨率训练。评估包括在干净ImageNet-1K验证数据上的线性 Prob 测试,以及使用冻结主干网络的ImageNet-C进行鲁棒性评估。
GPU内存消耗巨大是预训练扩展的关键 Bottleneck 。然而,在第一阶段使用低分辨率图像,FastDINOv2允许显著降低内存需求。如表7所示,在训练的前75%的epoch中,FastDINOv2在每GPU批处理大小为128时,最大内存消耗为9.47GB,显著低于相同批处理大小下DINOv2 Baseline 的33.5GB。这种内存需求的降低表明,在大部分预训练epoch中,可以利用内存容量较低的GPU来构建成本效益更高的模型。

5 局限性、未来工作和结论
在这项工作中,作者提出了一种针对视觉基础模型DINOv2的高效训练框架,展示了其在不同数据集和模型 Backbone 上的可扩展性和鲁棒性。FastDINOv2在训练效率、计算成本降低和模型性能方面取得了显著改进。然而,作者当前方法的一个局限性在于在训练周期的最后25%期间从低分辨率图像过渡到标准分辨率图像的固定时间表。虽然这一启发式方法在作者的实验中有效,但在不同的超参数设置或训练机制下可能并非最优。未来的工作将集中于开发自适应调度策略,这些策略能够根据收敛指标或验证性能等训练信号动态确定过渡点。此外,作者计划研究如何将作者的分辨率感知课程与其他训练增强方法(如对抗训练范式)相结合。
参考
[1]. FastDINOv2: Frequency Based Curriculum Learning Improves Robustness and Training Speed
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 4206
4206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









